2003 Archives
Here is small HOWTO on exposing comments to MovableType-running blogs to RSS readers.
Note: Target MT versions are 2.64 and 2.65, I'm not sure about other ones.
Intro
The goals of exposing comments are: enabling for arbitrary RSS reader application to see comments made to blog items and to post new comments. There are several facilities developed by RSS commutity, which allow to achieve these goals:
- <slash:comments> RSS 2.0 extension element, which merely contains number of comments made to the specified blog item.
- RSS 2.0 <comments> element, which provides URI of the page where comments can be viewed and added (it's usually something like http://yourblog/cgi-bin/mt-comments.cgi?entry_id=blog-item-id in MT blogs).
- <wfw:commentRss> RSS 2.0 extension element, which provides URI of comment feeds per blog item (to put it another way - returns comments made to specified blog item as RSS feed).
- <wfw:comment> RSS 2.0 extension element, which provides URI for posting comments via CommentAPI.
Step 1. Exposing number of comments made to a blog item
The simplest one. Number of comments made to the current item is available via <$MTEntryCommentCount$> MT template tag. Obviously it must be used within <MTEntries> tag, which iterates over blog items:
<MTEntries lastn="15">
<item>
...
<slash:comments><$MTEntryCommentCount$></slash:comments>
...
</item>
</MTEntries>
Don't forget also to bind "slash" prefix to "http://purl.org/rss/1.0/modules/slash/" namespace URI.
Step 2. Linking to "comments to this item" page
Again simple one. MT provides enough template tags to construct URI of the Web page, where one can view and add comments. These are <$MTCGIPath$>, <$MTCommentScript$> and <$MTEntryID$>:
<MTEntries lastn="15">
<item>
...
<comments>
<$MTCGIPath$><$MTCommentScript$>?entry_id=<$MTEntryID$>
</comments>
...
</item>
</MTEntries>
Step 3. Exposing comments as RSS feeds
The idea is to generate separate RSS document for each blog item, which contains comments made to this item. This can be done in the same way as MT generates HTML file for each item and rebuilds it whenever a comment is made. One need to provide a template for such file and register it properly in MT admin. Here is a template:
To install in into MT blog: click on "Templates" in main blog admin menu, click on "Create new archive template" link, type "Individual Comment RSS archive" in "Template Name" field, paste above template into "Template Body" text area and click Save. Next click on "Weblog config" in the main menu, click on "Archiving" link, then push "ADD NEW..." button. In the dialog select "Individual" in "Archive Type" and "Individual Comment RSS archive" in "Template" select box. Push "ADD" button. Now you've got two templates for "Individual" archive type, one for regular HTML page ("Individual Entry Archive" and make sure its radiobox is selected) and second for comments ("Individual Comment RSS archive"). Now paste "commentrss/<MTEntryID pad="1">.xml" into "Archive File Template" field for "Individual Comment RSS archive". That means MT will generate {entryid}.xml file in commentrss directory for each blog entry using provided template.
Also you need to fix "Individual Entry Archive" template a bit to generate id attribute for each comment (this allows linking to a partiluar comment by its ID). Go to "Templates", click on "Individual Entry Archive", locate "<div class="comments-body">" tag and change it to "<div class="comments-body" id="c<$MTCommentID pad="1"$>">".
Now you are ready to link generated comment RSS archives in main RSS 2.0 feed:
<MTEntries lastn="15">
<item>
...
<wfw:commentRss>
<$MTBlogArchiveURL encode_xml="1">commentrss/<$MTEntryID pad="1"$>.xml
</wfw:commentRss>
...
</item>
</MTEntries>
Rebuild the site and check if it works and your favorite RSS reader is able to see comments now.
Step 4. Enabling posting comments from RSS reader via CommentAPI
Well, this is the hardest part. Unfortunately I didn't found any implementation of CommentAPI for MT. MT is written in perl, so perl hackers are invited to fill the gap. As a quick workaround I decided to write a simple ASP.NET page to operate as a proxy for MT comment posting API. This aspx page merely receives a comment posted via CommentAPI, pulls out the data and posts it to MT via MT API. Really no big deal. Here it is (code behind part):
Having this aspx page allows me to add <wfw:comment> element to my RSS feed enabling posting of comments from RSS readers supporting CommentAPI (such as RSS Bandit). Here is a relevant RSS 2.0 template part:
<MTEntries lastn="15">
<item>
...
