2004 Archives
Btw, talking with .NET developers recently (XML geeks and non-geeks) about XQuery and XSLT support in .NET 2.0 I realized that shocking fact - about 80% of devs I was talking to still have no idea XQuery support in .NET 2.0 was cut. They were listening all the road to XQuery hype, they had that idea about how XQuery is better than XSLT in mind, they are working with XQuery implementation in .NET 2.0 Beta1, they are reading "What's New in System.Xml for Visual Studio 2005 and the .NET Framework 2.0 Release" and "XQuery and SQL Server XML Support in the .NET Framework" documentation at MSDN. Oh, apparently they don't read blogs!
Here is a nice one from today's xsl-list:
I'm working with the 2.0 beta of .NET and it has XQuery 1.0 support - you
are saying that it will not be supported? That sounds rather strange to me -
please explain.
Pieter Reint Siegers Kort
So we better be prepared for a wave of disappointed developers once Beta 2 is out. Blogging on that isn't enough, some official MSDN article is needed. People should be warned ASAP not to waste their time/money on that.
Another good news - Dave Remy, a Lead Program Manager on Core XML Technologies at Microsoft is blogging. Subscribed.
Hey, what a surprise from the W3C! XInclude 1.0 has been published as W3C Recommendation today. That was fast! Less than 3 months in Proposed Rec status - and here it is, XInclude 1.0 - another standard XML Core technology.
As usually very long post (an article actually) by Kurt Cagle on "The Business Case for XSLT 2.0". Explains why XSLT 2.0 is good and why Microsoft should implement it. With Michael Champion's comments, worth reading.
Hey, I've got another idea. XQuery and XSLT2 are surely huge undertakings (we can truly thank W3C for that), but still there is plenty of plain poor .NET devs struggling with limitations of XSLT 1.0 and XPath 1.0. What if Microsoft implements XSLT 1.1 + EXSLT in .NET 2.0, would you like to see it?
Some XML news in no any order:
- Irwin Dolobowsky says we should expect very interesting articles at MSDN XML Dev Center, especially I'm looking forward to this one - "Helena Kupkova will show us how to create bookmarks in XML Streams with the ResetableXmlReader." Hmmm, sweet. AFAIR we've been discussing it with my fellows XML MVPs, but concluded we need to rewrite XmlTextReader substantially to achieve it.
- Microsoft XML Team has a team blog now - subscribe here.
- Mike Champion nicely wraps up a discussion on the recent changes in thinking on the the next generation of Microsoft XML-related products. Convincing enough. What I still dislike is the lack of a consistency. A subset of XQuery (which is considered as stable enough) is still going to be supported in SQL Server 2005, but not in .NET. Weird, but you know, admit it - SQL Server team just can afford it.
Oh that big news - Michael Champion is now Program Manager for XML Standards in the Microsoft's XML WebData team. Wow, wow, wow - that's the only words I can say. Here is his intro on his new blog (hey, he is a Microsoft employee, so it's http://blogs.msdn.com/mikechampion, not http://weblogs.asp.net/mikechampion, but actually both URLs work). Subscribed.
The focus of my job at MS (as I understand it -- I'm still new!) is to help the WebData team track XML technologies and specifications as they emerge, mature, and are standardized, and to be a source for information needed to decide which specs to support in what timeframes.
I think we can translate that as "my job is to help Microsoft to avoid wasting resources on black hole projects in XML field", such as XmlDocument, XPathDocument,XmlDocument story or cut XQuery support in .NET2.0. Well, that's definitely going to benefit both Microsoft and us - ordinary .NET XML devs.
W3C at last published the "Architecture of the World Wide Web, Volume One" as W3C Recommendation. It was cooked in long hot discussions by Web heavyweights and geeks. Here is what's that about:
This document describes the properties we desire of the Web and the design choices that have been made to achieve them. It promotes the reuse of existing standards when suitable, and gives guidance on how to innovate in a manner consistent with Web architecture.
That's a must reading for all developers working with Web, XML and URIs. We can make the Web a better place by following principles, constraints and practices defined in that document.
I wonder if is there is something inherently wrong with XslTransform's class API? I was stunned again today reading this post in microsoft.public.dotnet.xml newsgroup:
I still don't see any way to create a XslTransform from a XmlDocument?
That's not the first time I see it actually. The answer of course is - XmlDocument implements IXPathNavigable, so just pass it to Load() method as is. Many developers don't see it, I wonder why?
I'd like to ask - do YOU think XslTransform class provide intuitive enough API (I mean these 5 overloads of Load() and 9 Transform() methods, not including obsolete ones)?
Kenny Kerr has posted another instalment in his amazing "Introduction to MSIL" blog series. It's about brilliant for-each construct, which was introduced by Visual Basic and now adopted by VB.NET, C#, C++ and even Java. Worth reading.
Besides I very like that idea of learning from blogs - you know, you just skim feeds, read what caught your attention - and learn new things. Oh, and what are these new things you learn - that depends on your interests of course!
That guy Loren Halvorson has relased XmlPreprocess tool for preprocessing XML files, e.g. config files in .NET. It allows to perform the following tricks:
<configuration>
<system.web>
<!-- ifdef ${production} -->
<!-- <compilation defaultLanguage="c#" debug="false"/> -->
<!-- else -->
<compilation defaultLanguage="c#" debug="true"/>
<!-- endif -->
</system.web>
</configuration>
As you can see he decided to embed preprocessing instructions into comments. Too bad. Why? First of all because comments are for comments and reusing a tool for a purpose it wasn't designed for is always bad idea. Second - surprise! XML has native syntax for expressing processing instructions - it's called processing instructions. And third - a much better way (at least comparatively to using comments and PIs) of mixing data with different meaning in XML is called XML namespaces.
Now back to our mundane world. Unfortunately in .NET one cannot embed elements in a proprietary namespace or even plain XML processing instructions into standard sections of config files! So using such poor hacks as embedding data into comments is the only workaround. Too bad. That's just another example of how violating a basic principle called "Allow All XML Syntax" makes your customers to invent poor hacks when they only want to extend your product.
I was doing some catch up reading feeds I'm subscribed and I found this one item that made me feeling some sort of bitter nostalgia. It's right on MSDN TV site, a new episode where Mark Fussel explains new XML features in upcoming .NET 2.0. The episode is dated December 02, but apparently it was filmed long time before. Why? Because more than a half new features Mark is talking about are officially cut and Mark himself has left XML team already.
Some goodies from Daniela Florescu and the Database Group at the University of Heidelberg:
- "The BEA Streaming XQuery Processor" (full version?), D. Florescu, C. Hillery, D. Kossmann, P. Lucas, F. Riccardi, T. Westmann, M.J. Carey, A. Sundararajan. VLDB Journal.
- "Implementing Memoization in a Streaming XQuery Processor", Y. Diao, D. Florescu, D. Kossmann, M.J. Carey, M.J. Franklin. Proceedings of the XML Symposium, Toronto, August 2004.
The rest is here.
This is amazing. Adam Kinney (Xamlon guy) runs his new blogsite on XSLT 2.0 (using Saxon.NET as XSLT engine):
Adam Kinney.com has been redesigned, restructured and refactored. The new site has been inspired by my hate fo comment spam, interest in XSLT 2.0, desire to lose SQL and move to XML, wanting to build more than just a blog (i.e. articles, art galleries, events) and my continually desire to build all my own tools over and over again.
As a matter of interest his site is rendered as both HTML and XAML - that reminds me that XSLT was actually designed exactly for such stuff.
[Via <XSLT:Blog/>]
Here is a really nice wrap up by Mike Kay on what benefits XSLT gets from using XML syntax:
I think the benefits are:
(a) many stylesheets consist of two-thirds data to be copied into the result
tree, and one-third instructions to extract data from the source document.
An XML-based syntax is beneficial for the two thirds that is data, because
it means the code in the stylesheet is a template for the final result. This
also facilitates a development approach that starts with graphical designers
producing a mock-up of the target HTML or XSL-FO page, and then handing it
over to a programmer to add the control logic. (XQuery has recognized this
by using an XML-like syntax for element constructors, but there's a lot of
difference between being XML-like and being XML.)
(b) XSLT inherits all the lexical apparatus of XML: entities, character
references, Unicode encoding, normalization of line endings and whitespace,
namespaces, base URI, and whatever the core WG dream up next. That means
there's only one set of rules for users to learn; it means there's a lot
less detail for the WG to reinvent and possibly get wrong; it means users
can take advantage of XML editing tools; and it gives implementors a head
start.
(c) It's surprisingly common, especially in large applications, to see
stylesheets being used as the input and/or output of a transformation. My
favourite example is an online banking system that had 400 screens each
generated by its own stylesheet, but all 400 stylesheets used a common
look-and-feel which was achieved by generating them from a master database
containing rules for all the different kinds of content that could be
encountered. It's not obvious how one would do that in XQuery: one could go
some way with a function library, but not nearly as far (especially without
polymorphic functions). (And since queries aren't XML, I can't even search
for all the queries that invoke a particular function, without a meta query
language!)
(d) One of the original arguments was that for client-side applications,
especially in small-footprint devices, only one parser would be needed
rather than two. However, I've no idea whether this argument stands the test
of time.
(e) XML vocabularies can be nested. We had no difficulty recently adding the
capability to have an inline schema within a stylesheet for describing its
working data, because XSLT and XML Schema are both defined in XML. Similarly
stylesheets can be embedded in other XML documents, for example in the
source document to which they apply, or in a pipeline processing language.
(f) One unpredicted benefit, I think, is that the XSLT syntax ends up being
more systematic, extensible, and robust. It's much easier to add another
attribute to an XSLT instruction than to extend the XQuery grammar, and it's
much easier for a compiler to catch all the syntax errors in one run.
Historically, a lot of the motivation for XSLT being in XML was the
experience of DSSSL, where the unfamiliar LISP-like syntax was widely
regarded in retrospect as the reason for the lack of take-up. It was
intended that XSLT should be writable by non-programmers, and I believe that
often happens. In fact I have heard it said that non-programmers have far
fewer conceptual problems with the language than JavaScript or SQL
programmers do.
And there is a misconception about XQueryX (XML syntax for XQuery). XQueryX isn't an alternative way to write XQuery queries using XML syntax (that way is called XSLT). It's more like formalized standard XML based AST format for XQuery processors. It's designed to be unconvenient to read and write by humans. It's just ridiculously wordy and low-level.
m.david starts his new project on Monday - sort of community XSLT learning using wonderful "Beginning XSLT" book by Jeni Tennison  Anyone and everyone is welcome to join in this effort to become better XSLT programmers. While I intend to do all I can to keep things moving forward throughout the course of this "adventure" there is no set schedule. I plan to submit two to three posts a day to act as food and fodder but by no means will these be the required focus. By utilizing the blog format it allows those who are not ready to move on the ability to stay where they're at, asking questions via comments and relying on answers from the community to help in better understanding that particular area of XSLT. This format also allows those who are ready to move ahead the ability to do so without feeling the need to wait for others to catch up. In many ways this will allow a relaxed, self-paced environment for you to jump in at any point and begin to better your XSLT programming skills. This also allows for those only interested to better their skills in certain aspects of the language the ability to jump in and out as they please. In the end we will hopefully have
created a nice reference for others to come along and utilize as well as ourselves to reference as needs be.
I wish I learn XSLT this way! I was climbing hard - reading XSLT/XPath specs first and then struggling with crappy Lotus XSL engine and only then I saw the light - Mike Kay's XSLT Bible. If you want to learn XSLT easy - join UnderstandingXSLT.com's "adventure", it's also free anyway. I'll be there and I'm sure Dimitre Novatchev will be there, right Dimitre?
It's worth to mention also that SyncRO Soft Ltd, the maker of the <oXygen/> XML Editor offers 15% discount on their products for UnderstandingXSLT community members. More details here.
I arrived at work and found 200+ new posts in xml-dev list. Lovely. XML is still extra hot topic. Here are some nice quotes:
For my money, XQuery is a heroic effort by a bunch of incredibly smart people which is crippled - we don't know how seriously - by its insistence on cohabiting with XSD.
Tim Bray
XSLT has an <xsl:copy> construct that does a shallow copy of an element node
together with all its namespaces (yes, you're right, I wouldn't expect
anyone to guess its specification by looking at the element name, any more
than I would expect anyone to guess what a left outer join operator does).
XQuery has no equivalent. My XQuery example used a computed element
constructor, which is the equivalent of <xsl:element> in XSLT: this isn't
copying any namespaces from the source document.
As another parallel thread notes, namespaces are responsible for a
ridiculous amount of the complexity in both these languages and the people
who invented them should be .... Any suggestions for a suitable punishment?
Michael Kay
As another non-obvious outcome of the recent browser war wave and the raise of Firefox browser is growing appreciation of XSLT as a useful client-side Web technology. That "An Introduction to Client-Side XSLT: It's Not Just for Server Geeks Anymore" article at digital-web.com is making me believe XSLT is finally coming to the client-side.
Another good news is that Mac's Safari browser is going to support XSLT via libxslt in the next release. Kudos!
C# Chat: The C# IDE
Have some questions about expansions, intellisense, or type colorization? Have some suggestions for or comments about refactoring support? Join the C# IDE team to discuss the past, present and future of the C# IDE.
December 2, 2004
1:00 - 2:00 P.M. Pacific time
Add to Calendar
They say Microsoft is about to unveil MSN Spaces blogging service, may be even this week:
Microsoft's MSN division is expected to take the wraps off its MSN Spaces blogging service this week, according to sources close to the company.
MSN is expected to tout MSN Spaces as a direct competitor to blog-creation and hosting tools, such as Blogger, Blog*Spot, LiveJournal and TypePad. Microsoft also will position MSN Spaces as a way to allow users to more easily share photo albums and music lists, too, insiders said.
Hey, and how would you like to post to your blog using MSN Messenger? I think it would be great, a really winnning idea. Much better than having a separate application, even such cool as my favorite w.bloggar. I doubt though I'll be able to use MSN Messenger to post to my MovableType-powered blog.
Sounds like all other MSN services like Hotmail and MyMSN are going to support RSS and blogging as well. At least that's how I get Dare's hints. I believe there will be no support for Atom as Microsoft traditionally uses RSS for its feeds.
Wow, I've heard about some hardware XML routers, but today I saw an ad banner about hardware XSLT accelerator. Holy cow! Here is some marketing blah-bkah-blah:

Standards based XSLT processing is computationally intensive -
it overburdens the server infrastructure resulting in poor user experience,
high server infrastructure costs and scalability limitations. By delivering
order of magnitude or better acceleration for XSLT processing - the XML
Speedway significantly reduces the infrastructure costs, improves scalability
and availability of the total solution. The XML Speedway
provides this world-class performance through Sarvega's
acclaimed highly optimized XESOS™ technology. Further,
through XML Compression, end-to-end response time is
improved regardless of location or network connection.
And here is some meat:
XML Speedway can be deployed in a
reverse-proxy in-line and server-assist modes with JaxP
and C++ API. Flexibility extends to the variety of means
available to de-reference XSL stylesheets, enable
pipelined transformations, provides built-in support for
various XSLT engines, XSLT and XML Schema caching
and the ability to concurrently offload disparate backend
applications with their own sets of transformations.
And what this box can do:
Wire Speed XSLT Processing:
• XSLT transformation, XML Schema validation,
XML/SOAP Routing
• XSLT 1.0, XML Schema 1.0, XPath 1.0,
SOAP 1.1, SOAP 1.2
• Compression, XSLT/XML/Schema
caching, MIME support, URL rewriting
• Support for non-XML content
Not bad. They say FOXSports.com is already using it. I wonder where is the price list.
PS. Hey, that's Sarvega company - once they wanted to hire me, now I see why :)
Elliotte Rusty Harold has started a new site called (not surprisingly) "The Cafes" - for articles "longer than a typical Cafe con Leche news item, but much shorter than a full book". Here is the RSS feed. Subscribed.
Sriram Krishnan asks strange question:
I see someone flaming someone else for not being XHTML compliant. Tim Bray - if you're reading this, I want to know something. Why is XML case-sensitive? No human-being ever thinks in case-sensitive terms. A is a. End of story. So now, I have a situation where writing <html> </HTML> wouldn't be XHTML compliant. And what do I get out of XHTML apart from geek-bragging rights and this strange idea of 'standards-compliance'? Does it give me more freedom? Does it help my viewers? My customers?
Well, this guy is definitely heavily sloppy-HTML-contaminated. What? <html> </HTML> isn't XHTML complaint? Thanks GOD! Anyway, Tim Bray does answer his question:
XML markup is case-sensitive because the cost of monocasing in Unicode is horrible, horrible, horrible. Go look at the source code in your local java or .Net library.
Also, not only is it expensive, it's just weird. The upper-case of e' is different in France and Quebec, and the lower-case of 'I' is different here and in Turkey.
XML was monocase until quite late in its design, when we ran across this ugliness. I had a Java-language processor called Lark - the world's first - and when XML went case-sensitive, I got a factor of three performance improvement, it was all being spent in toLowerCase(). -Tim
Nice.
Scoble says "MSN is XHTML". Well, not really msn.com, but MSN search (beta version) - beta.search.msn.com. Good news anyway.
Here is what I learnt from Jackie Goldstein's talk on .NET Worst Practices at the .Net Deep Dive conference in Tel-Aviv last Thursday. There is a subtle, but hugely important difference between how .NET and Java re-throw a caught exception and I missed that somehow when been learning .NET. Not that I didn't know what "throw;" does in C#, I was mistaken about what "throw ex;" does!
In Java, when you do "throw ex;", ex is being re-thrown as if it wasn't caught at all - no informantion about re-throwing is ever recorded and original stack trace info is preserved. If you do want to start exception's stack trace from the re-throwing point - oh, that's completely different story, you need to refill exception's stack trace using fillInStackTrace() method.
In .Net however, when you do "throw ex;", ex is being re-thrown, but the original stack trace info gets overriden. The point where exception is re-thrown is now becoming the exception's origin. Here is what I mean. If you do follow your Java habits and write
using System;
public class MyApp
{
public static void F()
{
throw new NotImplementedException("Too lazy to implement!");
}
public static void Main()
{
try
{
F();
}
catch (Exception e)
{
Console.WriteLine("Exception {0} has occured!", e.GetType());
throw e; //Line 18
}
}
}
you'll get:
Exception System.NotImplementedException has occured!
Unhandled Exception: System.NotImplementedException: Too lazy to implement!
at MyApp.Main() in d:\projects\test\class2.cs:line 18
See, you've lost the original exceptions's stack trace and now you gonna have really hard time to figure out what was wrong actually, where the exception was thrown at the first place.
So in .NET you have to use "throw" keyword ("Throw" in VB.NET) with no argument to perform a pure re-throwing of an exception - change the line 18 to just "throw;" and the result will be
Exception System.NotImplementedException has occured!
Unhandled Exception: System.NotImplementedException: Too lazy to implement!
at MyApp.F() in d:\projects\test\class2.cs:line 6
at MyApp.Main() in d:\projects\test\class2.cs:line 18
Now you can see the full exception stack trace.
Basically MSIL (CIL) has two instructions - "throw" and "rethrow" and guess what - C#'s "throw ex;" gets compiled into MSIL's "throw" and C#'s "throw;" - into MSIL "rethrow"! Basically I can see the reason why "throw ex" overrides the stack trace, that's quite intuitive if you think about it for a moment. But "throw" syntax for "rethrow" instruction is not really intuitive. It smells stack based MSIL, which is obviously under the cover, but actually should be kept there. I guess they wanted to keep number of C# keywords small, that's the reason. So you just better know this stuff - use "throw;" to re-throw an exception in .NET.
Hey, that's cool stuff - check it out. Apparently, O'Reilly have found new way to sell more books. It's a sort of modern version of the "X for complete idiots" series - actually they call it "Head First". The main idea as far as I understand is to set out material in a form of a story abundantly filled with fun weird (while in fact attention-grabbing) images (which are more memorable than words). Here is an official description:
If you've read a Head First book, you know what to expect--a visually-rich format designed for the way your brain works. Using the latest research in neurobiology, cognitive science, and learning theory, Head First Design Patterns will load patterns into your brain in a way that sticks. In a way that lets you put them to work immediately. In a way that makes you better at solving software design problems, and better at speaking the language of patterns with others on your team.
Hmmm, neurobiology... loads directly into my brain... I'm not sure if I like it actually. We need some brain-access security here!
Anyway that looks pretty interesting. There are only four books in "Head First" series published already - on servlets/JSP, Java, EJB and Design Patterns. All Java-oriented, but that last one:

is an universal of course, so I just ordered it. Check out sample chapters, especially this one - they are awesome.
PS. Oh, and I think Rory should sue O'Reilly for stealing his idea of presenting tech info along with weird images mixed with hand-written text.
BTW, as nicely pointed out by Michael Kay, XML document with no XML declaration, in encoding other than UTF-8 or UTF-16 is not necessarily malformed! In fact XML spec allows encoding information to be provided externally (e.g. via Content-type HTTP header).
Well, it's not about USA elections. It's about elections in Ukraine, the country where I was born and grew up. The president elections were just terrible. Calling them fraudulent is saying nothing, they ware super-fraudulent. Violence, intimidation, abuse of state resources in favor of the prime minister, frauds such as "in some areas 5 percent of voters had been added to the lists on voting day, many of them with certificates allowing them to vote away from their place of residence.". My friends and relatives in Ukraine confirm all that, basically from my experience there is no doubt it's all true. Ukraine is still far from democracy. A prime minister can spend lots of state's budget and organize a fraud campaign just to be elected as a president. And what's funny, everybody knows it. That's a normal practice in ex-USSR states. And that's terrible. Russian's observers are happy and called the elections open and honest. Russian's president sent his congratulations to the ukraininan prime minister even before the official election results were published! All western observers called the elections a farce and all western governments refuse to recognize the results. What a mess!
Oh, well, I left that country 5 years ago... No regrets.
There was recently an interesting thread in the microsoft.public.dotnet.xml newsgroup on document("") function call in .NET. A guy was porting some app from using MSXML to .NET. Something didn't work... You know these common bitter (and usually completely lame) complaints:
It is strange, this all works just fine using MSXML4 objects instead of XML.NET
I guess between the implementation of MSXML4 and XML.NET they forgot the
purpose of the special case document('').
...
W3C spec or not, it is too bad that XML.NET is intrinsically tied to the
file system. My program has access neither to write nor read from the file
system. I guess I will use MSXML4.
So what's wrong with document("") in .NET comparatively to MSXML?
M. David Peterson, coordinator of the x2x2x.org community open-source project (known by the Saxon.NET, AspectXML, and xameleon projects) started a blog at xsltblog.com. The blog's description is "An ongoing weblog of current topics from the XSLT development community & other XML/XSLT related news items. Hosted, maintained, & edited by M. David Peterson.". Subscribed.
Just for the record: I updated EXSLT.NET to support for omit-xml-declaration attribute on the exsl:document element. If somebody desperately needs it, it's in the source repository already.
TopXML launched XML News Reblogger service. It's basically XML blogs and news aggregator, similar to the Planet XMLhack. They aggregate selected XML-related news feeds and blogs (127 currently, including mine :) twice a day and provide a way to read all that jazz on their web site. They don't provide aggregated RSS feed currently, but as Sonu Kapoor (the guy who wrote the Reblogger) informed me, that's definitely just a matter of time.
Amazing new essay by Norman Walsh on XML 2.0. Worth reading and contemplating. The crux is "simplification". XML is too complex, who knew it six years ago :)
Here are some 5-years old news:
http://www.w3.org/ -- 16 November 1999 -- The World Wide Web Consortium (W3C) today releases two specifications, XSL Transformations (XSLT) and XML Path Language (XPath), as W3C Recommendations. These new specifications represent cross-industry and expert community agreement on technologies that will enable the transformation and styled presentation of XML documents. A W3C Recommendation indicates that a specification is stable, contributes to Web interoperability, and has been reviewed by the W3C membership, who favor its adoption by the industry.
"Anyone using XML can now take advantage of XSLT, a powerful new tool for manipulating, converting or styling documents," declared Tim Berners-Lee, W3C Director. "XPath adds a simple way of referring to parts of an XML document. Together, they strike a fine balance between simplicity of use and underlying power."
Happy birthday to XSLT and XPath and congratulations to James Clark and Steve DeRose, editors of these the best so far XML applications.
Breaking news from Altova GmbH (maker of famous XML Spy IDE):
Altova has compiled a collection of free tools and technical resources to help develop solutions for today's business challenges.
That includes:
Altova XSLT 1.0 and 2.0 Engines, Altova XQuery Engine, XMLSpy® 2005 Home Edition, Authentic® 2005. All Windows-only apparently.
XSLT and XQuery ones are the new and the most interesting. Altova XSLT 1.0 engine is well-known XSLT engine used when debugging XSLT within XML Spy, now they just release it as a free (but not open-source of course) standalone utility (Windows 2000/XP/2003 command line executable), "suitable for use in both client- and server-side application development". Altova XSLT 2.0 engine is a similar utility, which claims to implement November 2003 XSLT 2.0 working draft. It's schema-unaware processor and doesn't support user defined types and validation. Some functions and elements aren't supported either (yet?).
Altova XQuery Engine is also available as free command line Windows 2000/XP/2003 exe, which implements July 2004 XQuery 1.0 working draft. The same here - no support for schema importing, validation and user-defined types. No support for static type checking, external functions, character normalization either. XQuery library modules are supported though. More info about limitations here.
The tools are available "for you to use both for your own purposes and to integrate into your solutions without paying any royalties or license fees." The license: Altova XSLT/XQuery Engine developer license agreement.
Sounds awesome. I just downloaded the tools, but didn't give them a whirl yet. I wonder why there is no support for schema, actually XML Spy has a very decent schema processor for years now. Hmmm, very cool tools anyway.
Well, that's just a simple level 100 quiz aiming to imprint "standard random number generators are not really random" program to those who still lack it.
What will produce the following C# snippet?
System.Random rnd = new System.Random(12345);
System.Random rnd2 = new System.Random(12345);
for (int i=0; i<1000; i++)
if (rnd.Next() != rnd2.Next())
Console.WriteLine("Truly random!");
I got a problem. It's .NET problem. In XInclude.NET I'm fetching resources by URI using WebRequest/WebResponse classes. Everything seems to be working fine, the only problem is as follows: when the URI is file system URI, the content type property is always "application/octet-stream". Looks like it's hardcoded in System.Net.FileWebResponse class (sic!). I mean - when I open Windows Explorer the file's properties are: "Type of the file: XML File" and "Opens with: XMLSPY". So the Windows definitely knows it's XML and in the registry I can see .xml file extension is associated with "text/xml" content type, so why FileWebResponse always says "application/octet-stream"? Am I doing something wrong or it's soo limited in that matter? Any workarounds?
W3C has published fresh working drafts for XQuery/XPath/XSLT. XQuery 1.0: An XML Query Language, XML Path Language (XPath) 2.0, XQuery 1.0 and XPath 2.0 Data Model, XQuery 1.0 and XPath 2.0 Functions and Operators, XSLT 2.0 and XQuery 1.0 Serialization. These address comments received on previous drafts.
XQuery 1.0. What's new:
This working draft includes a number of changes made in response to comments received during the Last Call period that ended on Feb. 15, 2004. The working group is continuing to process these comments, and additional changes are expected. This document reflects decisions taken up to and including the face-to-face meeting in Redmond, WA during the week of August 23, 2004. These decisions are recorded in the Last Call issues list (http://www.w3.org/2004/10/xquery-issues.html). Some of these decisions may not yet have been made in this document. A list of changes introduced by this draft can be found in I Revision Log. The
Note:
A proposal that is currently under discussion would introduce a new form of type promotion, similar to numeric type promotion. Under this proposal, values of type xs:anyURI would be promotable to the type xs:string and could therefore be passed to functions such as fn:substring. One problem with this proposal is that values of type xs:anyURI are compared on a code-point basis, whereas values of type xs:string are compared using a collation. For this reason, promotion of xs:anyURI to xs:string might cause value comparison operators such as eq and gt to lose their transitive property. This proposal is pending further discussion and is not reflected in this document. However, the signatures of certain functions in [XQuery 1.0 and XPath 2.0 Functions and Operators], such as fn:doc and fn:QName, were written with the expectation that xs:anyURI would be promotable to xs:string. The signatures of these functions may change when this issue is resolved.
Still evolving, still too far from RTM...
From the Microsoft Research:
Comega is an experimental language which extends C# with new constructs for relational and semi-structured data access and asynchronous concurrency.
Cw is an extension of C# in two areas:
- A control flow extension for asynchronous wide-area concurrency (formerly known as Polyphonic C#).
- A data type extension for XML and table manipulation (formerly known as Xen and as X#).
The preview download includes Cw command line compiler, Visual Studio .NET 2003 package which extends VS.NET ti support Cw (really nice integration) and lots of samples. Cw supports XML as native data type, so you can write something like
// This class returns the sample bib.xml data as the above Comega objects.
public class BibData
{
public static bib GetData() {
return <bib>
<book year="1994">
<title>TCP/IP Illustrated</title>
<author><last>Stevens</last><first>W.</first></author>
<publisher>Addison-Wesley</publisher>
<price> 65.95</price>
</book>
</bib>;
}
}
And what's more interesting - Cw partially supports XQuery-like constructs natively:
public static results RunQuery(prices ps)
{
return <results>{
foreach(t in distinct(ps.book.title))
{
yield return
<minprice title="{t}">
<price>{Min(ps.book[it.title == t].price)}</price>
</minprice>;
}
}</results>;
}
Online documentation is available here.
I wish I had some spare time to play with it...
Jirka Kosek has announced a tool (XSLT stylesheet actually) for converting XSL-FO documents to WordML. Get it at http://fo2wordml.sourceforge.net.
XML Base is a tiny W3C Recommendation, just couple of pages. It facilitates defining base URIs for parts of XML documents via semantically predefined xml:base attribute (similar to that of HTML BASE element). It's XML Core spec, standing in one line with "Namespaces in XML" and XML InfoSet. Published back in 2001. Small, simple, no strings attached or added mind-boggling complexity. Still unfortunately neither MSXML nor System.Xml of .NET support it (Dare Obasanjo wrote once on the reasons and plans to implement it). Instead, XmlResolver is the facility to manipulate with URIs. But while XmlResolvers are powerful technique for resolving URIs, they are procedural facility - one has to write a custom resolver to implement resolving per se, while XML Base is a declarative facility - one just has to add xml:base attribute on some element and that's it, base URI for this element and the subtree is changed. So now that you see how it's useful, here is small how-to introducing amazingly simple way to implement XML Base for .NET.
I missed that point somehow:
The trouble is that XSLT allows regions of a stylesheet to belong
to different versions. In XSLT 1.0, you can put an xsl:version
attribute on any literal result element to indicate the version of
XSLT used in the content of that element. In XSLT 2.0, any XSLT
element can have a version attribute, and any other element can
have a xsl:version attribute that does the same thing.
The rationale is that it allows you to upgrade part of your stylesheet
without having to upgrade all of it. The parts of an XSLT 2.0
stylesheet that are marked as XSLT 1.0 run under
backwards-compatibility mode, which means that (in general) things
work as they did under XSLT 1.0 (e.g. you have weak typing, first-item
semantics, numeric comparisons). This is handy if you have a big XSLT
1.0 stylesheet, and you want a little bit of XSLT 2.0 functionality
but don't want to upgrade the entire thing just now.
Jeni Tennison in xsl-list.
It can be quite useful when upgrading stylesheets step by step, but I don't think such mix is useful otherwise provided huge difference in XPath 1.0 and XPath 2.0 data models and XSLT 1.0 and XSLT 2.0 behaviours (even in backwards compatible mode). And it's a disaster for anyone impementing XSLT 2.0 from scratch. Now I wonder how are we going to implement this feature in the XQP project?
XmlTextWriter in .NET 1.X only supports indentation of the following node types: DocumentType, Element, Comment, ProcessingInstruction, and CDATA. No attributes. So how to get attributes indented anyway? If you can - wait .NET 2.0 with cool XmlWriterSettings.NewLineOnAttributes, otherwise - here is a hack how to get attributes indented with XmlTextWriter in .NET 1.X.
DonXML writes on viral coding examples in presentations on using XML in .NET:
Joe Fawcett (fellow XML MVP) came across a great example (from the Microsoft.Public.Xml newsgroup) of one of my biggest pet peeves, "We (the community) are doing a very poor job teaching the average developer how to use XML properly in .Net".
I want to draw your attention to a line from the original post:
"So, is it possible to directly modify the xml file instead of using the dataset."
And the first response was:
"you can do it using Data Island"
Why does thing question bug me so much? Because we (the community) have done a very bad job using XML correctly in our articles and presentations.
Yeah, samples are in fact templates, a stuff to copy-n-paste. Keep that om mind while preparing samples for your presentation/article/blog.
Karl Waclawek has announced the first production release of the SAX for .NET library - open source C#/.NET port of the SAX API. It contains API and Expat-based implementation. AElfred-based implementation is expected soon.
"An Introduction to "WinFS" OPath" article by Thomas Rizzo and Sean Grimaldi has been published at MSDN. Summary:
WinFS introduces a query language that supports searching the information stored in WinFS called WinFS OPath. WinFS OPath combines the best of the SQL language with the best of XML style languages and the best of CLR programming.
Necessary update:
In spite of what may be stated in this content, "WinFS" is not a feature that will come with the Longhorn operating system. However, "WinFS" will be available on the Windows platform at some future date, which is why this article continues to be provided for your information.
Yeah, I know it's an old problem and all are tired of this one, but it's still newsgroups' hit. Sometimes XSLT is the off-shelf solution (not really perf-friendly though), but <xsl:output indent="yes"/> is just ignored in MSXML. In .NET one can leverage XmlTextWriter's formatting capabilities, but what in MSXML? Well, as apparently many forgot MSXML implements SAX2 and includes MXXMLWriter class, which implements XML pretty-printing and is also SAX ContentHandler, so can handle SAXXMLReader's events. That's all needed to pretty-print XML document in a pretty streaming way:
<html>
<head>
<title>MXXMLWriter sample.</title>
<script type="text/javascript">
var reader = new ActiveXObject("Msxml2.SAXXMLReader.4.0");
var writer = new ActiveXObject("Msxml2.MXXMLWriter.4.0");
writer.indent = true;
writer.standalone = true;
reader.contentHandler = writer;
reader.putProperty("http://xml.org/sax/properties/lexical-handler", writer);
reader.parseURL("source.xml");
alert(writer.output);
</script>
</head>
<body>
<p>MXXMLWriter sample.</p>
</body>
</html>
MSDN has published "The XML Litmus Test - Understanding When and Why to Use XML" article by Dare Obasanjo. Cool and useful stuff. But an example of inappropriate XML usage I believe is chosen quite poorly - in such kind of articles samples must be clear and clean, while sample of using XML as a syntax for programming languages is rather debatable and dubious. Sure, o:XML syntax is terrible, but there is another highly succesful for years now programming language, whose syntax is pure XML and which was created in just one year and which just rocks. After all choosing non-XML syntax for XML-processing language is not a trivial decision too and in a recent wave of the "Why *is* XQuery taking so long?" permathread in the xml-dev it was clearly stated that one of the reasons XQuery is being developed so many years was the complexity brought by the choice of a non-XML syntax:
2. Syntax issues. The mix of an XML syntax for construction with a
keyword syntax for operations is intuitive for users, but has required a
lot of work on the grammar side.
Jonathan Robie, http://lists.xml.org/archives/xml-dev/200410/msg00129.html
That's sort of news that make my day - Derek Denny-Brown is finally blogging. Derek is working on XML/SGML last 9 years and currently is dev lead for both MSXML & System.Xml.
Here is his atom feed if you can't find it on that dark-colored page. Subscribed.
[Via Dare]
Ok, last one:
Consider a function which, for a given whole number n,
returns the number of ones required when writing out all numbers
between 0 and n. For example, f(13) = 6. Notice that f(1) = 1.
What is the next largest n such that f(n) = n?
Again I failed to solve it with no help from my old good Pentium :( I came up with some sort of formula, which I believe is right, but the number seemed to be quite big, so... 5-lines of code solved it. Can anybody show how it can be deducted in mind?
PS. Oh, forgot to mention - the puzzles were taken from the GLAT.
Interesting news from Microsoft Research:
The F# compiler is an implementation of an ML programming language for .NET. F# is essentially an implementation of the core of the OCaml programming language (see http://caml.inria.fr). F#/OCaml/ML are mixed functional-imperative programming languages which are excellent for medium-advanced programmers and for teaching. In addition, you can access hundreds of .NET libraries using F#, and the F# code you write can be accessed from C# and other .NET languages.
Find more on F# homepage.
And what about this one:
1
1 1
2 1
1 2 1 1
1 1 1 2 2 1
What is the next line?
I found several solutions, one better and couple of not really, but all of them don't match another property this sequence looks like to be following. Hmmm.
RenderX has released new major version of their famous XSL-FO Formatter - XEP 4.0, "with many more features and performance improvements".
The engine supports the XSL Formatting Objects (XSL FO) Recommendation
and the Scalable Vector Graphics (SVG) Recommendation for uniform,
powerful, industry standard representation of source documents. XEP
renders multi-media content in Adobe's Portable Document Format (PDF)
and Adobe Postscript, the de-facto standards for digital typography. It
conforms to Extensible Stylesheet Language (XSL) Version 1.0, a W3C
recommendation. It also supports a subset of the Scalable Vector Graphics
(SVG) 1.1 Specification. XEP outputs formatted documents in Adobe's
PDF version 1.3 (with optional support for features from new versions)
and PostScript level 2 or 3 formats.
Dare writes about "Upcoming Changes to System.Xml in .NET Framework 2.0 Beta 2". In short:
- No XQuery (only in SQL Server 2005 aka Yukon)
- New - push model XML Schema valiadtor - XmlSchemaValidator.
- XPathDocument is reverted the XPathDocument to what it was in version 1.1 of the .NET Framework.
- XmlReader - added methods for reading large streams of text or binary data embedded in an XML document in a streaming fashion.
- The XPathEditableNavigator has been merged into the XPathNavigator, making it an editable XML cursor model API.
- XmlDocument can be edited via new editable XPathNavigator, XPathDocument - no.
- XmlDocument now supports in-memory validation.
- XslTransform is obsolete, XslCompiledTransform is the replacement.
- XslCompiledTransform compiles XSLT to MSIL for best perf and implements MSXML4 extension functions.
- XPathExpression has a static method to compile XPath expressions.
- XmlArgumentList is removed - stick with XsltArgumentList.
The question raised in the microsoft.public.dotnet.xml newsgroup today: "How to retrieve the namespace collection of all the document namespaces for which there is at least one element in the document". The purpose is a validation against different schemas. Well, the most effective way of doing it is during XML document reading phase, not after that. In .NET it means to add a slim layer into XML reading stack (aka SAX filter in Java world). In this layer, which is just custom class extending XmlTextReader, one can have a handler for an element start tag, whose only duty is to collect element's namepace and delegate the real work for the base XmlTextReader. Here is how easy it can be implemented.
public class NamespaceCollectingXmlReader : XmlTextReader
{
private Hashtable namespaces = new Hashtable();
//Add constructors as needed
public NamespaceCollectingXmlReader(string url) : base(url) {}
public Hashtable CollectedNamespaces
{
get { return namespaces; }
}
public override bool Read()
{
bool baseRead = base.Read();
if (base.NodeType == XmlNodeType.Element &&
base.NamespaceURI != "" &&
!namespaces.ContainsKey(base.NamespaceURI))
namespaces.Add(base.NamespaceURI, "");
return baseRead;
}
}
And here is how it can be used to collect namespaces while loading XML into a XmlDocument.
XmlDocument doc = new XmlDocument();
NamespaceCollectingXmlReader ncr = new NamespaceCollectingXmlReader("foo.xml");
doc.Load(ncr);
foreach (object ns in ncr.CollectedNamespaces.Keys)
Console.WriteLine(ns);
Here is another cool puzzle from google:
Solve this cryptic equation, realizing of course that values
for M and E could be interchanged. No leading zeros are allowed.