<wfw:comment>
<$MTBlogURL$>CommentAPI2MT.aspx?entry_id=<$MTEntryID$>
</wfw:comment>
...
</item>
</MTEntries>
That's it. Pheeew. Above recipe implemented at this blog so you can test it right now. Here is my RSS 2.0 feed MT template just if you want to see the whole puzzle done. If you site doesn't support ASP.NET, the same comment proxy logic can be easily implemented in JSP or PHP or whatever server scripting.
As usual any comments, bug reports, questions and amendments are appreciated.
I've been attending Microsoft conference on Biztalk 2004 in Tel-Aviv today. Well, probably the only worth doing outcome is a mug with Biztalk logo. Beside that only one presentation by Cobby Cohen was at least substantially interesting to some degree, all other talks were pure blah-blah-copy-n-paste-from-biztalk-overview. By the way we've been shown Biztalk 2004 not-beta version, which is what I'm looking for now. Does anybody have a clue where fresh Biztalk 2004 builds are available to download?
Apparently there is no CommentAPI implementation or plugin for MovableType blogging engine. At leats I'm unable to find any. And the last thing I want to do is to code in Perl today. Well, proxy ASPX page should be just fine then.
Moving the blog I relaized it's kinda layered by dust from architectural point of view. So I upgraded MovableType engine up to the latest version (2.65), added RSS 2.0 and Atom 0.3 feeds and implemented wfw:commentRss in RSS 2.0 feed. Also I abandoned RSS 0.91 and 1.0 feeds.
Implementing wfw:commentRss in MovableType engine turned out to be a piece of cake (should I provide detailed guide for those interested?) and now I can read this blog's comments directly in RSSBandit (and I hope you can in your blogreader too). So cewl! It's a shame for Six Apart that MovableType templates don't support such feature out-of-box. Btw, Dare has complained about this inconvenience recently, I really hope he'll be satisfied now.
Unfortunately I cannot still posting comments from RSSBandit to this blog. Hmmm... Something is missed apparently. Need to read some more.
Done. I moved from Linux-based Java-featured hosting to Windows-based .NET-featured one. No problem at all, even with MovableType database. It just works, all I needed to do is to add DB_File perl module as described in MT install guide.
Finally I'm moving to the new hosting. I'm going to make it during x-mas holidays, probably the site and email won't work couple of days. If you need me, reach me via IM (I'm oleg@tkachenko.com there).
Just for your fun - I've found the song in usenet archives. Here it is:
From: jenglish@crl.com (Joe English)
Newsgroups: comp.text.sgml
Subject: A Song
Date: 24 Oct 1994 19:05:27 -0700
Organization: Helpless people on subway trains
Lines: 51
Message-ID: <38hp57$1r6@crl.crl.com>
NNTP-Posting-Host: crl.com
[ Allegro, with vigor ]
Well, if you can't do it with <!LINKTYPE ...>,
And features of SGML,
And if you can't hack it in HyTime,
No sweat! It's in DSSSL!
DSSSL!
DSSSL!
It's really cool!
A useful tool!
It's DSSSL!
"So tell me then, what does it look like?"
Afraid I can't -- nobody knows!
I guarantee you're gonna love it,
Just wait and see, that's how it goes.
DSSSL!
DSSSL!
It's like a dream!
It's based on Scheme!
It's DSSSL!
The World-Wide-Web's gotta have stylesheets,
Or HTML's going to burst.
Will DSSSL come and save us
(Unless Netscape gets to it first)?
DSSSL!
DSSSL!
Never fear,
It's almost here!
It's DSSSL!
So -- if -- FOSI's are driving you batty,
And PDF isn't enough,
This standard will solve all your problems
(But it isn't finished yet. Tough.)
DSSSL!
DSSSL!
It's amazingly great
But you'll just have to wait
For Dee-ess-ess-ess-ellllllll!
--Joe English
jenglish@crl.com
Reading last Aaron Skonnard's installment in MSDN Mag I cannot resist to note that his explanation of whitespace handling in XSLT is not actually true. Or to put it this way - it's true only for Microsoft's XSLT implementations in default mode.