WWWDOT - GOOGLE = DOTCOM
Should admit I failed to solve it with just a pen and a piece of paper. Or I'm stupid or was too busy, but I wrote a small C# program in just two minutes and my computer cracked it down in another couple of minutes by a brute force. Viva computers - no brains are needed anymore :)
Oh boy, I just realized my blog is aggregated by the Planet XMLhack. Wow. Thanks for that. Must stop writing narrow-minded rubbish and start focusing on XML hacking.
While old gray XPath 1.0 supports only DTD-determined IDs, XPointer Framework also supports schema-determined IDs - an element in XML document can be identified by a value of an attribute or even child element, whose type is xs:ID. I've been implementing support for schema-determined IDs for the XPointer.NET/XInclude.NET library (has no online presence currently after gotdotnet's workspace crashed and I moved the code to the mvp-xml.sf.net).
I was using my old hack - custom XmlReader that emulates dummy DOCTYPE to enforce .NET's System.Xml (both XmlDocument and XPathDocument) to use ID info collected from a schema. But you know, as it turned out, that hack is quite limited - System.Xml is only recognizing ID attributes (not elements) and only for globally defined elements! Oh. Looks like that piece of code in System.Xml was designed only for DTDs, where all elements are globally defined and it works for schemas too only due to the unified implementation in System.Xml.Schema. Ok, so XPointer.NET's support for schema-determined IDs is going to be rather limited - only ID typed attributes and only for gloablly defined elements.
Dan Wahlin, author of the "XML for ASP.NET Developers" book and xmlforasp.net portal, Microsoft MVP for XML Web Services, etc, is finally blogging. Really better late than never.
Steve Ball announced XSLT Standard Library version 1.2.1 - an open source, pure XSLT (extensions free) collection of commonly-used templates. New stuff includes new SVG and comparison modules and new functions in string, date-time and math modules.
Mark Fussell:
In between re-writing and updating the chapters for the beta version of the my book A First Look at ADO.NET and System.Xml V2.0, I found some time to write an article on Building Custom XmlResolvers for MSDN.
It's really good artilce, highly recommended reading for those who still don't feel the magic power of XmlResolvers.
Edd Dumbill has announced planet.xmlhack.com - aggregating weblogs of the XML developer community. The weblogs are chosen to have a reasonable technical content, but
because this is as much about the community as it is about the tech,
expect the usual personal ramblings and digressions as well. In short,
Planet XMLhack's for you if you enjoy being around people from the XML
community.
Aggregated blogs at the moment include:
The RSS is - http://planet.xmlhack.com/index.rdf. Subscribed.
Well, here are some clarifications on how to join XQP project. You have to be registered at the SourceForge.net (here is where you can get new user accout) and then send some free-worded request along with SourceForge user name to me. That's it. Oh, and subscribe to the xqp-development mail list - that's the meeting place (actually you don't have to be XQP team member to subscribe - it's an open list).
W3C published XInclude 1.0 Proposed Recommendation. Now it's only one step left for XInclude to become W3C Recommendation.
That's what I call "just in time"! I just finished integrating XInclude.NET into the Mvp-Xml codebase, cleaning up the code and optimizing it using great goodies of Mvp-Xml such as XPathCache, XPathNavigatorReader etc and planned to align the code with recent XInclude CR - and here goes another spec refresh. As far as I can see, there is no new stuff or syntax changes, just editorials (such as mentioning XML 1.1 along with XML 1.0) and clarifications based on previous feedback. Comments are due to 29 October 2004. I expect to release renowned XInclude.NET next week.
PS. For those unfamiliar with XInclude - "Combining XML Documents with XInclude" MSDN article waits for you.
Well, I was talking about it a lot and finally decided to stop rambling and start doing. Here is my new toy: XQP project. XQP stands for XML Query Processor of course. It's going (if my karma is good enough) to be free open-source XPath2.0/XQuery1.0/XSLT2.0 engine for the .NET platform. SourceForge team kindly approved the project and now we have everything to deliver a killer application!
The main idea behind XQP is to develop a single core runtime engine based on XPath2.0/XQuery1.0 algebra and then to provide XPath 2.0, XQuery 1.0 and XSLT 2.0 compilers for that engine. It's not something brand new of course. Saxon implements both XSLT 2.0, XPath 1.0 and XQuery 1.0 with a single engine. Microsoft went even further ineventing Common Query Runtime (CQR) and common intermediate format (QIL) and implementing its bits in Whidbey as System.Xml.Query. I believe that's a mainstream design pattern, very obvious considering the XPath/XQuery intimacy and XQuery/XSLT functional overlap.
There are some issues I'd like to be clear.
What for? Why not to wait .NET 2.0?
Well, it was announced that System.Xml v2.0 won't support neither XSLT 2.0 nor XPath 2.0. Being XSLT and .NET aficionado I can't imagine the situation when Java has XSLT 2.0 and .NET doesn't. If Microsoft can't deliver it - we can do it.
What's wrong with Saxon.NET?
Well, nothing wrong, cool project. I just don't believe in effective porting of any big system. Saxon is too tied to Java. And after all porting is so boooooring, while I enjoy to develop :)
Why new project?
I considered starting XQP as part of Mvp-Xml project or even Mono, but realized that due to experimental nature of the project I want to rule the it by myself.
Isn't it too huge project?
Well, I'm not afraid of it. I was participating in developing two XSLT 1.0 processors (a commercial one and an open-source one) and being Apache committer I was watching closely how the Xalan is cooking. There is nothing scary in implementing XPath or XSLT, all standard techniques like building optimizing compilers apply, after all it's just another programming language to implement, probably the most interesting task for a programmer.
Needless to say, everybody interested is invited to participate. We are currently in the team gathering and initial planning stage. And by the way, we are receiveing donations. If you can't help us developing, but want to support the project - you can donate some money to the XQP project.
Well, XInclude.NET workspace at GotDotNet seems to be severely broken. I've sent a solid dozen of requests to fix it and now they even don't answer. Ok, moving the project to sf.net, specifically to the Mvp-Xml project. I'm adding XInclude.NET v1.2 sources to the CVS right now. After some setup I will be able finally to deliver new release, aligned with April 2004 XInclude CR. Stay tuned. And after that I'm going to pack nxslt.exe with latest EXSLT.NET and XInclude.NET and release it too (there are some minor new features too).
Cafe con Leche XML News:
Michael Kay has released Saxon 8.1, an implementation of XSLT 2.0, XPath 2.0, and XQuery in Java. Saxon 8.1 is published in two versions for both of which Java 1.4 is required. Saxon 8.1B is an open source product published under the Mozilla Public License 1.0 that "implements the 'basic' conformance level for XSLT 2.0 and XQuery." Saxon 8.1SA is a £250.00 payware version that "allows stylesheets and queries to import an XML Schema, to validate input and output trees against a schema, and to select elements and attributes based on their schema-defined type. Saxon-SA also incorporates a free-standard XML Schema validator. In addition Saxon-SA incorporates some advanced extensions not available in the Saxon-B product. These include a try/catch capability for catching dynamic errors, improved error diagnostics, support for higher-order functions, and additional facilities in XQuery including support for grouping, advanced regular expression analysis, and formatting of dates and numbers."
Hmmm, grouping for XQuery... Here is how it looks like in Saxon-SA:
declare namespace f="f.uri";
(: Test saxon:for-each-group extension function :)
declare function f:get-country ($c) { $c/@country };
declare function f:put-country ($group) {
<country name="{$group[1]/@country}"
leading="{$group[1]/@name}" size="{count($group)}">
{for $g in $group
order by $g/@name
return <city>{ $g/@name }</city>
}
</country>
};
<out>
{saxon:for-each-group(/*/city,
saxon:function('f:get-country', 1),
saxon:function('f:put-country', 1))}
</out>
Looks a bit convolute for me. More info here.
Tim Ewald shares some info on the MSDN2. Now that's soooo coooool! I think that's the best thing could happen with MSDN. And now I just don't believe they let Tim to leave MSFT!
Dare writes on "News Aggregators As Denial of Service Clients":
Recently I upgraded my web server to using Windows 2003 Server due to having problems with a limitation on the number of outgoing connections using Windows XP. Recently I noticed that my web server was still getting overloaded with requests during hours of peak traffic. Checking my server logs I found out that another aggregator, Sauce Reader, has joined Newzcrawler in its extremely rude bandwidth hogging behavior. This is compounded by the fact that the weblog software I use, dasBlog, does not support HTTP Conditional GET for comments feeds so I'm serving dozens of XML files to each user of Newzcrawler and SauceReader subscribed to my RSS feed every hour.
I'm really irritated at this behavior and have considered banning Sauce Reader & Newzcrawler from fetching RSS feeds on my blog due to the fact that they significantly contribute to bringing down my site on weekday mornings when people first fire up their aggregators at work or at home. Instead, I'll probably end up patching my local install of dasBlog to support HTTP conditional GET for comments feeds when I get some free time. In the meantime I've tweaked some options in IIS that should reduce the amount of times the server is inaccessible due to being flooded with HTTP requests.
This doesn't mean I think this feature of the aforementioned aggregators is something that should be encouraged. I just don't want to punish readers of my blog because of decisions made by the authors of their news reading software.
Well, I share Dare's thoughts. Happily my blog is already hosted on Windows Server 2003 and my favorite blog engine uses statically generated HTML/XML pages for everything including comments, so conditional GET saves me from rude aggresive news aggregators fetching comments for every post I've made last month every 30 min.
I'd avoid using Newzcravler and Sauce Reader news aggregators untill they stop being evil.
Wesner Moise (.NET Undocumented) writes on enums perf in .NET.
While enums are value types and are often recognized and treated like standard integral values by the runtime (in IL, enums and integers have almost no distinction), there are few performance caveats to using them.
Enumerated types are derived from ValueType and Enum (as well as Object), which are, ironically, reference types. An explicit conversion of an enum value to ValueType, will actually perform boxing and generate an object reference.
Any calls to an inherited method from any of those classes will also actually invoke boxing, prior to calling the base method. This includes the following methods: GetType(), ToString(), GetHashCode() and Equals(). In addition the costs of mplicit boxing is the far larger costs of reflection used to actually complete the said methods.
That's obvious, but this is not really:
ToString uses reflection, the first time it is called, to dynamically retrieve enumeration constants from the enumerated type and stores those values into a hash table for future use. However, GetHashCode always uses reflection to retrieve the underlying value. While ValueType.Equals will attempt to do a fast bit check, when a valuetype with no reference methods, such as is the case for enumerated types, it won't be faster than a direct compare.
This is true for any value type, but normally the cost can be eliminated for ToString, GetHashCode, and Equals, by simply overriding those methods and avoiding calls to the base methods. However, those methods CANNOT be overridden for enumerated types.
And this is sad:
Another ironic conclusion is that creating your own version of an enumerated type, not derived from Enum, is going to be faster than the CLR versions, because you can ensure that GetHashCode, Equals, ToString, IComparable, and IComparable<T> are not inherited from any of base classes such as ValueType.
Now what? Back to Java "enums "?
As it turned out unfortunatley I introduced nasty bug into date:day-name(), date:day-abbreviation() and date:month-abbreviation() functions while testing EXSLT.NET 1.1 before the release. Saturday and December never appeared :( Thanks to Chris Bayes for prompt bug report. Hence - EXSLT.NET 1.1.1 release. Please update.
Ken North:
Author Elliotte Rusty Harold talks about the significance of JDK 1.5 and whether
Java should be open source an/or an international standard. He also discusses
the state of XML, and we coaxed him into describing his recent books about XML
(Effective XML, XML Bible 1.1).
Streaming video (running time 7:01)
http://www.webservicessummit.com/People/EHarold.htm
I have just created first public mail list for the Mvp-Xml project - mvp-xml-help mail list.
mvp-xml-help list is general discussion list for all users of the Mvp-Xml project. The allowed topics on this list are: - Asking for help or helping others on using Mvp-Xml libraries.
- General announces related to the Mvp-Xml project.
- Suggestions, comments and other feedback related to the Mvp-Xml project.
No spam or offtopics are allowed.
Everybody interested are invited to subscribe.
SQLSummit.com published 15-minute video interview with Michael Rys on "SQL Server 2005: Integrating SQL, XML, and XQuery" - http://www.sqlsummit.com/People/MRys.htm.
"Michael discusses SQL Server 2005 support for XQuery, SQL/XML and the SQL:2003
standard. He discusses b-tree, quadtree, and r-tree indexes and pluggable and
selectable indexing techniques for XML documents. He also comments about the
evolution of XQuery."
Talking about Microsoft dialect - guess what's the first Michael's word in the interview? :)
[Via Ken North, the editor of SQLSummit.com]
Just found - a collection of public domain ebooks on Zoological Mythology and Cryptozoology - http://www.herper.com/ebooks/titles.html. Free download, lots of old lithographs. Amonst:
"Curious Creatures in Zoology", NY 1890;
"Mythical Monsters", London, 1886;
"Natural History Legend and Lore", London, 1895;
"Un-Natural History, or Myths of Ancient Science", Edinburgh, 1886.
Just interesting. And priceless for those looking for cool project names :)
So I'm in a critic mood today... I recently found out that XInclude.NET workspace is down for at least a month. Not surprisingly the feedback on the "Combining XML Documents with XInclude" article was so low - all the article links to XInclude.NET: homepage, message board and bug tracker are dead. Moreover and what's worse I can't get access to the XInclude.NET source code for at least a week! Holy cow! Looks like I was too optimistic about GotDotNet Workspaces.
Needless to say I decided to move XInclude.NET project out of there. It needs more reliable home, sorry. It's official now - XInclude.NET will be incorporated into Mvp-Xml project at SourceForge. It's a real pain to move stable project, but I have no choice.
Docbook XSL stylesheets v1.66.0 has been released yesterday. It's a huge (9Mb) collection of XSLT stylesheets for transforming Docbook documents into HTML, XHTML, XSL-FO (PDF), HTML Help and Java Help. They are well designed by XSLT experts such as Norman Walsh and extremely well tested by huge and diverse Docbook community. You know what I mean? I hope Microsoft testers responsible for the System.Xml will finally try to test .NET XSLT implementation against Docbook stylesheets before they ship - it's a shame that only after .NET 1.1 SP1 XslTransform stopped to barf on Docbook HTML stylesheets (and it's still unable to compile Docbook XSL-FO stylesheets... ouch, is it 2004 or 1999?).
Today it's Rosh HaShanah holiday in Israel - the Jewish New Year. The new 5765 year starts on the sunset. As a matter of interest, in Hebrew years are written in letters, not digits, e.g. new 5765 year is written as תשס״ה. It's not really that Israel lives accordng to this calendar nowadays, it's more a matter of tradition, but it's national holiday (actually solid couple of weeks of holidays), so happy new 5765 year to everybody! Shana tova umetuka!
Here is nice comic picture I got (it says "Happy New Jewish Year" in Russian):

Well, GotDotNet seems to be down sometimes :). Just in case here is alternative download location for the EXSLT.NET 1.1: http://www.xmland.net/exslt/EXSLT.NET-1.1.zip.
Here we go again - I'm pleased to announce EXSLT.NET 1.1 release. It's ready for download. The blurb goes here:
EXSLT.NET library is community-developed free open-source implementation
of the EXSLT extensions to XSLT for the .NET platform. EXSLT.NET fully
implements the following EXSLT modules: Dates and Times, Common, Math,
Random, Regular Expressions, Sets and Strings. In addition EXSLT.NET
library provides proprietary set of useful extension functions.
Download EXSLT.NET 1.1 at the EXSLT.NET Workspace home -
http://workspaces.gotdotnet.com/exslt
EXSLT.NET online documentation - http://www.xmland.net/exslt
EXSLT.NET Features:
- 65 supported EXSLT extension functions
- 13 proprietary extension functions
- Support for XSLT multiple output via exsl:document extension element
- Can be used not only in XSLT, but also in XPath-only environment
- Thoroughly optimized for speed implementation of set functions
Here is what's new in this release:
-
New EXSLT extension functions has been implemented:
str:encode-uri(),
str:decode-uri(),
random:random-sequence().
-
New EXSLT.NET extension functions has been implemented:
dyn2:evaluate(), which allows to evaluate a string as an
XPath expression, date2:day-name(),
date2:day-abbreviation(),
date2:month-name()
and date2:month-abbreviation()
- these functions are culture-aware versions of the appropriate EXSLT
functions.
-
Support for time zone in date-time functions has been implemented.
-
Multithreading issue with ExsltTransform class
has been fixed. Now ExsltTransform class is
thread-safe for Transform() method
calls just like the System.Xml.Xsl.XslTransform
class.
-
Lots of minor bugs has been fixed. See EXSLT.NET
bug tracker
for more info.
-
We switched to Visual Studio .NET 2003, so building of the project has been
greatly simplified.
-
Complete suite of NUnit tests for each extension function has been implemented
(ExsltTest project).
Any comments and bug reports are welcome!
PS. Well, despite Dimitre's and my light side's objections I implemented dyn2:evaluate(). I know, I'm evil...
From "Fallacies of Validation, version #3" by Roger L. Costello:
5. Fallacy of a Universal Validation Language
Dave Pawson identified this fallacy. He noted that the Atom specification
cannot be validated using a single technology:
> From [Atom, version] 0.3 onwards it's not been possible
> to validate an instance against a single schema, not
> even Relax NG. They need a mix of Schema and 'other'
> processing before being given a clean bill of health.
Aaron Skonnard about his The XML Files column of the MSDN Magazine:
This pretty much says it all. In the beginning, my column focused almost exclusively on core XML topics such as XML namespaces, XPath, XSLT, MSXML, System.Xml, etc. Over the past few years, my focus has naturally shifted away from these topics towards emerging SO and Web services concepts. It's been a natural evolution, indicative of my work and interests. Hence, the new name is appropriate. Dare's XML Developer Center is where you should look for continued coverage on core XML topics and System.Xml.
Although I'm sad to let go of The XML Files, I'm excited about manning the Service Station.
Lots of activity in the EXSLT.NET project recently. We implemented more functions such as random:random-sequence(), str:encode-uri() and str:decode-uri(). Lots of bugs have been fixed. Support for time zone in date-time functions has been implemented. We switched to Visual Studio .NET 2003 so simplifying our custom build process. Currently I'm writing unit tests for each function (and we have something about 80 of functions already!). After I finish it up I'm going to update documentation and release EXSLT.NET 1.2, so stay tuned.
Btw, I was thinking about adding some simple function for dynamic XPath evaluation. Of course we have no chance to implement dyn:evaluate() as extension function in .NET, but we could provide some simplified proprietary version, e.g.
object dyn2:evaluate(node-set, string)
where first argument is context node and second one is XPath expression (as string) to evaluate. This would allow to build and evaluate XPath expressions on the fly, the feature XSLT 1.0 doesn't and XSLT 2.0 won't support. It's gonna be limited of course - no variables, no keys etc., but anyway. Would you like to have such function in EXSLT.NET?
PS. I know, it smells provocatively, but it should attract more users to EXSLT.NET library.
Interesting post by Michael Kay on detecting cycles in graphs using XSLT and XQuery:
> I have XML data in the form of a graph (nodes, edges) and I
> need to check if
> any cycles exist in the data before I join the data together
> in one XML file.
>
> Can anyone point me to any resources to do this? Has anyone
> already done this in XQuery?
>
There is an example of how to do this in my book XSLT 2.0 Programmer's
Reference, and the example translates directly into XQuery.
If you don't want to buy the book, the code (together with a "main program"
that invokes it to look for cycles among the attribute sets in a stylesheet)
is here:
Take a look at the stylesheet here.
And now even more intriguing:
The book also shows how to generalize this so the code that looks for cycles
is independent of the way that the nodes and arcs are implemented.
Unfortunately this generalization relies on Dimitre Novatchev's technique
for simulating higher-order functions, which is dependent on XSLT and won't
work in XQuery.
Wow, I can't wait for the book to arrive. That's going to be my next one in reading queue, out of all priorities.
New and long awaited release of the MovableType blogging engine has been announced. New features of MT 3.1 include:
- Dynamic pages - now it's possible to switch between generation of static pages and dynamic generation. Well, I'm going to stay with static pages anyway.
- Subcategories
- Post scheduling
- Improved extensibility
- Plugin pack, including of course MTBlacklist (a killer plugin, allowing to control comment spam easily)
Free version allows only 1 author and 3 weblogs.
Well, I'm not sure really if I want to upgrade. I'm quite happy with my MT 2.66 + MTBlacklist installation.
Like most of us, Dijkstra always believed it a scientist's duty to maintain a lively correspondence with his scientific colleagues. To a greater extent than most of us, he put that conviction into practice. For over four decades, he mailed copies of his consecutively numbered technical notes, trip reports, insightful observations, and pungent commentaries, known collectively as "EWDs", to several dozen recipients in academia and industry. Thanks to the ubiquity of the photocopier and the wide interest in Dijkstra's writings, the informal circulation of many of the EWDs eventually reached into the thousands.
Although most of Dijkstra's publications began life as EWD manuscripts, the great majority of his manuscripts remain unpublished. They have been inaccessible to many potential readers, and those who have received copies have been unable to cite them in their own work. To alleviate both of these problems, the department has collected over a thousand of the manuscripts in this permanent web site, in the form of PDF bitmap documents (to read them, you'll need a copy of Acrobat Reader). We hope you will find it convenient, useful, inspiring, and enjoyable.
The manuscripts of Edsger W. Dijkstra. Really fascinating collection.
[Found in Michael Brundage's XQuery book].
By the way, Chapter 3 "Navigation" of the "XQuery: The XML query language" book by Michael Brundage is available online on Michael's site (PDF version). Take a look at http://www.qbrundage.com/xquery/toc.html.
Kurt Cagle is blogging. Unfortunately it's Atom only blog (via Google's Blogger) and my RSS Bandit 1.2.0.114 (SP1 RC1) doesn't seem to understand it. Grrrrrr, how does thay say it - "Don't be evil" and "Google's mission: Organize the world's information and make it universally accessible and useful."? Rubbish! When it comes to blogging, Google Is Evil.
[Via DonXML]
I had a foreboding of it. Dare Obasanjo:
For this reason we've reverted the XPathDocument to what it was in v1.1 while new functionality and perf improvements will be made to the XmlDocument. Similarly we will keep the new and improved XPathEditableNavigator XPathNavigator class which will be the API for programming against XML data sources where one wants to abstract away what the underlying store actually is.
That's a sharp turn! Strikeovered XPathEditableNavigator apparently means XPathDocument won't be editable and that's a main loss. Read-only XPathDocument has no chances to be any alternative to XmlDocument despite it's more effective, faster, more lightweight, XQuery-friendly etc.
They say developers love DOM. Hmmm, Java developers definitely don't, just look at numerous Java-and-developer-friendly DOM alternatives like JDOM, Dom4J, XOM etc. I remember my experience of processing XML using DOM in Java as a nightmare, I never had to write so dirty java code before and after that. Microsoft part of XML world is different - brilliant MSXML implementation is the only tree-based XML API for native Windows programming and ... it's brilliant. You see - the only and brilliant, that's a killer combination and that won't be so bad to have such one in .NET. Btw many don't realize MSXML actually extended DOM to make it at least usable, e.g. with "xml" property (InnerXml/OuterXml in XmlDocument) etc properties, which aren't actually W3C DOM). So the truth is developers love MSXML, not DOM. And they obviously love XmlDocument, because it's habitual and because it's is easier to use XmlDocument than XPathDocument even in areas where they compete. Try to select a value from namespaced XML to understand what I'm talking about. So XPathDocument is read-only and has clumsy API... No chances, be it even 10x faster.
The mismatch between the DOM data model and that of XPath meant that XPath queries or XSLT transformations over the XmlDocument would never be as fast as XPathDocument. Another reason we were doing this was that since the XmlDocument is not an interface
based design there isn't a way for people who implement their own XML document-like classes to plug-in to our world.
So... Now we gonna be forced to work with slow unextendable XmlDocument once again just because of legacy and laziness of devs??? Too bad. I wish we had at an alternative. C# has unsafe, .NET has not only VB.NET, but Managed C++, see what I mean? There should always be some more effective alternative for those who aren't lazy to learn something new and up to rewriting some code to gain performance boost.
And there is another side - one size doesn't fit all. I doubt XmlDocument can be made radically faster and it's interesting to see how it will survive in XQuery era, whose data model differs from DOM even more than XPath 1.0's. So instead of focusing fully on reanimating XmlDocument I wish System.Xml devs to focus on developing several tools best optimized for different scenarios. I wish we had editable XPathDocument in .NET 2.0. Do you?
In the related news: next generation of legendary books by Michael Kay are in print already and waiting for you in your favorite books shop.
 
Here is related discussion in xsl-list.
Things turn slowly nowadays. Michael Kay on XSLT 2.0 perspectives:
We're going to have to have a second Last Call because of the number of
comments received. You can't do a Last Call in much less than four months.
The CR phase these days for a complex spec is rarely less than 12 months,
because of the requirement to create a test suite and demonstrate
interoperable implementations. So I personally think that reaching full Rec
status in 2005 is looking unlikely. That's a personal view, not an official
W3C one.
The XSLT spec is probably more advanced than others in the family; but very
little work has been done yet on the testing side.
I'm reading "XQuery: The XML query language" book by Michael Brundage. Very well written and enjoyable to read book (well may be that's because my previous one was oh-boy-1000pages-of-math-and-pseudocode "Introduction to Algorithms" ? :). Anyway, here is what an interesting stuff I found in Michael's XQuery book. On page 29 Michael presents sample team.xml document, here is small excerpt from it:
<Employee id="E5" years="0.6">
<?Follow-up?>
<Name>Jason Abedora</Name>
<Title>Developer</Title>
<Expertise>Puzzles</Expertise>
</Employee>
Nothing special, huh? But look more thoroughly. Can you see an anagram here? There is additional hint on the page 136, where Michael illustrates one-to-one join of team.xml with another sample document projects.xml using FLWOR expression. Here is an excerpt from the join:
<Name>XQuery Bandit</Name>
<Name>Jason Abedora</Name>
Now it's easy to see it :)
Mikhail Arkhipov is trying to come up with any reasonable syntax for expressing generic controls in future versions of ASP.NET (he doesn't think it will be in Whidbey). So far all of them look plain ugly or unextendable (e.g. WRT to multiple types), needless to say malformed according to XML or even SGML:
<vc:SomeGenericControl<SomeObjectType> runat="server" />
<vc:SomeGenericControl:SomeObjectType runat="server" />
<vc:SomeGenericControl.SomeObjectType runat="server" />
<vc:SomeGenericControl(SomeObjectType1.SubType1, SomeObjectType2.SubType2)
runat="server" />
Any ideas?
My latest article "Building Practical Solutions with EXSLT.NET" has been published at the MSDN XML Developer Center. This is an overview of the EXSLT.NET library and its extension functions from the practical XPath/XSLT programming point of view. Basically I wanted to show how to use EXSLT.NET functionality in practice, so I went through all EXSLT modules and showed how these functions can solve frequent XSLT problems such as multistep transformations, date and time manipulations, doing math, parsing and matching using regexp, calculating sets difference, intersection or getting distinct nodes, padding, splitting, tokenizing, replacing and other advanced string manipulations etc etc etc.
Comments are welcome!
EXSLT.NET is sort of answer to "No XSLT 2.0 in .NET???" question and as such it unexpectedly becomes more and more important. In recent Online Chat with Microsoft XML Team, Arpan Desai, Microsoft PM on XPath, XSLT, and XQuery stack said: "Although EXSLT.NET is not officially supported by Microsoft, we will endeavor to make sure it works ;)". Another question was about moving EXSLT.NET into the core System.Xml to make it available out of box, more performant and what's more important - to eliminate full trust security requirement. They said they are considering it. Meanwhile there are some bugs and improvements on EXSLT.NET I wanted to work on. For reasons beyond my control I've got some free time this week, so...
Wesner Moise (.NET Undocumented blog) compares old good .NET 1.X System.Collections.Hashtable and brand new Whidbey Dictionary<K,V>. Interesting. In short:
- New collision elimination strategy - chaining instead of probing. Yeah, array based linked list for each bucket. Allegedly it doubles perf! Who said linked lists are just interviewers' toy?
- As a consequence - more thrifty memory usage, especially when storing value types.
- Dictionary preserves order of keys.
- Empty Dictionary occupies only 40 bytes.
- Struct-based enumerators hence fast enumeration.
- No probing hence no more load factor.
Stephan Kepser (University of Tubingen) has presented a talk called "A Simple Proof for the Turing-Completeness of XSLT and XQuery" on recent Extreme Markup Languages 2004 conference. You can find the paper at the link above and report by Elliotte Rusty Harold here. Here are my comments on that paper.
Cafe con Leche XML News:
Hot diggety dog! IBM and Novell are teaming up to add XForms support to Mozilla! If I were Microsoft, I'd be very, very worried right now.
Btw, MSDN Technical Chats now can be hosted by MVPs. Cool!
Recent Online Chat with Microsoft XML Team was tremendously interesting, but too short (45 min?). Being MVP I wonder what if we arrange some chats on actual XML topics, like XQuery, new stuff in System.Xml v2.0, new XML editor in VS 2005, XPath/XSLT for newbies/advanced, using EXSLT.NET, you name it (tell me what you'd like to discuss online). What about the idea?
Ok, this is a simple one, if
XML + XSLT = 5
XPATH + XPOINTER = 10
RSS + ATOM = 7
XINCLUDE + RELAXNG = 11
Then what is
XHTML + MATHML = ?
TheServerSide.NET and Developmentor offer free download of the "Essential XML Quick Reference: A Programmer's Reference to XML, XPath, XSLT, XML Schema, SOAP, and More" book by Aaron Skonnard and Martin Gudgin (PDF version).
432 page book covers XML 1.0 and Namespaces, DTD, XPath 1.0, XPointer, XInclude, XML Base, XSLT 1.0, SAX 2.0, DOM level 2, XML Schema 1.0 and SOAP 1.1. Very valuable reference.
[Via Mike Gunderloy]
I just got several instances of what I believe is another resourceful form of blog comment spam. It looked like an ordinar spam, somehow making it through MT-Blacklist system I've got installed and after "Name: free government grants" I was aready clicking on "De-spam using MT-Blacklist" link, but then I realized the domain name to be banned is "journalism.nyu.edu". Hmmm, free government grants on nyu.edu site???? Wait a minute!
And yes, that wasn't a joke. That linked page at journalism.nyu.edu is a very serious political blog rant with lots of comments and obviously "free government grants" comment among them! So here is how I think it works: they post an evil spam comment to a trustworthy blog B. Then if it doesn't get cleaned soon, chances are high that it will be staying in archives for a long time, so they start to spread more evil spam comments linking to the infected page at the blog B.
The bad thing is that banning such spam you have to ban (trustworthy) site B, which can be actually even your friend's site. Ergo: clean your blogs guys, don't keep spam comments in archives.
This is small trick for newbies looking for a way to get URI of a source XML and the stylesheet from within XSLT stylesheet.
As a matter of interest - how would you implement breadth-first tree traversal in XSLT? Traditional algorithm is based on using a queue and hence isn't particularly suitable here. Probably it's feasible to emulate a queue with temporary trees, but I think that's going to be quite ineffective. Being not procedural, but declarative language XSLT needs different approach. Here is what I came up with:
It's obvious, but I didn't realize that till recently - Chris Lovett's SgmlReader doesn't supprot namespaces. Why? SgmlReader is SGML reader in the first place and you know, there is no namespaces in SGML. So whenever you want to cheat and process malformed XML with SgmlReader - beware of namespaces.
Sometimes some of us want to narrow encoding of an output XML document, while to preserve data fidelity. E.g. you transform some XML source with arbitrary Unicode text into another format and you need the resulting XML document to be ASCII encoded (don't ask me why). Here is fast and simple solution for that problem.
Isn't it cool to have a small personal page at microsoft.com? :)
Every MVP got such one recently. Here is mine (aka http://aspnet2.com/mvp.ashx?olegt). And here is the XML MVPs gang.
Oh boy!
2004-07-19: The XML Schema Working Group has released the First Public Working Draft of XML Schema 1.1 in two parts: Part 1: Structures and Part 2: Datatypes. The drafts include change logs from the XML Schema 1.0 language and are based on version 1.1 requirements. XML schemas define shared markup vocabularies, the structure of XML documents which use those vocabularies, and provide hooks to associate semantics with them.
Main goals are to simplify the language and to add support for versioning. Read comprehensive review by Elliotte Rusty Harold at cafeconleche.org.
Isn't it cool:
A visitor to your weblog Signs on the Sand has automatically been banned by
posting more than the allowed number of comments in the last 200 seconds.
This has been done to prevent a malicious script from overwhelming your
weblog with comments. The banned IP address is
67.30.130.142
If this was a mistake, you can unblock the IP address and allow the visitor
to post again by logging in to your Movable Type installation, going to
Weblog Config - IP Banning, and deleting the IP address 67.30.130.142 from
the list of banned addresses.
--
Powered by Movable Type Version 2.661
http://www.movabletype.org/
For sure it's a must for any blogging engine nowadays.
USPTO did it again. Fun is going on. Now Oracle has been granted a patent on CMS. Patent 6,745,238 says:
The web site system permits a site administrator to construct the overall structure, design and style of the web site. This allows for a comprehensive design as well as a common look and feel for the web site. The web site system permits content for the web site to originate from multiple content contributors. The publication of content is controlled by content owners. This permits assignment of content control to those persons familiar with the content.
Is it sane actually?
Gudge writes:
On my team we have a bunch of guidelines for writing XML Schema documents. For a while we've been checking schema against the guidelines. Unfortunately the implementation of the checker was in wetware, rather than software. Recently, I found an hour or two to put together a software implementation of a SchemaCOP which, given a schema will dump out a report telling you where you've stepped outside the guidelines.
That would be very useful tool, really. I'm looking forward to see it.
And this is even more cool:
One of the satisfying pieces of writing the code was that I was able to do it all in XSLT. I love this language, it makes hard things easy ( and easy things hard :-) )
I tend to agree with the last assertion. I think knowing XSLT well means first of all having a gut feeling of these easy2hard spots and avoiding them at the design stage. As in any other language after all.
This is an interesting one:
The XML Schema Working Group has released a revised Working Draft of XML Schema: Component Designators. The document defines a scheme for identifying the XML Schema components specified by the XML Schema Recommendation Part 1 and Part 2.
The idea is to be able to address components of an XML Schema, just as we can address parts of an XML document by XPath or XPointer. An absolute schema component designator syntactically is an URI, whose main part is an URI of a schema document and fragment identifier is XPointer pointer conforming to the new proposed xscd() XPointer scheme. The syntax is obviously XPath-like.
Potential addressable XML Schema components are:
{type definitions}
{attribute declarations}
{element declarations}
{attribute group definitions}
{model group definitions}
{notation declarations}
{identity constraint definitions}
{facets}
{fundamental facets}
{member type definitions}
{attribute uses}
{particles}
{annotations}
etc.
Examples:
schema-URI#xscd(/type(purchaseOrderType))
schema-URI#xscd(/type(Items)/item/productName)
or even schema-URI#xscd(/type(Items)/item/quantity/type()/facet(maxExclusive)).
Good idea, isn't it? Obviously the core question is - why not just use XPath, the schema is just XML document after all? Actually looks like they are uncomparable things. AFAIK it's also one of first (after XInclude of course) real applications of XPointer.
Ok, this is not a new one, but just for those who somehow missed it (just like me).
A cool puzzle to solve: { First 10 digit prime in consecutive digits of e }.com
How much time does it take for you to crack it? My full time is about an hour (I'm not so good on sequences apparently).
PS. Try not to google for hints.
PPS. Please no spoilers in comments.
Antenna House released first lite version of their famous XSL Formatter (XSL-FO to PDF). It's much more cheaper than full version (only $300 for Windows version), but has a bit annoying (at least for me) limitations:
Total page number of the formatted pages are limited to 300. The watermark that shows the limited version is displayed on the back ground and the URL of our Website is displayed at the bottom of the pages which exceed 300.
Arabic, Hebrew and Thai are not supported. The formatted result is not correct.
The auto layout of the table is not supported. table-layout="auto" is invalid.
Anyway, free evaluation version, support for .NET - not bad.
Rick Jelliffe writes:
Perhaps some tricky implementation of XSLT could figure out if a stylesheet is streamable and switch to a streaming strategy.
That would be rather effective optimization indeed. But how that could be implemented in XSLT/XQuery processor? Obviously full-blown stylesheet analysis would be feasible only having schema information available (that means XSLT 2.0/XQuery 1.0), but even without it it's still easy to detect some common streaming-friendly cases, such as:
1. Renaming elements or changing namespaces, e.g.:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="foo">
<bar>
<xsl:apply-templates select="@*|node()"/>
</bar>
</xsl:template>
</xsl:stylesheet>
It's easy to see that the stylesheet has identity transformation and a template for "foo" element, which actually replaces "foo" witrh "bar".
Above is detectable and could be done more effective with XmlReader or XmlReader/XmlWriter pipeline.
2. Translating attributes to elements or similar, e.g.
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="foo">
<xsl:copy>
<xsl:for-each select="@*">
<xsl:element name="{name()}">
<xsl:value-of select="."/>
</xsl:element>
</xsl:for-each>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
Also that's detectable what above stylesheet is doing and is implemenatable with only XmlReader or XmlReader/XmlWriter internally instead.
3. Pretty-printing using XSLT - frequent case, easily detectable - an ideal candidate for optimization. Just stream input through XmlTextWriter internally.
4. Adding root element or adding header/footer - ditto.
5. Changing PIs in the prolog (<?xml-stylesheet>).
6. What else?
Obviously to gain something with all above implemented XSLT processor should be given plain Stream/TextReader/XmlReader as input, not any already-in-memory XML store.
Oh boy, what a month. Here is another juicy release I wish I had any free time to dig in: VSIP SDK 2005 Beta 1.
Visual Studio 2005 Beta1 is available for MSDN subscribers. And as ordinar ISO CD images, not 2.7Gb bundle. Let's make some good traffic today!
I'm tired of comment spam... It reached 15-30 spam instances/day level and finally I decided to install MT-Blacklist plugin for my blogging engine. 5 minutes of installation, updaing the blacklist, deep de-spamming and that it, I'm clean and protected. Well done, Jay Allen! Hope it's gonna help. Anyway if you are not a spammer and your comment has been refused, don't hesitate to mail me about that.
Cool news from the XML Editor Team (announced by Chris Lovett):
Announcing: New XML Editor in Visual Studio 2005 Beta 1
Visual Studio 2005 Beta 1 contains a completely new XML Editor, built on top of the core text editor provided by Visual Studio. It is entirely written in C# and leverages all the cool stuff provided by the System.Xml .NET assembly. The new XML editor provides support for editing XML and DTD content, including special support for XSD and XSL. It contains the following handy features:
* Full syntax coloring for all XML and DTD syntax.
* Well formedness checking while you type, with red squiggles and error list.
* Intellisense based on any DTD, XDR and XSD schemas.
* Validation-while-you-type with blue squiggles and error list.
* Auto-completion of namespace declarations, end tags and attribute value quotes.
* Support for xsi:schemaLocation and xsi:noNamespaceSchemaLocation attributes.
* Schema picker dialog for overriding schemas used for validation, which is then remembered as a document property in your solution.
* Schema cache for commonly used schemas with standard set provided out of the box. You can easily add your own schemas here or edit the existing ones to constantly improve your XML editing experience.
* Smart Formatter that is more than a pretty printer. It honors and formatting of attributes that you may have done by hand and it fixes up the most common mistakes people make in XML, like unquoted attribute values.
* Smart indenting based on XML element depth.
* Inline expand/collapse support.
* Easy navigation between start and end tags using brace matching command (Ctrl+]) .
* Brace highlighting so you see which tags are being closed as you type.
* Goto Definition command for navigating between elements and their associated DTD, XDR or XSD schema definitions. This command can also navigate from an entity reference to the entity definition in the DTD.
* Tool tips that popup showing xsd:annotations for the element or attribute under the mouse.
* XSL and XSD compilation errors while you type, providing even more error checking that can be represented in the schemas alone.
* Show XSLT Output command available on any XML or XSLT file.
XSD Schema Inference
The editor provides a handy command named "Create Schema" which does one of three things:
1. Convert associated DTD to XSD
2. Convert associated XDR schema to XSD
3. Infer a schema from the XML
This is by far the easiest way to get started with designing an XSD schema.