Here is what Aaron says:
Before an XSLT processor executes a transformation against a given source document, it first strips all white space-only text nodes from both documents.
Well, looks like a)Aaron's only working with Microsoft XSLT processors in default mode and b)forgot what W3C XSLT Recommendation says about whitespace stripping.
It might be new for some Microsoft-oriented XSLT users, but XSLT spec explicitly says that whitespace should be preserved in source XML tree by default. Yes, even insignificant one aka whitespace-only text nodes. This is how all conforming XSLT processors should actually behave. MSXML and XslTransform are only notable exceptions. The explanation of this spec violation is that the process of whitespace stripping is done at tree-building stage and both XSLT engines have no control over it. Indeed, by default both XmlDocument and XPathDocument do strip all insignificant whitespace. And some of us seems to be so get used to it that even claim this is how XSLT should work. That's not true.
XSLT processors don't strip insignificant whitespace from source XML, that's input tree builders (MSXML's DOMDocument, XmlDocument and XPathDocument) by default do that. And if you happens to transform XmlDocument, which has been loaded with PreserveWhitespace property set to true or XPathDocument, which has been loaded with XmlSpace.Preserve argument in the costructor call you might be badly surprised. XSLT stylesheet disregarding insignificant whitespace is not a robust one, because it depends in a very fragile way on XSLT processor's environment. Not to mention using other XSLT processors such as Saxon or Xalan.
A loud example of such bad XSLT programming style is usually becomes apparent when using <xsl:apply-templates/> and position() function together. Consider the following XML document:
<root>
<item>Screwdriver</item>
<item>Hammer</item>
</root>
Then the following stylesheet:
<stylesheet version="1.0"
xmlns="http://www.w3.org/1999/XSL/Transform" >
<template match="item">
<value-of select="position()"/>:<value-of select="."/>
</template>
</stylesheet>
will output
1:Screwdriver2:Hammer
in MSXML and .NET in default (whitespace stripping) mode and
2:Screwdriver
4:Hammer
in all non-Microsoft processors and in Microsoft processors in whitespace-preserving mode.
Beware of that.
The length of a spec is directly proportional to the size of the
committee that produced it, multiplied by the number of years spent on
the effort (which also increases with the size of the committee).
Michael Kay
First working draft of XSL 1.1 has been published. Version 1.1 updates the XSL 1.0 Recommendation for change marks, indexes, multiple flows, and bookmarks, and extends support for graphics scaling, markers, and page numbers.
For those unfamiliar, that's XSL-FO spec, XML vocabulary for expression formatting semantics for high-quality paginated presentation. I've been XSL-FO zealot back in 2001-2002, working with it very closely implementing XSL-FO output channel (pdf, tiff, fax, printer) for the system I was working on that time, contemplating on this IMO the biggest W3C Recommendation ever (400+ pages), evangelizing XSL-FO by helping people on many mail lists and working on Apache FOP project (hey, I'm still olegt@apache.org). That was great experience. XSL-FO is a successor of DSSSL and has plenty of extremely interesting people from document-centric publishing world around it, yeah that was great. Nowadays that's even impossible to dig out Joe English's DSSSL song out of the NET, anyway here is another dsssl song by Tony Graham (just to make you feel that spirit):
I Use DSSSL
By Tony Graham (to the tune of "Don't Cry for Me, Argentina" by Andrew Lloyd-Webber)
This won't be easy,
you'll think it's strange.
When I try to explain how I print -
that I use an ISO standard
after all that I've done.
You won't believe me.
All you will see is the good output,
although it's dressed up to the nines -
it started with S-G-M-L
I had to let it happen.
I had to change.
Couldn't stay being proprietary.
Stuck with one vendor,
No choice of software.
So I choose freedom.
Running around, trying everything new.
But nothing impressed me at all.
I never expected it too.
Don't cry for me, I use DSSSL.
The truth is it is quite good:
Style sheet language,
Flow object tree,
A choice of backends. You should try it.