XSLT Debugging
In non-Express SKU's only, this feature gives you a powerful XSLT debugger, fully integrated into the overall Visual Studio debugging experience so you can step from C# code directly into the XSLT transform itself and back out, or from XSLT out to extension objects and back. It also provides a "Debug XSL" command on XML editor toolbar to start debugging directly from XML or XSL file.
Once debugging has started the standard Visual Studio debugging menu is available including special support for the following:
Setting and clearing breakpoints, at the node level (as opposed to line level).
Locals window that shows XSLT variables and parameters that are in scope.
Call Stack window that shows XSLT template stack.
Deep VS Integration & Extensibility
All the advanced core text editor commands and configurability is available, for example:
o Fully configurable colors using standard Tools/Options/Environment/Fonts and Colors property page.
o Fully integrated text editor settings (Tools/Options/Text Editor/XML) for general, tabs and miscellaneous settings.
o Support for the new Visual Studio 2005 "Import/Export Settings" feature.
Support for multiple-views over the same buffer. In Visual Studio 2003, the XSD designer and grid views were only available from a tab at the bottom of the document window, which means you could not view both ways at the same time. This limitation has been removed, and each different view is now a full fledged document window.
Custom XML designers can also be registered per file extension and/or XML namespace URI, which is how the Visual Studio XSD designer, DataSet designer, and the Grid View are associated with the XML editor. Anyone can now register an XML designer for a given namespace and the XML editor will automatically provide a View Designer menu item for invoking that designer. In fact if you are planning a custom XML designer, I'd love to chat about integration with this new XML text editor.
All I can say is "finally!"
Daniel implemented SubtreeXPathNavigator I was talking about. That's a way cool stuff, I really like it. Now I'm not sure about XmlNodeNavigator - do we need it in Mvp.Xml library or we better remove it to not confuse users with different forms of the same navigator?
I feel a bit guilty about Mvp.Xml project and the June plans I announced. Sorry, I just did nothing. I'm way busy with another unexpected stuff I just had to finish first.
Here is another interesting puzzle to solve - how would you validate Doctype-less XML document (which has no Doctype declaration) against DTD?
Well, I'm working on decreasing the size of the "Items for Read" folder in RSS Bandit. Still many to catch up, but anyway.
XML.com has published "Non-Extractive Parsing for XML" article by Jimmy Zhang. In the article Jimmy proposes another approach to XML parsing - using "non-extractive" style of tokenization. In simple words his idea is to treat XML document as a static sequence of characters, where each XML token can be identified by the offset:length pair of integers. That would give lots of new possibilities such as updating a part of XML document without serializing of unchanged content (by copying only leading and trailing buffers of text instead), fast addressing by offset instead of ids or XPath, creating binary index for a document ("parse once, use many times" approach).
While sounding interesting (and not really new as being sort of remake of the idea of parsing XML by regexp) there is lots of problems with "non-extractive" parsing. XML in general doesn't really fit well into that paradigm. Entities and inclusions, encoding issues, comments, CDATA and default values in DTD all screw up the idea. Unfortunately that happens with optimization techniques quite often - they tend to simplify the problem. It probably will work only with a very limited subset of XML, but it's fruitfullness still needs to be proven.
Another shortcoming of "non-extractive" parsing is the necessity to have entire source XML document accessible (obviously offsets are meaningless with no source buffer at hands). That would mean the buffering the whole (possibly huge) XML document in a streaming scenario (e.g. when you read XML from a network stream).
Still that was interesting reading. Indexing of an XML document, how does it sound? Using IndexingXPathNavigator it's possible to index in-memory IXPathNavigable XML store and to select nodes directlty by key values instead of traversing the tree. That works, but there is still lots of room for developement here. What about persistent indexes? What if XslTransform would be able to leverage existing indexes instead of building its own (for xsl:key) on each transformation?
Say you've got a DataSet and you want to save its data as XML. DataSet.WriteXml() method does it perfectly well. But what if you need saved XML to have a reference to an XSLT stylesheet - xml-stylesheet processing instruction, such as <?xml-stylesheet type="text/xsl" href="foo.xsl"?> ? Of course you can load saved XML into XmlDocument, add the PI and then save it back, but don't you remember Jan Gray's Performance Pledge we took:
"I promise I will not ship slow code. Speed is a feature I care about. Every day I will pay attention to the performance of my code. I will regularly and methodically measure its speed and size. I will learn, build, or buy the tools I need to do this. It's my responsibility."
Come on, forget about XmlDocument. Think about perf and don't be lazy to look for a performance-oriented solution in the first place. Here is one simple streaming solution to the problem - small customized XmlWriter, which adds the PI on the fly during XML writing.
RSS makes its way. TechNet's security team announced the first version of an RSS feed for its security bulletins: Microsoft Security Bulletin RSS Feed.
Reading wonderful "Chapter 9 - Improving XML Performance":
Split Complex Transformations into Several Stages
You can incrementally transform an XML document by using multiple XSLT style sheets to generate the final required output. This process is referred to as pipelining and is particularly beneficial for complex transformations over large XML documents.
More Information
For more information about how to split complex transformations into several stages, see Microsoft Knowledge Base article 320847, "HOW TO: Pipeline XSLT Transformations in .NET Applications," at http://support.microsoft.com/default.aspx?scid=kb;en-us;320847.
Sounds great, but referred KB article 320847 is actually a huge green fly in the ointment - it still suggests using temporary MemoryStream to pipeline XSL transformations! What a crap, didn't they hear about new XPathDocument(xslt.Transform(doc, args))??? I've reported that glitch more than a year ago and I've been told they are working to fix it. Still not fixed. Ok, probably that's time to use my MVP connections to get it finally fixed.
Another one I've stumbled upon:
XPathNavigator. The XPathNavigator abstract base class provides random read - only access to data through XPath queries over any data store. Data stores include the XmlDocument, DataSet, and XmlDataDocument classes.
Somehow "the XML data store" XPathDocument is forgotten once again :(
So I'm back. That was crazy trip Tel-Aviv-Prague-Berlin-Amsterdam-Paris-Bavaria-Prague-Tel-Aviv. Bad weather was chasing us, but fortunately it was mostly warm enough even for us sun-accustomed Israelis.
Mailbox overflow did happen and all incoming mail has been bounced during 06/01-06/03. If you were trying to send me something that days, you may want to resend it again. I just started mailbox cleaning (3000 unreaded / 70% spam). And RSS Bandit (600 unreaded / 0% spam :) is waiting for me too. I just removed about 100 spam comments from the blog. Recovering's going on...
That's all, folks. I'm on vacation from tomorrow for two weeks. We gonna fly to Prague, stay there for some days and then make a car trip across Europe. No laptop. I'll read my mail occasionally though (I'm afraid otherwise my mailbox will explode with all that spam and I miss an important mail I'm waiting for).
That was a tough week for me. Sorry if I didn't answer some mails and didn't do what I promised. I still hope to provide unit tests for my classes in Mvp.Xml lib this evening.
See ya in two weeks. The June plans are huge. One more (in addition to Dimitre's one) pure (reflection-hacks-free) solution for returning nodesets from XSLT extension function problem, using XInclude with configuration files, next relase of XInclude.NET (update for the latest spec, support for intra-document references via in-memory mode), thread-safety and perf improvements for EXSLT.NET, next nxslt.exe with embedded XSLT profiler and XPath/XSLT analyzer, next WordML2HTML stylesheets, better asp:xml control and unveiling my new pet project (which is different from what I did before - it's UI oriented, but of course XML related). Thanks for reading and stay tuned.
From daily-bad-news department: "That's it for now" from xmlhack.com, a good news site for XML developers.
It's been a lot of fun writing XMLhack since 1999, but it's time for us to take a rest.
At least :
Every endeavour will be made to keep XMLhack content online at the same URLs for the foreseeable future.
And thirdly, never say never. We may return.
Michael Rys (PM for the SQL Server Engine support of XQuery) is trying to bring some order into the confusion around XQuery 1.0 and XPath 2.0 type system. His first instalment in the series introduces the terminology and general concepts. Read it here. More to come, worth to stay tuned.
Here is another piece of a must reading - "Chapter 9 - Improving XML Performance" of the "Improving .NET Application Performance and Scalability" guide from the Microsoft Pattern and Practices group. Here are the objectives : Optimize XML processing design, Parse XML documents efficiently, Validate XML documents efficiently, Optimize your XML Path Language (XPath) queries, Write efficient XSL Transformations (XSLT). Wow, amazingly good paper.
Here is interesting paper "XSLT and XPath Optimization" by Michael Kay. That's materials of Michael's talk at recent XML Europe conference. In this paper Michael reveals details of the XSLT and XPath optimizations performed internally by SAXON (XSLT and XQuery processor):
This paper describes the main techniques used by the Saxon XSLT and XQuery processor (http://saxon.sf.net/) to optimize the execution of XSLT stylesheets and XPath expressions, and reviews some additional XSLT and XPath optimization techniques that are not (yet) used in Saxon.
A must reading for those developing or thinking to develop XPath/XQuery/XSLT plumbing.
[Via XML.com]
Finally XPathReader has been unveiled at the MSDN XML DC in "Extreme XML: Combining XPath with the XmlReader" article by Dare Obasanjo and Howard Hao. Really, really interesting solution, alredy used in Biztalk internals to optimize XML pipeline processing. Need to play with it more.
I like XPathReader. It reminds me ForwardXPathNavigator and XSE. There is a real niche for streaming XPath querying - whenever one needs to query some value out of XML document without either writing potentially complex (hello state machine) XmlReader-based code or wasting resources loading the whole XML into memory. Streaming XPathReader is a perfect solution here. And limiting XPath here I believe is quite reasonable tradeoff. I hope some day XPathReader will make it to the System.Xml.
What I wonder to know though is what's behind the decision to augment XPathReader (which is XmlReader) by Match() an friends methods, which are traditionally associated with XPathNavigator? Why not implement standard XPathNavigator over XPathReader?
Additionally Dare created a GotDotNet workspace for the further development of the XPathReader and invited devs to join. I think XPathReader has a big future. Applied already.
Mono project (an open source implementation of the .NET framework for Linux, Unix and Windows) reached Beta1 stage. They say Mono 1.0 can be released this summer already.
Now to funny part. I've been reading Release Notes while downloading the release and found myself in the contributors list :) Well, in fact there are some classes in Mono codebase marked as created by me. But I should admit my contribution was really a small one - several patches, several trivial classes (in System.Xml.Xsl namespace) and then I lost my interest due to personal reasons. I still have write access to the Mono CVS, so may be, some day, who knows, again...
Daniel writes about transforming a portion of XML document using XPathNavigatorReader. That's a common bad surprise for MSXML-experienced people, who used to fooNode.transformNode() method, where only fooNode and its descendants are visible in XSLT. In .NET that's different - no matter which DOM node you pass to XslTransform.Transform() method, the whole XmlDocument tree is visisble in XSLT. MSDN suggests to load the portion of XML you want to transform into a temporary XmlDocument and pass it to the transformation. Too bad.
What Daniel proposes instead is to load the portion of XML to be transformed into a temporary XPathDocument instead of XmlDocument. Well, that's better, but what I'd like to ask is why do one need any temporary tree at all? It's a piece of cake to write custom XPathNavigator that would limit navigation only to a specified subtree. I did that once with XmlNodeNavigator, which represents XPathNavigator over XmlNode. Less than 10Kb of code. It's ideal solution to transform only a subtree of an XmlDocument. No temporary objects, just lightweight code between XmlDocument and XSLT that limits navigation not higher that specified node.
That's perfect for XmlDocument. For XPathDocument we need another one. Or better we need generic XPathNavigatorNavigator (did we really go nuts with these XML beasts?). XPathNavigatorNavigator should allow to navigate over given XPathNavigator, but should not allow to move it outside the subtree. Comments?
XPathNavigatorReader and XmlNodeNavigator are both parts of Mvp.Xml project.
I'm blogging sparely last time due to trivial lack of time. I'm taking two MVP academy courses (advanced C# and ASP.NET level 200) simultaneously, trying to catch up with what I've promissed for Mvp.Xml and XInclude.NET projects, preparing new article and working on my new pet project, which I'm going to unveil soon. Oh, and 9 hours of the day job too! Oh, I want a bit of vacation.
New version of the RSS Bandit has been released today. Amonst new features: support for Atom 0.3 support, ability to synchronize installations (killer!), 5 translations including Russian one made by me and lots more! Updated. Didn't check new features yet, but I can say the responsiveness is also improved!
This synchronizing feature is a real killer. I'm reading news from both home and work computers and now I can save huge amount of time having synchronized installations! That was so boring and depressing when I open RSS Bandit at home and needed to go through all feeds, thousands of items to see which I've read at work already and which I haven't. No more that silly waste of time, thanks to Dare and other members of the RSS Bandit team.
As Evan Lenz pointed out, O'Reilly put Chapter 2 ("The WordprocessingML Vocabulary") of the "Office 2003 XML" book online. Here it is (88 pages pdf). Excellent introduction to WordML. Those who want to learn WordML - go read it (or buy the book).
RenderX has announced the first release (somehow it's v3.0 :) of XEP.NET - XSL-FO formatter for .NET.
XEP.NET is a Visual J#.NET port of RenderX XEP, an XSL formatter for Java;
its functionality and XSL FO support level are identical to the Java
version. The XEP.NET core is wrapped in an API that exposes
standard .NET interfaces for XML processing. This public API forms
a .NET class library component that can be used from any .NET
programming language: C#, VB.NET, or J#.NET. Additionally, the
software includes a class library for MSXML integration that
allows use of MSXML SAX parser and transformation APIs in addition
to .NET system interfaces.
Prices from $299.95 (client edition) to $4999.95(server edition), free trial (11 pages only), free academic edition.
Now this is really interesting:
All editions include XEP.NET Assistant - a graphical shell to make
formatting more convenient, and command-line tools for launching
the formatter and the validator.
Lack of visual XSL-FO designers is one of main XSL-FO weaknesses. I'm glad to see such XSL-FO legend as RenderX is trying to fix it.
Hey, just look at that:
Michael Kay, author of the famous "XSLT : Programmer's Reference" book, developer of Saxon XSLT and XQuery processor and Editor of XSLT 2.0 spec, has announced his next generation books. He has splitted XSLT 2.0 and XPath 2.0, which sounds quite reasonable considering huge growth of XPath on the schema steroids. The books are not available yet (August 2004), but Amazon sells them already with big discounts.
Once back in 2000 I've been learning XSLT and XPath with first edition of the "XSLT : Programmer's Reference". Four years latter this book still on my table, I still use it (mostly as reference though). Ok, I just ordered those new books and let's wait August. Btw, does publishing the books means XSLT 2.0 Recommendation is coming? As XSLT 2.0 editor Michael definitely should know it better.
I did it again. My second article has been published at MSDN. It's about XInclude itself and XInclude.NET project. It's named "Combining XML Documents with XInclude".
It gives quite comprehensive introduction to the XInclude and XPointer processing model, syntax and semantics. Also practical questions of combining XML documents using XInclude.NET library are discussed. XInclude.NET v1.2 release accompanies the article.
While the article is based on November's XInclude Last Call Working Draft, none is obsoleted, happily I managed to avoid discussing of all small XInclude features, which were likely to be changed. It's my understanding that no significant changes to XInclude are expected anymore, it has crystallized already and is going to be published as Recommendation this year. So go read this article if you want to get ready for another XML Core technology.
Needless to say - any comments would be greatly appreciated!
I like these things. Looks like Daniel solved the famous in-memory XML document validation problem (which I thought is unsolvable!) with XPathNavigatorReader.
Well, I'm probably the last one on this, but anyway: Microsoft released new pack of Office XML schemas and related documentation. What's included? WordprocessingML (Word), SpreadsheetML (Excel), FormTemplate XML (InfoPath) and (new!) DataDiagramingML (Visio) XSD schemas, overviews and other reference docs. Good one. Installed.
Funny thing happened with XInclude.NET 1.2 release. Somehow it appeared on Microsoft Downloads and the "mindless link propagation" has started - Mike Gunderloy in "The Daily Grind 350" has called it "XInclude.NET 1.2 - Microsoft implementation of the November 2003 working draft of XInclude.", James Avery forwarded it in the ".NET Nightly 150" as "XInclude.NET 1.2 - Microsoft's implementation of XInclude. (The old spec, not the new one)".
I think it should be stated clearly to avoid further confusions - XInclude.NET isn't "Microsoft's implementation". It's open source project, hosted on Gotdotnet Workspaces. Its homepage is http://workspaces.gotdotnet.com/xinclude and everybody invited to join the development. I mean nothing, just wanted to clear things for those how consider it important.
I'm not aware of XInclude implementation from Microsoft yet (as XInclude spec itself is still work in process). I'm sure they will ship it once W3C promotes XInclude to the Recommendatin stage, but for a while you can use XInclude.NET, which isn't bad one. I'm currently updating it to the latest Candidate Recommendation as I was talking ablout. And my article about XInclude and XInclude.NET should be published at MSDN XML DevCenter soon. So stay tuned - subscribe to MSDN XML DevCenter RSS feed.
There is a severe problem when using Mozilla Mail and News client (and derivatives such as Thunderbird Mail) - they don't support multiple accounts on the same NNTP server. You know what I mean, right? Yeah, that's about Microsoft private newsgroups. They are using the same news server - privatenews.microsoft.com, while different accounts to manage an access to different newsgroups. One day I found myself struggling with creating 3 accounts on privatenews.microsoft.com. Mozilla seems to be treating news server name as a unique key, so whenever you add another news account, providing already existing news server name - bad and weird things happen. Ooops, new account isn't added and old one is broken. Too bad.
Happily I found the solution. On Windows one can create as many as needed local aliases to an IP address using old good hosts file, living in system32/drivers/etc directory. So all you need is to add an alias to 207.46.130.117 IP (static IP of privatenews.microsoft.com), e.g.:
207.46.130.117 whidbey
Then "whidbey" can be used as full-fledged domain name - you can use it as news server in Mozilla mail to create Whidbey private news account. The only difference between real domain name and an alias is that alias will be resolved to IP locally, while real domain name - on remote DNS. Not bad workaround. May be I'm the last one who found it, abut anyway I just wanted to share this info.
Hey, look at this cool stuff:
On to something more pleasant: Microsoft is continuing to advance on the
openness front. There are all those weblogs that I've mentioned a time
or six, there's the open-source release of the WiX installer tools
(http://sourceforge.net/projects/wix/) and now (as of today, in fact)
there's another addition to the Microsoft Open and Royalty-Free Office
2003 XML reference schema program (say THAT fast three times!), because
Microsoft just announced the release of DataDiagramML.
DataDiagramML, as you might guess from the name, is the XML schema
that's used when you save a Visio document as XML. Having this
documented has the same great interoperability benefits as
WordProcessingML offers for Word or SpreadsheetML offers for Excel.
Knowing the complete structure of the document, it's easy to modify it -
for example, you can grab information from a database and use it to
modify an existing Visio document, all through standard XML tools. The
other half of the equation is that you don't even need Visio to build a
DataDiagramML document; you can use whatever XML tool you like to output
a document that conforms to the schema, and it should open fine in
Visio.
For many years, we complained that Microsoft insisted on using
all-proprietary formats for its Office documents. Now that Word, Excel,
InfoPath, and Visio all have the capability of saving into open,
documented formats, this criticism is losing some of its sting. (Though
not all of it...*cough* Access *cough*). The next step, I think, would
be a world where the XML formats are the default, and Microsoft commits
to open up every file format they create, from Outlook Express to
Project. Then we'd have a world where your data was yours, and you could
move it to any tool you liked. I'll bet Microsoft would compete pretty
hard to keep our business on a features and benefits basis in that
world, instead of depending on format lock-in.
Anyhow, today's release is a big step forward. More details at
http://www.microsoft.com/office/xml/default.mspx and
http://www.microsoft.com/presspass/press/2004/apr04/04-15XMLSchemaPR.asp
Mike Gunderloy, ADT Mag's Developer Central Newsletter.
Well, nothing to add, Mike said enough.
I've been told privately this book is going to be totally a killer:

"Office 2003 XML: Integrating Office with the Rest of the World"
by Evan Lenz, Mary McRae, and Simon St. Laurent
This book explores the relationship between XML and Office 2003, examining how the various products in the Office suite both produce and consume XML. Beginning with an overview of the XML features included in the various Office 2003 components, Office XML 2003 provides quick and clear guidance to anyone who needs to import or export information from Office documents into other systems.
Authors are real XML and Office experts. The book is not published yet (expected in June), but worth to preorder. AFAIK should be some links to my blog in this book, must to buy it only to see it :)
XInclude reminds me a little poor ant, which climbs up a wall, falls, climbs, falls again and climbs anyway. Today XInclude became Candidate Recommendation for the third time!
W3C is pleased to announce the advancement of XML Inclusions (XInclude) Version 1.0 to Candidate Recommendation. XInclude introduces a generic mechanism for merging XML documents (information sets) using existing XML constructs-elements, attributes and URI references. Comments and implementation reports are welcome through 28 May.
Let's see what's new. Oh no! They are changing the namespace back. It was "http://www.w3.org/2001/XInclude" untill latest Wordking Draft, which made it deprecated and introduced "http://www.w3.org/2003/XInclude". Today's Candidate Rec reverts previous "http://www.w3.org/2001/XInclude" namespace back. No fun at all. Happily XInclude.NET already supports both namespaces. Other changes are minor ones - accept-charset attribute removing, clarifications, editorial improvements, and minor bug fixes. No big deal so I'm going to update XInclude.NET and nxslt.exe next week.
In related news - The XML Core Working Group has released the First Public Working Draft of xml:id Version 1.0.
The specification introduces a predefined attribute name that can always be treated as an ID and hence can always be recognized.
What can be said? At last! Finally!
xml:id Version 1.0 defines core predefined attribute xml:id you can use anywhere in XML documents (with or without DTD or schemas attached) to annotate elements with unique identifiers. Great stuff. I'm going to investigate possibilities of creating experimental implementation of xml:id for .NET. Mark wrote about it recently.
Something new and intriguing has been published by W3C - XML Processing Model and Language Requirements.
This specification contains requirements on an XML Processing Model and Language for the description of XML process interactions in order to address these issues. This specification is concerned with the conceptual model of XML process interactions and the language for the decription of these interactions.
So in simple words it's a new XML language to describe XML processing. Say you want to get XML document out of Web Service, validate it, resolve XIncludes, XQuery some data and accordingly to the results apply some XSL transformation. Of course you can write custom application to do so (and keep doing so for each new XML processing scenario), but having XPL (or may be XPML) processor available you can just define the processing flow in XML document an run it. Cool. Similar to Apache Cocoon's XSP and BizTalk orchestrations.
Some teasing use cases:
Style an XML document in a browser with one of several different stylesheets without having multiple copies of the document containing different xml-stylesheet directives.
Apply a sequence of operations such XInclude, validation, and transformation to a document, aborting if the result or an intermediate stage is not valid.
Allow an application on a handheld device to construct a pipeline, send the pipeline and some data to the server, allow the server to process the pipeline and send the result back.
Norm Walsh is in editors, so I'm sure it's gonna be great new XML family member.
Don Box runs HTTP-based ASMX services without IIS (in Whidbey of course). Really cool.
So Dare said it - unfortunately XmlAdapter and XPathChangeNavigator won't make it into System.Xml v2.0. Funny enough, but looks like I was right in my assumption about what's gonna be cut. Well, without these System.Xml v2.0 probably won't be so harmonious and beautiful as Mark has described in his "First Look at ADO.NET and System Xml v 2.0" book, but real world disctates other criterions - "both APIs was complex to implement yet could be satisfied through other mechanisms".
Dimitri has posted a JavaScript implementation of W3C DOM Level 3 XPath for Microsoft Internet Explorer. It allows to use XPath with a plain-vanilla HTML. Looks interesting. I don't work with HTML DOM for a long time, but thinking about it now I realize I can do just nothing without XPath!
Ok, once I volunteered to make Russian translation for RSS Bandit - my favorite RSS aggregator, so finally I had to do it. It took me couple of days of my vacation time and it wasn't easy. There are just no established Russian translations for RSS terms, even for basic ones such as "feed" and "syndication". RSS is still extremely new stuff for Russian Web community, and very very few sites provide RSS feeds. So I had to discuss terms in Russian-speaking XML community and to invent the rest :) I did it once I translated XPath spec into Russian and I hope it will be successful translation again.
I believe it's a good one. I really hope somebody will find it useful. AFAIK RSS Bandit is going to be the very first news aggregator with Russian UI. Here is how it looks like:
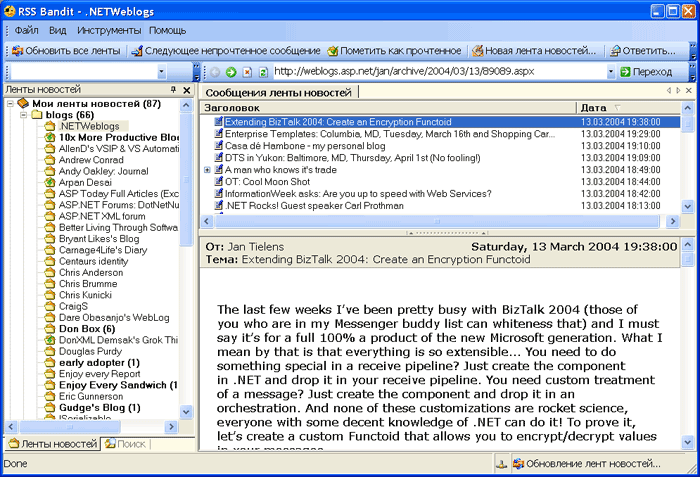
So let's wait till next version of RSS Bandit is out. Needless to say: comments, suggestions, reports of typos and bad wordings - I appreciate all that stuff.
Microsoft has released another WordML to HTML transfromer - Word 2003 XML Viewer (thanks to Sal for pointing that). As I expected due to images issue it won't be single XSLT stylesheet such one as was released for Word 2003 Beta 2. This time it's complete viewer application, not just XSLT stylesheet you can use in your stuff. How it's implemented? It's kinda plugin for Internet Explorer, which transforms WordML to HTML using word2html.xsl stylesheet and handles images (wordml:// URL schema) somehow. It also substitutes standard context menu in Internet Explorer when vieweing WordML docs. Basically I like it, good stuff.
So whenever you want to browse a WordML document without Word 2003 installed you can just open it in Internet Explorer (provided Word 2003 XML Viewer is installed) an let it do the job. You can also include Word 2003 XML Viewer along with your document to let users install it. Sounds not bad, but not without some deficiencies. First of all your users must have viewer installed. Second - they must use IE, third - be on Windows platform. So the question is should I proceed with my WordML to HTML stylesheet or should it be abandoned? Basically my stylesheet produces pure HTML, thus placing no prerequisites on client side. But it's XSLT processor-dependent due to image processing (.NET version is only available yet, MSXML and Saxon versions were expected). Basically I believe it's still highly useful in custom WordML processing scenarios(e.g. for Word-based blog editors). I'd like to hear your comments though.
/. reminds it's 40-years anniversary of IBM mainframes tomorrow. Read "IBM's Mainframe Dinosaur Turns 40" thread. Mainframes still host 70% of the world's data and applications (well, IBM says that, granted) and they feel good in modern PC world. "PCs were supposed to kill off the mainframe" he-he-he. Not so fast.
Almost all projects I involved at my day job are mainframes connected. Couple years ago we built DOM and XPath/XSLT engine for mainframes and the latest one we did was about exposing of mainframe applications as Web Services, that was an interesting one. And having Cobol apps to be Web Services enabled allows to not touch them and the mainframes for another 40 years! You know, "if it ain't broke...".
Btw, I'm on Passover vacation this week, so don't expect me to blog much.
The BizTalk Server 2004 SDK Refresh contains updates and additions to samples, utilities, headers, and other developer artifacts to aide in the development of BizTalk Server 2004 applications.
Download here.
[Via Bryant Likes]
Good news for MSDN subscribers: be notified of new downloads available from MSDN Subscriber Downloads via this RSS feed.
This tool is undeservedly forgotten, but frequently asked and usually hard to find (somehow it's constantly moving around MSDN breaking the links). I'm talking about "Internet Explorer Tools for Validating XML and Viewing XSLT Output". IE out of box doesn't allow you to validate XML, the only way is to write some script. Also
when you open an XML document with attached XSLT stylesheet in IE you cannot view the result of an XSL Transformation, instead View Source shows source XML. These regrettable omissions make it hard to work with schemas and XSLT with bare IE.
Enter "IE Tools for Validating XML and Viewing XSLT Output" - Microsoft add-in for IE, which adds two commands into the browser's context menu - "Validate XML" and "View XSL Output". Very useful, a must to have for any XML developer. And implementation is soooo simple, just few lines of javascript. I wonder - can Microsoft make it into the core Internet Explorer code so it's available in each IE without additional add-in installation?
Ivan posts a link to the "GHOST TOWN" - a story of a real girl riding on a motorbike through the closed Chernobyl area, where nuclear powerplant has exploded back in 1986. Lots of fantastic photos. Abandoned cities 18 years after the disaster. Deadly amazing and sad story.
I've been there 2 years ago. My mother was born and grew up in a region close to that area (near to Kiev) and that's where my granddad and grandma rest in peace. They've been told about the nuclear disaster a week after! Fucking commy wanted to keep it in a secret. Sad story.
May be I missed something, but looks like Travis Bright is converting Apache Xerces XML parser to .NET. I wonder what for?
Aha, he's PM for the Java Language Conversion Assistant (JLCA). That explains. Btw, one day I stumbled across CSS parsing in .NET. Java version of the product I've been working on used W3C's Flute CSS parser and I didn't manage to find any .NET CSS parsers. So I just created J# project in Visual Studio, imported Flute's java sources, compiled them into dll with no any hitch and that's it - it just worked.
Well, of course the breaking news today are all about recently launched MSDN XML Developer Center. Should admit I've been checking http://msdn.com/xml several times a day last weeks :) At last it's up and it looks just great! Somebody said it's like blessing for XML. Kinda true. Of course the Dev Center has dedicated RSS feed - http://msdn.microsoft.com/xml/rss.xml - subscribe now. It's overwhelming to see a link to my blog in the front page too! WOW, now I should write only smart stuff.
Apparently it's possible to set a background image in VisualStudio.NET text editor via undocumented API. Interesting exercise.
[Via Mike Gunderloy]
Daniel says he's disappointed in SAX.NET project I was writing about. Unlike lazy me, he downloaded it and inspected implementation. Well, I mostly agree with him. This piece of direct thoughtless porting of complex convolute Java API to .NET looks weird and kinda unnatural. "namespace System.Xml.Sax {" isn't what I like to see altogether. Too many conventions are broken. Too bad to taste good. Well, I hope are they will improve things. At least todays conversation in xml-dev gives some hopes to think that.
Attributes2 and friends are traces of long SAX API evolution. SAX was created in a vacuum, there wasn't standard Java XML API at that time, while SAX.NET is going to live in .NET land and must be System.Xml-friendly. The question is is it feasible at all?
W3C announced the creation of the XML Binary Characterization Working Group.
Chartered for a year, the group will analyze and develop use cases and measurements for alternate encodings of XML. Its goal is to determine if serialized binary XML transmission and formats are feasible.
The WG has been created as a result of the Binary Interchange Workshop. Here is what their goals are:
The XML Binary Characterization Working Group is tasked with gathering information about uses cases where the overhead of generating, parsing, transmitting, storing, or accessing XML-based data may be deemed too great for a particular application, characterizing the properties that XML provides as well as those that are required by the use cases, and establishing objective, shared measurements to help judge whether XML 1.x and alternate (binary) encodings provide the required properties.
Too bad. I was hoping that won't happen and now I only hope they will decide that's bad idea and interoperability costs more than "overhead of parsing". Dare well argued Binary XML is evil here and I only subscribe to the views he quotes.
A long and convolute discussion about security problems of using EXSLT.NET in ASP.NET took place in EXSLT.NET message board. Here I'd like to formulate some short summary.
Looks like Google got new site skin. I like it. Lightweight and clean.
This webcast is going to be really interesting one: MSDN Webcast: Real-World BizTalk Server 2004 Editing and Mapping Techniques - Level 200
This session is a deep dive on the BizTalk Server Editor and Mapper. Learn how to model flat-files and EDI-files. Learn how to detail with complex mapping scenarios including embedding your own XSLT, using .NET components in maps, performing cross-referencing and exercising the table extractor functoid.
Presenter: John Ballard, Program Manager, Microsoft
Enroll here.
[Via Frank Arrigo]
May be I missed the train, but look what I discovered in the recent "Microsoft This Week" newsletter: MSN toolbar. It looks exactly like Google toolbar, moreover what's funny, http://toolbar.msn.com and http://toolbar.google.com pages are just the twins!
After all that's good move. I hope the competition is going to be fruitful for us, ordinar users. Let's compare. Both can block pop-up ads, search the net (obviously), keyword highlight. MSN toolbar can launch MSN Hotmail, MSN Messenger and My MSN directly, Google toolbar can't. Google toolbar can fill in forms with one click, MSN toolbar can't. Well, personally, as 1) I'm not using MSN Hotmail and My MSN, 2) my MSN messenger starts at Windows startup; 3) I like/use Google's autofill feature a lot - I still stay with Google toolbar.
Visual Studio 2005 Community Technology Preview March 2004 - Full DVD available for MSDN subscribers!
Arrrgh, I missed that day - 20 March my blog crossed 1 year timeline. Here is what I wrote a year ago:
Well, blogging is really infectious disease and finally I got the infection. I have installed Movabletype engine on my site quite easily (c'mon, it's cgi based) and here is my first record.
Lets see how it works. Administering is not bad and default template looks really nice, but I'm sure I'll modify all the style once I get some free time.
I named my blog "Signs on the Sand" (it took me the whole evening and the night to formulate my feelings), because I believe that's what all these words worth and that's their final destiny. Hmmm, whatever, I like it.
So happy blogging to me.
Ok, my productiveness was 190 blog items a year. Too bad. Must write more. Anyway, I'm glad I stepped in and today I just can't imagine myself without blogging and reading blogs. Every my morning starts with Mozilla Mail and RSS Bandit. So happy blogging to all of us!
Hey, SAX for .NET topic is becoming hot. I was aware of one implementation (to be unveiled really soon), being developed by my fellow MVP/XmlInsider, but apparently there is another one, by Karl Waclawek. Here is what he writes in xml-dev mail list:
The SAX dot NET project on SourceForge has the
goal of porting the SAX2 API to C#/.NET:
http://sourceforge.net/projects/saxdotnet
A release 0.9 (beta) can be downloaded from:
http://sourceforge.net/project/showfiles.php?group_id=95340 .
What's mostly untested is the helper classes.
The rest has already undergone usability testing
in the form of implementing an adapter for Expat.
Karl is known as seasoned XML developer, I particularly know him as one of Expat XML parser devs. Expat is a great XML parser, originally developed by James Clark (enough said). It's written in C and is magically fast one. At my work we use it as base XML parser for all XML tools we write for mainframes, yeah, that's really good one.
I'm glad to see growing appreciation of the .NET in broad XML community and I do believe community-developed implementation of SAX for .NET would be great step forward this way. The very fact of emerging SAX for .NET projects doesn't mean XmlReader's pull-based XML parsing paradigm is bad or disappoints some of us. Both pull and push parsing paradigms have pros and contras and having both available in .NET is a good sign of the technology maturity.
Here is a definitive answer:
Beginners always ask this question.
Those with a little experience express their opinions passionately.
Experts tell you there is no right answer.
Mike Kay
Update: this post is outdated, see "WordML2HTML with support for images stylesheet updated" for updates.
Here is a new version of WordML2HTML XSLT stylesheet, developed by Microsoft for Word 2003 Beta2 and adapted by me to Word 2003 RTM. I called this version "1.1-.NET-script". Here is why. Along with some bug fixes (typo with w:rStyle, empty <title> in generated HTML etc) I implemented basic support for images. That required XSLT extension function, which I implemented with .NET and <msxsl:script>. MHT and MSXML/Jscript versions are coming soon.
Here I go again with another experimental creature from my XML Bestiary: IndexingXPathNavigator. This one was inspired by Mark Fussell's "Indexing XML, XML ids and a better GetElementByID method on the XmlDocument class". I've been experimenting with Mark's extended XmlDocument, played a bit with XPathDocument and "idkey()" extension function Mark was talking about. Finally I came to a conclusion that 1)XPath is the way to go (that' not the first time I say it, right? :) and thus what should be extended is XPathNavigator; 2)no need to reinvent the wheel as XSLT's keys is proved excellent stuff.
That is what IndexingXPathNavigator is - XPathNavigator, augmented with XSLT keys functionality: it supports declaring keys, lazy or eager indexing and retriving indexed nodes via key() function all as per familiar and proved XSLT semantics.
Here is what MovableType blogging engine team writes:
We're taking our first steps towards the release of Movable Type 3.0. The pre-beta version has just finished its initial two rounds of alpha testing and we're now opening the testing to a larger audience ...
What's new includes: "significant change to the existing interface that embraces web standards, usability and localization", "new set of default templates", "suite of comment management features and versatile comment registration", API authentication hooks, Atom API.
Starting today, we'll be giving all of our users much more information on what to expect in Movable Type 3.0.
Sounds promising.
Hey, good news about GotDotNet Workspaces again! Changes on the releases section scheduled for tomorrow include: per-release download count (AT LAST!!!), no more zero-byte/corrupt downloads (I hope), no more Passport sign-in for downloads (great), off-site hosting of releases (cool). Really sweet.
[Via Andy Oakley]
XAML, Windows Forms Markup Language (WFML), Report Definition Language (RDL), Relational Schema Definition (RSD) and Mapping Schema Definition (MSD). You get the idea what the trend is nowadays. It's all XML. What I'm wondering though - why still there is no alternative ASP.NET XML-based syntax? How long ASP.NET will stay as "almost XML"? Wouldn't it be nice an convenient? After all Java has XML-based JSP syntax since 2001.
Hey, apparently recent Opera browser beta has RSS reader embedded. Here are some screenshorts - here and here. I like that trend.
[Via 10x More Productive Blog]
Ok, I've implemented EXSLT Random module, which consists of the only function random:random-sequence() for EXSLT.NET library. Here is how it looks now:
Dare is looking for suggestions on what the tagline of the MSDN XML Dev Center (which is about two weeks from being launched) should be. I stink on naming and have almost nothing to suggest. Anyway, here are my document-centric-minded slogans:
- Marking up the world
- The universal data format
- The language information speaks
- Lingua franca of the information world
Personally I'd vote for Dare's "The language of information interchange".
Speaking of talking about unreleased technologies. Here is MHO: basically I would prefer to see more "early bird" articles and may be even releases, orienting and leading us devs on what's cooking inside the house and how it'll smell. That's important to know to build personal learning curve and usually very interesting. With usual disclaimers about volatile nature of a subject of course. The timespan till release shouldn't be too big of course. And material sould be more theory-oriented, not implementation-oriented. But still I agree that released stuff is a way more important to cover than "glimpses".
Interesting new blog at blogs.msdn.com - "C# Frequently Asked Questions", where the C# team posts answers to common C# questions. Subscribed. Why doesn't C# support default parameters? Why doesn't C# support multiple inheritance? Why doesn't C# support #define macros? Ask your question here.
Watch out for some improvements in the Workspaces bug tracker next week (Tuesday 3/16/04).
GotDotNet Workspaces are about to be updated. Improvements: better bug search, separating bugs by a custom field (such as build number), customization of bug display, ability to export bug lists to XML, file attachments. Not bad.
[Via Andy Oakley]
Great article "XQuery from the Experts: Influences on the design of XQuery" by Don Chamberlin. It's an excerpt from a chapter of "XQuery from the Experts: A Guide to the W3C XML Query Language" book. Good reading. Why relational data model doesn't fit XML, why SQL can't be used to query XML data model, basic principles that underlie the design of the XQuery language etc.