This site was down yesterday for who-knows-how-much hours because some troubles with Apache httpd of my hoster. What's the most annoying I didn't managed to get in touch any customer service. Plain silence. I'm keep getting randomly scary and mysterious "Quota exceeded while writing "/var/spool/mail/oleg"" messages, mysterious because I've got plenty free space, again no any help from support. Well, I'm preparing to move. Probably to webhost4life.com as your guys recommended. I only wonder if it's feasible to install dasBlog engine on webhost4life.com hosted site?
Chris Lovett's internal Microsoft presentation of X# language project (Oct 2002) has leaked - download it here (via jayson knight). Well, the project is dead. Probably that's good, because it really sounds like monstrous deadly mix of XSD/XSLT/XQuery/SQL and C#. But still really interesting and I strongly believe it's based on not only interesting, but fruitful ideas and we'll hear something about such thing again. As a matter of interest, BizTalk 2004 Beta includes xsharpp.exe utility, which seems to be X# to C# translator (I'm not sure actually that's the same X# though).
And here is another beast for XML bestiary I've created a year ago, but forgot to publish. I'm not sure may be someone did that already, the idea and implementation are really trivial. It's XmlNodeNavigator, which is XPathNavigator over XmlNode (as a subtree) in XmlDocument. It allows to navigate over a subtree in DOM as if it's independent XML document. The main goal of the XmlNodeNavigator is to enable XSL transformation of a portion of XmlDocument without creating temporary XmlDocument containing that portion of data.
Every XSLTers moving from MSXML to .NET usually get stuck with that. In MSXML one usually applies transformation to a node, defining by this the context XSLT operates on. Whenever you want to process only a piece of XML, just run tranformNode() on the node, which encapsulates that piece of data and all XSLT will see then is just that piece of XML, not the whole tree. In .NET though that won't work as XslTransform class applies transformation to the document as a whole, no matter which node you have passed as input. MSDN suggests using temporary XmlDocument, which contains fragment of data you want to transform. That solution is really not satisfactory, pure wasting of memory and performance penalty just for the glory of programmer's laziness. Here is where XmlNodeNavigator idea comes into play. It implements XPathNavigator over the subtree and doesn't allow to navigate outside the subtree boundaries thus enabling effective subtree transformations.
Couple of words about the implementation. XmlNodeNavigator leverages XmlDocument's native XPathNavigator internally, but in MoveTo, MoveToFirst, MoveToNext, MoveToPrevious, MoveToRoot and MoveToParent methods it additionally ensures the navigation doesn't go beyound permissible boundaries - out of the given XmlNode and its descendants. Download XmlNodeNavigator from GotDotNet and see sources for more info.
Finally a sample of transforming XML fragment using XmlNodeNavigator. Source XML:
<library>
<book genre='novel' ISBN='1-861001-57-5'>
<title>Pride And Prejudice</title>
</book>
<book genre='novel' ISBN='1-81920-21-2'>
<title>Hook</title>
</book>
</library>
And the stylesheet is just copies all available input to output:
<stylesheet version="1.0"
xmlns="http://www.w3.org/1999/XSL/Transform" >
<output indent="yes"/>
<template match="/">
<copy-of select="/"/>
</template>
</stylesheet>
The code:
XslTransform xslt = new XslTransform();
xslt.Load("test.xsl");
XmlDocument doc = new XmlDocument();
doc.Load("foo.xml");
//Navigator over first child of document element
XPathNavigator nav =
new XmlNodeNavigator(doc.DocumentElement.FirstChild);
xslt.Transform(nav, null, Console.Out, null);
The result:
<book genre="novel" ISBN="1-861001-57-5">
<title>Pride And Prejudice</title>
</book>
So, the navigator over first book element has been provided to the transformation and all the XslTransform sees at input is only this subtree - book element and its descendants. And that's done with no any interim tree. It would be really nice to see such class in v2 of System.Xml API.
Well, here is a small basic example how to generate WordprocessingML documents basing on templates. Saying "template" I don't mean regular *.dot Word templates, but just WordprocessingML XML document with predefined document/paragraph/run level properties and styles. Having such template document basically all needs to be done is to fill it with real content.
Here is such a template, it's empty Word 2003 document where I defined new style called MyFancyStyle and saved document as XML.