That's a milestone in XSLT technology life - the most famous Java XSLT processor Saxon goes commercial. Here is what Michael Kay (author of Saxon and XSLT 2.0 editor) writes:
In March 2004 I founded Saxonica Limited to provide ongoing development and support of Saxon as a commercial venture. My intent is to continue to produce the basic (non-schema-aware) version of Saxon as an open source product, while at the same time delivering professional services and additional modules (including a schema-aware processor) as commercial offerings.
Well, that was predicted. The complexity schema added to XSLT closes the era of one-man XSLT processors.
Another interesting quote from Mike - about Saxon processor (it's not "XSLT processor" anymore, but "collection of tools" as it supports XPath 1.0, XSLT 1.0, XPath 2.0, XSLT 2.0 and XQuery 1.0) name:
The name Saxon was chosen because originally it was a layer on top of SAX. Also, it originally used the Aelfred parser (among others); Aelfred of course was a Saxon king...
Rick Schaut writes about stupidity of the XOR trick these days:
So, not only is the XOR swap stupid because it's obscure, it's stupid because, with modern optimizing compilers, the eventual result often ends up being contrary to the intended result of using the coding trick in the first place.
The moral is, before you consider using some obscure coding trick for the sake of performance, write up some sample code, and take a look at the actual code your compiler generates. More often than not, you'll find that the less obscure method results in better code.
That great deal smells declarative programming style! Just declare what you want and let compiler do optimization tricks. +1. After years of XSLT coding and an optimizing XSLT compiler I developed once upon a time I'd say what Rick said perfectly fits XSLT/XPath/XQuery family. It's the most difficult thing when going XSLT lerning curve - to stop thinking procedurally and start thinking declratively. A common sample is alternating in XSLT - whenever you need to distinguish odd and even rows, do not go thinking about manual counting, incrementing of a variable etc. That's not the way to go. Just rely on XSLT processor and declare you are interested in even ( position() mod 2 = 0) or odd ( position() mod 2 = 1) rows.
Somehow it happened that one of the most commonly used XmlReader usage patterns ignores NameTable.
That's really unfortunate! Everybody, including Microsofties, MVPs and of course zillions of users blindly follow it, carelessly slowing down XmlReader's parsing speed.
XML.com has published good article "Using XML Catalogs with JAXP". XML Catalogs are successors of SGML Catalogs and in simple words it's a system for defining resolving of resource identifiers (URIs or Public Identifiers) in XML. If you are .NET minded - it's about having XML document (called catalog), where you declaratively define how URIs in DOCTYP, xsi:schemaLocation, xsl:include/xsl:import/document() etc should be resolved by XmlResolver. So instead of writing you own XmlResolver you declare that "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd" should be resolved as "C:/dtds/xhtml1-strict.dtd" in catalog file and get things done.
I'm sure many of you know this page, but for the rest - here is useful link to default Visual Studio .NET shortcut keys. I like this stuff. My favorite one is CTRL + TAB to navigate over opened files.
[Via Jason Mauss]
I'm going to implement EXSLT Random module for EXSLT.NET lib. It contains the only extension function:
number+ random:random-sequence(number?, number?)
The function returns a sequence of random numbers between 0 and 1 (as text nodes obviously). The first argument is number or random numbers to generate (1 by default) and the second one is a seed.
The problem is that .NET's Random class accepts seed as int, while in XPath numbers are double. So simple (I hope) question: how do you think it should be converted?
Hey, look at what Scott Woodgate writes:
Let the first ever BizTalk Server Developer Competition commence. We are giving away cash prizes totalling $25,000 USD including a huge $15,000 USD first prize. The purpose of the BizTalk Server 2004 developer competition is to highlight and reward programming excellence using BizTalk Server 2004 and Visual Studio .NET.
Complete details here.
How cool is that?
Yeah, that's cool, Scott. I'm going to participate! Timing is till August 31, enough time to get accustomized to BizTalk 2004 RTM, which by the way was released just today and is ready for MSDN subscribers.
Dare writes:
We were planning to add support for xml:base to the core XML parser as part of implementing XInclude but given that that it recently went from being a W3C candidate recommendation to going back to being a W3C working draft (partly due to a number of the architectural issues raised by Murata Makoto) the future of the spec is currently uncertain so we've backed off on our implementation.
Yeah, XInclude makes its tangled way to the Recommendation status really slowly. It's been CR for a long time and even there were some slips about PR, but then it's been backed off to WD soapbox again. These days XInclude is ready to climb up again. Many architectural issues have been fixed, syntax and semantics have been modified with respect to the Web architecture, there are enough full implementations for all major platforms (.NET, Java, C). And here is what Jonathan Marsh writes today in www-xml-xinclude-comments@w3.org maillist:
We believe this is resolution completes our resolution of outstanding
issues on XInclude, and we plan to release a new CR draft soon.
By the way, I wrote an article about XInclude and XInclude.NET and hope it'll be published soon.
Meantime some of you guys sent me logos for the XInclude.NET logo contest. Thanks! I'm going to arrange a page with a poll to see public opinions.
At last some good news. Streaming subset of XInclude I was talking about gets blessing from the W3C XML Core WG. Here is what Jonathan Marsh (MSFT, editor of XInclude) writes:
It appears to be impossible to improve streamability without removing
functionality from XInclude. The WG decided instead to bless a kind of
"streamable subset" by adding text along these lines:
_______
The abscense of a value for the href attribute, either by the appearance
of href="" or by the absence of the href attribute, represents a case
which may be incompatible with certain implementation strategies. For
instance, an XInclude processor might not have a textual representation
of the source infoset to include as parse="text", or it may be unable to
access another part of the document using parse="xml" and an xpointer
because of streamability concerns. An implementation may choose to treat
any or all absences of a value for the href attribute as resource
errors. Implementors should document the conditions under which such
resource errors occur.
_______
New version of XInclude spec is going to be published soon. As they are slightly changing syntax again (removing accept-charset attribute), I think it will be Working Draft again.
 Well, I know I stink on graphics. Yesterday I tried to develop a logo for the XInclude.NET project and here is what I ended up. The idea was about Lego and intergration or parts into a round thing, whatever. Well, I know I stink on graphics. Yesterday I tried to develop a logo for the XInclude.NET project and here is what I ended up. The idea was about Lego and intergration or parts into a round thing, whatever.
I'd like to hear what do you guys think about this logo?
I'm personally not really satisfied with it and I doubt I can make it better, so let's have a logo contest. You send me your logo variants (find my email in top right corner of this page), I put them to some page and after some time we vote for a winner logo.
Prize? Well, XInclude.NET project doesn't have sponsors, so we can't afford anything more valuable than "The logo design by" line in every bit of XInclude.NET documentation and of course a pile of eternal gratitude.
When your hard disk dies Monday morning, that's nice week start. Low type tasks on recovering your data, sources, reinstalling and configuring all the stuff you cannot work without... Refreshing.
Basically I've recovered already. Surprisingly I cannot now install Office 2003, it says "You've got McAffee VirusScan Enterprise installed, Office 2003 Pro cannot be installed on the same machine with that crap." Hmmmm... Anybody seen that? I failed to google any workarounds.
Dummy entry to provide single place for nxslt.exe utility comments.
"XQuery 1.0 and XPath 2.0 Formal Semantics" spec has been updated today and reached Last Call Working Draft status. This is a document you may want to read to get deep understanding of semantics of XQuery 1.0 and XPath 2.0 languages:
This document defines the semantics of [XPath/XQuery] by giving a precise formal meaning to each of the expressions of the [XPath/XQuery] specification in terms of the [XPath/XQuery] data model. This document assumes that the reader is already familiar with the [XPath/XQuery] language.
Comments are due by 15 April 2004.
Here is what Michael Kay (XSLT star, developer of Saxon, author of every-XSLT-dev-bible "XSLT Programmer's Reference" and XSLT 2.0 editor) writes about XQuery:
The strength of XQuery is that it is a simpler language than XSLT, which
makes it much more feasible to implement efficient searching of very
large XML databases.
Its other strength is that for simple problems, the XQuery code is much
shorter than the XSLT code.
But for complex manipulation of in-memory XML, I would use XSLT every
time, regardless of whether you're dealing with "data" problems or
"document" problems.
Do you agree with him?
RenderX, a company behind famous XEP XSL-FO formatter plans to release a .NET version. Great news! XEP is the best production quality Java XSL-FO formatter I've ever seen. It's not unexpensive, but it covers XSL-FO a way better than free Apache FOP (I have to add "unfortunately", being one of FOP committers).
XEP.NET is an XSL-FO formatter component for .NET,
capable of producing PDF and PostScript from XSL-FO
data. The product is based on a proven Java core, and is
fully identical in functionality to the latest Java version.
The software is 100% manageable .NET code: no native
libraries are used. It exposes standard .NET interfaces
for XML processing (XmlReader and XmlWriter).
Additionally, classes for smooth MSXML integration
are included, with source code.
The package also includes a command-line utility and
a simple GUI tool to run XSL-FO formatting.
Requirements:
Windows 2000/XP;
.NET Framework 1.1 or higher;
Visual J# Redistributable 1.1 or higher. Seeing J# in prerequisites I can assume they have ported Java code into J# actually. Why not?
Meanwhile RenderX is looking for beta testers.
BizTalk Server 2004 will launch on March 2, 2004.
At last!
And to get us to speed up 8 BizTalk 2004 MSDN webcasts are arranged between March 2 and March 5!
Here is the first developer treat: As part of the launch there will be an MSDN BizTalk Server Developer Blitz with no less than eight web casts packed with information from 3/2 to 3/5. These sessions are developer orientated, full of demos and guarranteed to get you up to speed. Get your own mini-Teched on BizTalk Server for the attractive price of $0 and delivered to you in the comfort of your office/home on the same week we launch the product. Don't forget to register now - these sessions will likely full up fast.
[Via scottwoo.]
Worth to get registered now.
I've updated my XML Bestiary as a consequence of users and my own feedback. First of all I renamed WritableXPathNavigator to SerializableXPathNavigator. That's much less confusing name IMO. Beside that I unified all distributions (the same namespace, project structure etc). More beasts to come soon, I've got several growing up in an incubator.
It's definitely love-to-steaming-strikes-back day today. Here is another sample of how streaming XML processing approach fails.
The only XInlcude feature still not implemented in XInlcude.NET project is intra-document references. And basically I have no idea how to implement it in .NET pull environment (as well as Elliotte Rusty Harold has no idea how to implement it in his SAX-based implementation). What's the problem?
Meanwhile I managed to create simple dummy online demo of ForwardXPathNavigator (XPathNavigator implementation over XmlReader) I was talking about. Here it is.
Here is Daniel clarifies things about XSE:
XSE is not about querying with an specific expression language/format (i.e. XPath or SXPath). XSE is just a mechanism for encapsulating state machines checking for matches against a given expression. What the expression looks like depends on the factory that creates the strategy.
Therefore, the factories I showed (i.e. my RootedPath and RelativePath) are only encapsulating code generation for different FSMs, based on an expression language that fits a need. Therefore, I could even create a factory implementing SXPath and still remain in Xml Streaming Events land.
The XSE idea is to provide a callback metaphor to XML parsing, instead of the pull-model of the XmlReader. In fact, it's a sort of evolution over SAX, in that at the same time it offers both worlds: pull model directly from the XseReader, events-based for your registered handlers.
Now that's finally clear to me. And the approach starts to delight me. Really, really not bad. I need to dig around it before I can say some more.
Looks like Microsoft's patenting its XML investments. Recently we had a hubbub about Office 2003 schemas patenting, then XML scripting. Daniel like many others feel alarm, you too?
Well, I'm not. Patenting software ideas is stupid thing, but that's a matter of unperfect reality we live in. Everything is patented nowadays, right up to the wheel. So if Office XML is gonna be patented I prefer it's being patented by Microsoft. After all they are not interested to close it (aka make it die), instead they made Office schemas Royalty-Free. And one more reason - I'm sure all we don't want to find ourself one day rewriting all Office-based solutions just because of another Eolas scrooge case or even to pay for out-of-blue-license to some other litigious bastards.
That's all sounds reasonable if that's really defensive patenting though, otherwise - be prepared.
Michael Brundage's excellent XQuery reference book is finally available.
[Via Michael Rys]
 Dr. Rys is talking about just published (February 2004) "XQuery : The XML Query Language" book. Dr. Rys is talking about just published (February 2004) "XQuery : The XML Query Language" book.
Michael Brundage is Technical Lead for XQuery processing at Microsoft and the recommendations are so weighty... I feel I want this book too.
Ok, Dare great deal clarified things in his "Combining XPath-based Filtering with Pull-based XML Parsing" post:
Actually Oleg is closer and yet farther from the truth than he realizes. Although
I wrote about a hypothetical ForwardOnlyXPathNavigator in my article entitled Can
One Size Fit All? for XML Journal my planned article which should show up
when the MSDN XML Developer Center launches in a month or so won't be using it. Instead
it will be based on an XPathReader that is very similar to the one used in BizTalk
2004, in fact it was written by the same guy. The XPathReader works similarly
to Daniel Cazzulino's XseReader but uses the XPath subset described in Arpan Desai's Introduction
to Sequential XPath paper instead of adding proprietary extensions to XPath
as Daniel's does.
I've released nxslt.exe utility version 1.4. It's maintenance release. Changes are:
- Updated to EXSLT.NET 1.0.1.
- Updated to XInclude.NET 1.2.
- Updated project to Microsoft Visual Studio .NET 2003 (so now nxslt.exe can be built directly from VS.NET, no need to run nmake manually - EXSLT methods renaming such as nodeSet() to node-set() is done in postbuild script now).
- Binary download includes three nxslt.exe versions (compiled for .NET 1.0, 1.1. and 1.2).
- Usage header now indicatas what's .NET runtime nxslt.exe is running under:
.NET XSLT command line utility, version 1.4 (Running under .NET 1.1)
The rule is simple - nxslt.exe requires .NET Framework it's compiled for. By default nxslt.exe is compled for .NET 1.1 and thus can't run under .NET 1.0. Instead use nxslt-.NET1.0.exe version (feel free to rename it too). For testing .NET 1.2 use nxslt-.NET1.2.exe version.
No need to say, I appreciate any comments|critics|suggestions|donations|not(spam).
Not too much, right. For the next nxslt.exe release (March probably) I'm going to implement basic XSLT profiling, tracing and may be rudimentary debugging functionality. Stay tuned.
Daniel writes about performant (and inevitably streaming) XML processing, introducing XSEReader (aka Xml Streaming Events Reader). While he didn't publish the implementation itself yet, but only teasing with samples of its usage, I think I get the idea. Basically I know what he's talking about. I've been playing with such beasts, making all kinds of mistakes and finally I came up with a solution, which I think is good, but I didn't publish it yet. Why? Because I'm tired to publish spoilers :) It's based on "ForwardOnlyXPathNavigator" aka XPathNavigator over XmlReader, Dare is going to write about in MSDN XML Dev Center and I wait till that's published.
It's been Microsoft DevDays 2004 in Israel today. Well, DevDay actually. Here are the impressions I got there:
- One has to get up earlier to not miss the keynote.
- VS.NET has cool PocketPC emulator.
- Code Access Security is omnipotent.
- Lutz Roeder's .NET Reflector may hang out in the middle of a presentation.
- WS-Security is great and Yosi Taguri is bright speaker, but he scrolls code too fast.
- Zero Deployment is amazingly simple.
- They are really anxious about security nowadays. All attendants have been given "Writing Secure Code" book for free. Aaah, bookworm's joy. "Required reading at Microsoft. - Bill Gates" is written on the book's front page.
This interesting trick has been discussed in microsoft.public.dotnet.xml newsgroup recently. When one has a no-namespaced XML document, such as
<?xml version="1.0"?>
<foo>
<bar>Blah</bar>
</foo>
there is a trick in .NET, which allows to read such document as if it has some default namespace:
<?xml version="1.0"?>
<foo xmlns="http://foo.com">
<bar>Blah</bar>
</foo>
I'm introducing another category in my blog - XML Tips and Tricks, where I'm going to post some XML, XPath, XSLT, XML Schema, XQuery etc tips and tricks. I know, many of my readers being real XML gurus know all this stuff (I encourage to correct me when I'm wrong or proposing better versions though), but I hope it would be interesting for the rest and may attract new readers.
Here is the first instalment - conditional XPath expressions.
Dare has been talking recently about the disconnects developers may feel once they make the shift from tree based (XmlDocument) to cursor based (XPathNavigator) model. My personal XML learning curve has started with DOM (I remember those long convolute ugly DOM navigational programs I wrote back in Y2K), then I fell in love with SAX and only then I became XmlReader and XPathNavigator fan. But despite the fact I'm probably not an average developer (as I spend most of my time dealing exclusively with XML) I can feel the disconnect too. DOM is kinda ground zero for many of us and not feeling it underfoot is a bit like flying in zero-gravity. Hurts at first, but fun and cool once you get used to it. I think that's not by accident DOM implemenation in .NET has been named XmlDocument, that reflected some basic attitude at that time, although some of us believe now DOMDocument was a better name.
Anyway, here is my small humble contribution to XPathNavigator appreciation - SerializableXPathNavigator. It's really small wrapper around XPathNavigator, which extends it adding InnerXml/OuterXml properties and WriteTo()/WriteContentTo() methods. That's unfortunate omission XPathNavigator doesn't have such fuctionality in .NET 1.0/1.1 and this fact adds some degree to the discronnect devs feel, because devs do like OuterXml and use it frequently. It's fixed in .NET 2.0, but till then I propose this implementation.
Here is local copy and here is GotDotNet's copy. Free and open source of course.
Usage pattern:
XPathDocument doc = new XPathDocument("books.xml");
XPathNavigator nav = doc.CreateNavigator();
XPathNodeIterator ni = nav.Select("/catalog/book[title='Creepy Crawlies']");
ni.MoveNext();
SerializableXPathNavigator snav = new SerializableXPathNavigator(ni.Current);
Console.WriteLine(snav.OuterXml);
Console.WriteLine(snav.InnerXml);
Couple of details - SerializableXPathNavigator is XPathNavigator itself, which wraps another XPathNavigator and exposes the following additional members:
OuterXml - gets the XML markup representing the current node and all its child nodes.
InnerXml - gets the XML markup representing only the child nodes of the current node.
WriteTo(XmlWriter) - saves the current node to the specified XmlWriter.
WriteContentTo(XmlWriter) - saves all the child nodes of the current node to the specified XmlWriter.
Implementation details - see sources.
Hope you can find it useful. As usual I appreciate any comments/bugs/critics.
Did you know XslTransform class allows custom XmlResolver to return not only Stream (it's only what default XmlResolver implementation - XmlUrlResolver class supports), but also XPathNavigator! Sounds like undeservedly undocumented feature. What it gives us? Really efficient advanced XML resolving scenarios such as just mentioned recently on asp.net XML forum - getting access to XML fragments from within XSLT. Or looking up for cached in-memory XML documents. Or constructing XML documents on the fly for XSLT, e.g. via accessing SQL Server database from within XSLT stylesheet and processing the result. Well, part of it could be done also with XSLT parameters and extension functions, but XmlResolver is more powerful, flexible and elegant approach.
Here is a sample XmlFragmentResolver, which allows XSLT to get access to external XML fragments (XML fragment aka external general parsed entity is well-formed XML with more than one root elements):
public class XmlFragmentResolver : XmlUrlResolver
{
override public object GetEntity(Uri absoluteUri, string role,
Type ofObjectToReturn)
{
using (FileStream fs = File.OpenRead(absoluteUri.AbsolutePath))
{
XmlTextReader r = new XmlTextReader(fs,
XmlNodeType.Element, null);
XPathDocument doc = new XPathDocument(r);
return doc.CreateNavigator();
}
}
}
Don't forget to pass its instance to Transform() method (in .NET 1.0 - set it to XslTransform.XmlResolver property):
xslt.Transform(doc, null, Console.Out, new XmlFragmentResolver());
And here is how then you can access XML fragments from within XSLT:
<xsl:apply-templates select="document('d:/temp/fragment.xml')/*"/>
Note, that instead you can load XML fragment and pass it as a parameter, but then you should know statically in advance all XML fragments/documents XSLT would ever require. XmlResolver approach allows XSLT to take over and access external documents or fragments really dynamically, e.g. when a file name cannot be known prior to the transformation.