Here is the source of the content - a hypothetical report:
<?xml version="1.0">
<report><link
url="http://www.internettrafficreport.com/main.htm">Internet Traffic Report</link>
reports on the current performance of major Internet routes around the world.</report>
And here goes XSLT stylesheet:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:wx="http://schemas.microsoft.com/office/word/2003/auxHint"
xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml">
<xsl:variable name="root" select="/*"/>
<xsl:template match="/">
<xsl:apply-templates
select="document('d:\temp\WordTemplate.xml')/node()"
mode="template"/>
</xsl:template>
<xsl:template match="@*|node()" mode="template">
<xsl:copy>
<xsl:apply-templates select="@*|node()"
mode="template"/>
</xsl:copy>
</xsl:template>
<xsl:template match="w:body/wx:sect" mode="template">
<xsl:copy>
<xsl:apply-templates select="$root"/>
<xsl:copy-of select="wx:sectPr"/>
</xsl:copy>
</xsl:template>
<xsl:template match="report">
<w:p>
<w:pPr>
<w:pStyle w:val="MyFancyStyle"/>
</w:pPr>
<xsl:apply-templates/>
</w:p>
</xsl:template>
<xsl:template match="text()">
<w:r>
<w:t><xsl:value-of select="."/></w:t>
</w:r>
</xsl:template>
<xsl:template match="link">
<w:hlink w:dest="{@url}">
<w:r>
<w:rPr>
<w:rStyle w:val="Hyperlink"/>
</w:rPr>
<xsl:apply-templates/>
</w:r>
</w:hlink>
</xsl:template>
</xsl:stylesheet>
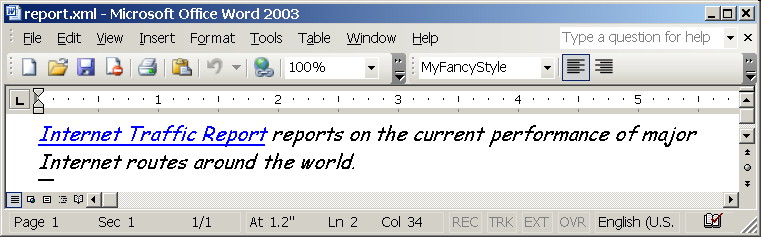
Basically what the stylesheet does? It opens template document, recursively copies all its content till it reaches w:body/wx:sect element. That's considered to be entry point for the content. Then stylesheet runs usual processing of the actual content in the source document, applying MyFancyStyle to the paragraph and after that copies wx:sectPr. Not rocket engineering indeed.
And finally here is how the result looks like. Note, real content is styled by MyFancyStyle style defined in the template.
First they have closed blogs. Now Dare's moved RSS Bandit project to SourceForge. Hmmm...

Well, I'm getting tired of my current hosting. I'm ready for change, can anybody recommend unexpensive ASP.NET hosting, 100Mb/2Gb?
Today I felt the Uroboros snake breathing just in my cubicle when I realized XSLT is able to write output to the input tree. Funny, huh?
XmlDocument doc = new XmlDocument();
doc.Load("input.xml");
XslTransform xslt = new XslTransform();
xslt.Load("test.xsl");
XmlNodeWriter nw = new XmlNodeWriter(doc.DocumentElement, false);
xslt.Transform(doc, null, nw);
nw.Close();
This transformation outputs result tree directly to the document element of the input tree! Moreover, during the transformation process the input tree is being dynamically changed and XSLT processor even is able to see the output tree in input and to process it again!
Of course you'd better then not to cycle transformation forever using plain <xsl:copy-of select="/"/>.
Practical usage? Highly-efficient update of in-memory DOM using XSLT with no any interim buffers. Kinda dangerous though, because output can destroy input prior it's processed or to loop forever, but nice one anyway.
Here is another beast for XML bestiary I've created yesterday just for fun to encapsulate commonly used functionality in an efficient way. It's XmlTransformingReader class. The idea is extremelly simple: XmlTransformingReader is XmlReader implementation, which encapsulates arbitrary XSL Transformation of input XML stream. Or to put it in another way - XmlTransformingReader reads input XML stream, transforms it internally using provided XSLT stylesheet and allows the resulting XML stream to be read from itself. For code-minded geeks here is the implementation:
public class XmlTransformingReader : XmlReader {
private XmlReader _outReader;
#region Constructors
public XmlTransformingReader(string source, string transformSource) {
XPathDocument doc = new XPathDocument(source);
XslTransform xslt = new XslTransform();
xslt.Load(transformSource);
_outReader = xslt.Transform(doc, null, new XmlUrlResolver());
}
//...Dozen other constructors ...