One of consequences of the revolutionary XML support in Microsoft Office 2003 is a possibility to
unlock information in the Microsoft Office System using XML. Most likely that was deliberate decision to open Office doors for XML technology and I'm sure that's winning strategy.
Talking about transforming WordprocessingML (WordML) to HTML, what's the state of the art nowadays?
There are two related activities I'm aware of, both Microsoft rooted. First, it's "WordML to HTML XSL Transformation" XSLT stylesheet available for download at Microsoft Download Center. It's huge while well documented while unsupported beta XSLT stylesheet, which transforms Word 2003 Beta 2 XML documents to HTML. Its final release, which will also support images is expected, but who knows when?
Second, Don Box is experimenting with Wordml2XHTML+CSS transformation, mostly for the sake of his blogging workflow. He said his stylesheet is better (less global variables etc.). Apparently Don didn't finish it yet, so the stylesheet isn't available.
So one stylesheet is only for Word 2003 Beta 2 documents, second isn't ready yet, sounds bad, huh? Here is my temporary solution - original "WordML Beta 2 to HTML XSL Transformation" stylesheet fixed by me to support Word 2003 RTM XML documents. As usually with Microsoft stuff, "beta" most likely is 99% RTM version. So I fixed Beta 2 stylesheet a bit and it just works. In fact that's only namespaces that I fixed yet. I'm currently testing the stylesheet with big real documents, so chances are I'll need to modify it further.
Download version 1.0 of the stylesheet here - Word2HTML-1.0.zip. Credits due to Microsoft and personally to whoever developed the stylesheet. Any bug reports or comments are appreciated. Just post comment to this text.
Another idea is to implement support for images. Basically the idea is to decode images and save them as external files in XSLT external function and I don't see how to make it in portable way, so most likely I'll end up soon with two stylesheet versions - for MSXML and .NET. Stay tuned.
Six Apart has announced MovableType 3.0 Alpha testing is about to begin. Testers such as plugin developers, web standards advocates or just Movable Type users with an active commenting community are invited. Here is a list of upcoming MT 3.0 features.
I keep getting 5-10 spam comments a day, so sure I'd like to test comment registration system.
Have you noted this thread in microsoft.public.dotnet.xml newsgroup? A guy was trying to get list of unique values from XML document of 46000 records. Using Muenchian grouping method. For MSXML4 it took 20 seconds, while in .NET 1.0 and 1.1 it effectively hung. Well, as all we know Muenchian method works deadly slowly in .NET unfortunately. MSXML4 optimizes generate-id($node1) = generate-id($node2) expression by making direct comparison of nodes instead of generating and comparing ids. .NET implementation isn't so sophisticated. Emerging .NET 1.1 sp1 is going to make it faster, but what's today's solution?
Enter EXSLT.NET's set:distinct() extension function. Using it the result was:
695 unique keys generated from about 46000 records in less
than 2 seconds.
Now that's really amazing. Ten times faster than MSXML4! And much more understandable - just compare these expressions:
set:distinct(atl_loads/atl_load/client_key)>
and
atl_loads/atl_load/client_key[generate-id(.) =
generate-id(key('client_key_lkp',client_key)[1])]
Special kudos to Dimitre Novatchev for optimizing EXSLT.NET set functions.
MVP list was updated this night to reflect recent awards. Now it's 13 XML MVPs. It's nice to see the number (IMHO rough analogue of importance and appreciation within MSFT and the community) is growing. Meanwhile I've started to enjoy MVP benefits :) I didn't explored all yet, being lost in private universe of MVP newsgroups, wow! Other details are probably NDAed, but in simple words - it's worth to be MVP.
MSDN starts new Data Access & Storage Developer Center, msdn.microsoft.com/data, "the home for developer information on Microsoft data technologies from MSDN" (via Chris Sells). Great, worth to subscribe. List of related bloggers (indispensable attribute of any portal nowadays) - http://msdn.microsoft.com/data/community/blogs. Stars like Dino Esposito, Mike Gunderloy, Andrew Conrad, Michael Rys, Dare Obasanjo and Christa Carpentiere (the editor of this Dev Center) are amongst them. I bet Data Access & Storage Developer Center's gonna rock. Smart people plus great technology, a perfect match.
I wonder whether XML Developer Center is next on the MSDN launch pad and who will be on the editor chair?
Looks like everyone but I knows it. I stumbled at Mike Gunderloy's "Working with Microsoft Office 2003 Documents and Web Services" article at OfficeZealot.com illustrating how to use INCLUDETEXT field in Word 2003. Very nice feature! Here is how it looks like for XML nerd, newbie in Word.
INCLUDETEXT field allows to have updatable field in Word 2003 document, which content is included from another document. It's actually implementation of Insert/File feature. Word 2003 Pro edition even allows partial inclusion (via XPath selection) and XSL transformation before the inclusion. Cool. It's a pity looks like it works only in Pro edition.
Here is how it looks line in WordML:
<w:p>
<w:fldSimple w:instr="INCLUDETEXT
"D:\\Temp\\books.xml" \c XML
\x /catalog/book[1]/title \* MERGEFORMAT">
<w:r>
<w:t>Included content</w:t>
</w:r>
</w:fldSimple>
</w:p>
Well, not really XMLish, but anyway. w:instr contains field's instruction text. Above instruction means "include value of /catalog/book[1]/title element from D:\\Temp\\books.xml document". Nested w:r (or other run-level elements) holds included content. Word doesn't update fields authomatically, even during document loading. Updating should be done by user from the context menu (or it can be done in code).
w:fldLock attribute can be used to prevent updating of the field.
It's text inclusion, not transclusion (when context info such as style is preserved). Inclusion of WordML elements actually works, but looks like styles and other metainformation isn't preserved, so basically you can for instance include first paragraph from another WordML doc, but without the style etc. Anyway, that's good idea to include code samples into a Word document this way, then you can modify code and onlly update fields in Word. Here is how XML samples could be included:
<w:fldSimple w:instr="INCLUDETEXT
"D:\\Temp\\books.xml" \c PCText">
Without \c PCText XML will be included as XML and shown with graphical tags.
Well, it's Sunday. Calm and peace around newsgroups, forums and blogs. But in Israel it's workday, really. And I like it btw. RSS waves brought me today really enjoyable reading - MSDN Mag February 2004 issue. Nice. Here are couple of cynical comments though:
"Console Appplications in .NET" by Michael Brook.
I'm console-oriented guy too and my first .NET application was nxslt.exe command line utility for running XSLT (in fact I rarely run it in real command prompt, using as external transformer in XML Spy instead). But I'm not so wacky as Michael is! What he is showing in the article is "the world's first command-line RSS reader". Well, it's really hard to think up good samples for an article...
"Comparing the Timer Classes in the .NET Framework Class Library" by Alex Calvo.
I didn't realized there are three different timer classes in .NET FCL - System.Windows.Forms.Timer, System.Timers.Timer and System.Threading.Timer. Good to know. Here is a summary comparison table.
"WEB Q&A", Nancy Michell is still not aware of XInclude way for combining XML documents. Too bad, DTD sucks on combining loosely coupled documents. XSLT doesn't, but hurts perf. XInclude is the way to go.
"XML in Yukon. New Version Showcases Native XML Type and Advanced Data Handling" by Bob Beauchemin.
It's excerpt from upcoming "A First Look at Microsoft SQL Server "Yukon" Beta for Developers" book. Good intro. Here are some perls:
The introduction of this native XML data type, coupled with the emerging industry standard XQuery language, should spark a revolution in database application development.
I'm pessimistic on that. I hope for some changes, but not a revolution. And do we really need another revolution?
Having XML data inside a relational database may offend some relational purists, but it means that your data lives in a single repository for reasons having to do with administration, reliability, and control.
Hehe, poor relational purists, it's time to think XMLish.
In addition to the query capabilities of XPath, XQuery allows element and attribute construction via XSLT.
WTF? I'm sure it should be "like XSLT".
"The XQuery Designer in Action" - cool. Now I'm dying to give it a shot.
Breaking news: Aaron Skonnard is blogging! (Via Carnage4Life). A must feed for every XML geek.
Well, another wave of MVP awards spreads these days. Now I got it too. In XML area of course. Thanks to all who supported me. Thanks to MVPs who nominated me.
I see two more XMLers - DonXML and Daniel Cazzulino have been awarded too. Congrats, guys!
Update: another XmlInsider, Jeff Julian has been MVPed too. Congrats Jeff!
One more update: one more XmlInsider, Dimitre Novatchev is on board too!
Mike Gunderloy:
Coder to Developer - One of the books that is almost done, though you'll have to wait a few months to get a copy.
Amazon:
Coder to Developer: Tools and Strategies for Delivering Your Software
by Mike Gunderloy, Sybex (Publisher)
Book Description
Are you ready to take the leap from programmer to proficient developer? Based on the assumption that programmers need to grasp a broad set of core skills in order to develop high-quality software, "From Coder to Developer" teaches you these critical ground rules. Topics covered include project planning, source code control, error handling strategies, working with and managing teams, documenting the application, developing a build process, and delivering the product.
Hmmmm... Mike Gunderloy, "proficient developer", "high-quality software"... Yeah, I need this book.
Priscilla Walmsley, author of great "Definitive XML Schema" announced a new book, now about XML in Office 2003:
I'm pleased to announce the release of XML in Office 2003: Information
Sharing with Desktop XML, a book that I co-authored with Charles Goldfarb.
It can be found on Amazon at:
http://www.amazon.com/exec/obidos/ASIN/013142193X/priscillawalm-20
The book was designed to help the "power user" take advantage of the new
XML-related features of the Office suite (including InfoPath). It does this
by breaking down the functionality into tasks, like "Rendering and
presenting XML documents" and "Using Web services with spreadsheets", etc.
It also has a section of tutorials that cover XML-related technologies like
XSLT, XML Schema and Web services.
I'd be very interested in feedback.
Looks really tempting...
Somehow many believe it's impossible to get OuterXml/InnerXml out of XPathNavigator, but in fact it's merely one-screen-of-code class. And by the way, in System.Xml v2 XPathDocument2 class does have such properties already.
So I've written a small class, which exposes this omitted functionality. It's lightweight wrapper around XPathNavigator, which adds two more properties - OuterXml and InnerXml along with two more methods - WriteTo(XmlWriter) and WriteContentTo(XmlWriter).
Now the question is how to name such class. All names I came up - WritableXPathNavigator, SerializableXPathNavigator or even XPathNavigatorWriter sound too confusing. I'm asking for community help here, any ideas, please guys.
MovableType version 2.661 has been released. The release aimed completely to fix spam comments problem. New anti-spam weapon includes:
We've included a throttling measure so that comments from the same IP address can only be posted every N seconds, where N is configurable (documentation on the setting that controls N).
Gooooood!
We've also added a measure to automatically ban an IP address based on an abnormal number of comments from the same address in a short period of time.
Sweet!
Of course, there are no perfect defenses, and if you're truly concerned about the comments on your weblog, the best defense is prevention by closing old comment threads.
Actually I was thinking about closing comments on old postings, but I'm still not sure I want it. I like (real, not troll/spam) comments too much, that's the feedback I really need.
Also in 2.66, we've changed the behavior of <$MTCommentAuthorLink$> to use redirects when linking to URLs given in comments. The goal of this is to defeat the PageRank boost given to spammers by posting in the comments on a weblog.
Also interesting one. Hope it'll help. Well done, Six Apart! Upgraded my blog as usual smoothly in just one minute. Unfortunately this pack of anti-spam fixes didn't include my favorite one - "Delete this post" link in notification mail. This small (3 lines of Perl) patch includes "Delete this post" link into new comment notification mail. So whenever MT notifies me on new comment posted and I see it's viagra ad I can delete it in just one click. Ok, patched new release again, no big deal.
Now I only wait for the next spam attack to see what happens...
In the beginning Microsoft created the Microsoft.XMLDOM, known today as Msxml2.DOMDocument. And people like(d) it much. Then .NET happened and people were given XmlReader, XmlWriter, XmlDocument, XPathDocument, XPathNavigator and XmlDataDocument. Surprisingly most of us stuck to XmlDocument for no-matter-which scenario. Now we've been notified the Gods decided to kill XmlDocument and glorify XPathDocument instead. Be prepared...
Seriously, why XmlDocument is so overused? I think there are several reasons, from psychological to usability-related ones.
- For anybody with MSXML experience DOM is the obvious choice. DOM was the only data store in MSXML and the API. It's my understanding that MSXML SAX is almost only used by memory-anxious nerds. No surprise anybody with MSXML background coming to .NET takes XmlDocument with no any doubts. Such situation just cannot be changed quickly.
- XmlDocument is editable, XPathDocument is readonly. Unbeatable now, but System.Xml v2.0 gonna change it.
- XmlDocument API is simpler and more natural WRT MSXML background than XPathDocument's one in many common usage scenarios such as selecting a string value, especially it strikes the eyes when namespaces involved:
XmlNamespaceManager nsmgr = new XmlNamespaceManager(doc.NameTable);
nsmgr.AddNamespace("foo", "http://foo.com");
string val = doc.SelectSingleNode("/foo:bar/text()", nsmgr).Value; vs
XPathNavigator nav = doc.CreateNavigator();
XPathExpression expr = nav.Compile("/foo:bar/text()");
XmlNamespaceManager nsmgr = new XmlNamespaceManager(nav.NameTable);
nsmgr.AddNamespace("foo", "http://foo.com");
expr.SetContext(nsmgr);
XPathNodeIterator ni = nav.Select(expr);
ni.MoveNext();
string val = ni.Current.Value;
- XmlDocument exposes nodes, XPathDocument - cursor based API (but uses XPathNode's internally). Developers somehow like being able to select a node from document, dunno, may be it gives some secure non-virtual feelings to them?
- XmlDocument is closer to XML syntax level than XPathDocument. Developers like to work with XML declarations, entities, CDATA and OuterXml. They feel good when data store reflects XML syntax they see in Notepad. Don't ask me why.
- Developers don't care about perf. Sometimes they complain instead.
Well, we can do nothing with first and the last issues. System.Xml v2 will fix 2nd issue. Additionally XPathDocument will be improved with XSD types support, changes tracking, ability to validate, to reflect relational data via XmlAdapter etc. I'm sure they will make API more simple for ordinar developer too. In fact, System.Xml v2 gonna rock! So the only issue to cope with is community-wide DOM habit. How to kill it? I believe only with improving alternative APIs, leaving it out of XQuery-related future mainstream and evangelizing-evangelizing-evangelizing... Last task should be taken by XmlInsiders.
Btw, did you know that "dom" word means "home" in Russian?
Mark Pilgrim started a new wave of permathreding by "There are no exceptions to Postel's Law" rant arguing even malformed RSS feeds should be accepted.
I'm strongly on opposite side. Accepting malformed XML - what a heresy! My understanding of Postel's Law a bit differs. "Liberal" in "be liberal in what you accept from others" means different formats/versions/encodings, possibly obsolete and rarely used, but by no means malformed/broken/compromised.
Don Box talks about his weekend hobby - getting XHTML+CSS from WordML. Using XSLT of course. And it works - Don bloggs in Word, publishing in XHTML. Resulting HTML is not optimal yet (see page source), but perfectly proves the concept.
Well, as per Don WordML and XHTML are twins separated at birth:
Our chat confirmed for me that WordML and XHTML+CSS are more alike than they are different.
Both use a fairly small number of structural markup elements and use annotations on those elements to influence formatting.
But there are reasons WordML to XHTML+CSS transformation isn't trivial enough. These are non-semantic WordML nature (no semantic markup at all or wacky lists as another example), different whitespace handling, styles inheritance and tabs. I'm sure there is much more differences over there we still don't see.
Anyway I fully agree with Don in his conclusion - WordML is just another XML vocabulary and its processing, such as generation, aggregation, querying or transformation is as easy as processing any other XML. With one small attached string - "Provided we know and understand WordML well enough."
Talking about lists. I really didn't realize lists in WordML are designed to be easily rendered. For Word rendering engine it doesn't matter a paragraph is a list item - it can just process w:listPr and rendering done. My semantically-oriented mind resist to swallow it, but it's naked truth. WordML isn't designed to be semantic document markup language like Docbook or XHTML are, it's completely different, anti-semantic, fully presentational vocabulary, designed to be easlily rendered by Word rendering engine. But XML is XML and processing of WordML is not actually different from processing Docbook. Everything is possible in XML.
Chris Lovett has released SgmlReader version 1.2. It's mostly bug fixes release.
Via Dare Obasanjo aka Carnage4Life
SgmlReader is an XmlReader, which is able to parse SGML documents (e.g. HTML).
I'm writing this entry to illustrate basics of generating lists in WordprocessingML documents using XSLT. Also I want to test how my office-related rants are syndicated by the wonderful OfficeZealot.com site.
[Prerequisites: Make sure you've read what "Overview of WordprocessingML" says about lists].
Basically a list in WordprocessingML consists of list format definition (<w:listDef>), list instance definition (<w:list>) and list items. A list item is just specially attributed paragraph. More formally - any paragraph with <w:listPr> element in <w:pPr> element is considered to be a list item. It works this way - list item refers to list it belongs to, while list definition refers to list format definition. List formats and list instances are defined within <w:lists> element, which is child of <w:wordDocument> element. Thus there are no list boundaries structurally, instead list items refer to a list they belong to by list ID.
It seems reasonable once you grasp it. Ok, list definitions. Here s a sample, which defines single list format (#0) and single list (#1):
As can be seen, <w:listDef> defines formatting properties for three levels. Beware - that's important that you've got defititions for all list levels your document might contain, otherwise Word won't display list item as list item. By default Word defines 8 levels for each list format. Then <w:list> element defines list instance, binding it to list format defnition in <w:ilst> element. Done with definitions, now here is a list item:
<w:p>
<w:pPr>
<w:listPr>
<w:ilvl w:val="0"/>
<w:ilfo w:val="4"/>
</w:listPr>
</w:pPr>
<w:r>
<w:t>List item text</w:t>
</w:r>
</w:p>
It's an item, which belongs to 0 level of a list number 4.
Now how this stuff can be generated in XSLT? First of all obviously you need to generate format definitions for all types of lists you gonna have in a document - ordered, unordered etc. Then you need to generate list instance definition for each list in your document, bound to appropriate format definition. And finally generate list items, refering to the nesting level and list instance they belong to. Sounds piece of cake, huh?
Let's say I have an article in my proprietary XML format (similar to XHTML though to be realistic):
And here is my stylesheet, which transforms the article into WordprocessingML document:
Ok, what's inside? You can see definitions of two list formats - first for unordered list and second for ordered. Then I generate instances of lists for each list in source XML uniquely numbering them. And finally for each list item I generate paragraph with <w:listPr> property, where I define nesting level (count(ancestor::ul|ancestor::ol)-1) and ID of the list instance it belongs to. A bit not trivial, but only a bit. Here is the result:
Well, lists in WordprocessingML are a bit tricky. First of all it's quite unusual to have no structural list borders. Lists are defined in document header, while list items are within document body. Hence a lot of indirection. Enables great deal of flexibility, hard to grasp though. Then naming of elements and attributes is confusing (can you say out of hand what w:ilfo or w:ilst means?). But having strong understanding of WordprocessingML you can easily generate them using XSLT. At least I hope that's the feeling you've got finishing reading this text.
Happy New Year to everybody my dear readers!
Now back to mundane things. Yesterday for the first time my blog has been seriously attacked by evil comment spammer. Last months I got used to receive 6-7 spam/troll comments a week and remove them out weekly, but this guy(application?) has sent 70 comments full of (200+) crap links during half an hour till I occasionally noted unusual activity and banned his IP.
Well, MovableType really sucks on comment spam. The only defence facility is manual IP banning. MT 3.0, whose beta is expected in Q1 2004 should make things better, they have announced it will include comment registration and improved comment management among other features. Well, I'm looking forward to see it.
Meanwhile reading discussion on comment spam in Sam's blog I realized there are really interesting ideas on detecting/blocking spam/troll comments I'd also like to try to implement myself. Unfortunately MT is perl-based engine, so the only my oprions are: learn perl or to implement frontend for MT comment subsystem in .NET. Bad ideas both. It's only now I finally see why Don Box is writing his own blog engine.
I don't dare to follow this way, but switching to .NET-based blog engine, such as dasBlog looks evem more tempting now.
|
|



Recent Comments