#endregion
#region XmlReader impl methods
public override int AttributeCount {
get { return _outReader.AttributeCount;}
}
public override string BaseURI {
get { return _outReader.BaseURI; }
}
//The rest 20+ XmlReader methods/properies implemented in the same way
}
Probably even too simple, but still quite usable.
It allows to modify XML on the fly, but of course it's not streaming plumbing as it embeds XSLT. Such reader can be useful to encapsulte complex XML transformations into a single XmlReader. Sure it allows also to implement easily simple local XML modifications, traditionally performed at SAX/XmlReader level, such as renaming/filtering nodes, converting attributes to elements etc., but I urge you to keep streaming processing. The main goal of XmlTransformingReader is to enable complex XML modifications, such as involve sorting, grouping, anyone that cannot be done in forward-only non-caching way XmlReader works. It's time for a sample. Here is how one can read three most expensive items from an inventory list :
inventory.xml
<parts>
<item SKU="1001" name="Hairdrier" price="39.99"/>
<item SKU="1001" name="Lawnmower" price="299.99"/>
<item SKU="1001" name="Spade" price="19.99"/>
<item SKU="1001" name="Electric drill" price="99.99"/>
<item SKU="1001" name="Screwdriver" price="9.99"/>
</parts>
filtering stylesheet
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="parts">
<parts>
<xsl:apply-templates select="item">
<xsl:sort data-type="number"
order="descending" select="@price"/>
</xsl:apply-templates>
</parts>
</xsl:template>
<xsl:template match="item">
<xsl:if test="position() <= 3">
<xsl:copy-of select="."/>
</xsl:if>
</xsl:template>
</xsl:stylesheet>
And finally the code:
XmlReader xtr = new XmlTransformingReader("inventory.xml", "filter.xsl");
//That's it, now let's dump out XmlTransformingReader to see what it returns
XmlTextWriter w = new XmlTextWriter(Console.Out);
w.Formatting = Formatting.Indented;
w.WriteNode(xtr, false);
xtr.Close();
w.Close();
The result:
<parts>
<item SKU="1001" name="Lawnmower" price="299.99" />
<item SKU="1001" name="Electric drill" price="99.99" />
<item SKU="1001" name="Hairdrier" price="39.99" />
</parts>
I've uploaded XmlTransformingReader sources to GotDotNet.com user samples section and surprisingly it was downloaded already 81 times in first 10 hours. Well, honestly that's not something new, all this stuff's able to do is to save couple of lines for an experienced developer, but my hope is it will be used by average users and will help them to avoid so common and so ugly piping of transformations with interim XmlDocument. Or may be it's just an exercise in advertising during these boring days. :)
XML Information Set, second edition became Proposed Rec. Mostly the Infoset is updated to reflect the fact it's going to be not only 1.0 version of XML in the near future. So major changes look like "XML 1.0". Plus emerging Namespaces in XML 1.1 adds namespace undeclaring to the infoset.
The day brought new toys - these for me:
 
And this one for Ju-ju:

Everybody knows grouping in XSLT is kinda advanced topic. Muenchian method is just a nightmare for XSLT newbies and XSLT-related newsgroups are full of help-me-to-group-in-xsl postings. Well, and I and fellows do answer such questions day afer day. Should admit that's a way booooring. Now I wonder why we don't use EXSLT to simplify grouping technique so even newsbies can grasp it quickly? I'm talking about set:distinct function, which can replace the dreadful and mysterious generate-id()=generate-id(key('theKey', foo)[1]) step in Muenchian method.
Here is a common grouping sample along with both classical solution (pure Muenchian method) and improved one (EXSLT-based). So compare and say which is more understandable.
Source XML, list of cities.
<doc>
<city name="Paris" country="France"/>
<city name="Madrid" country="Spain"/>
<city name="Vienna" country="Austria"/>
<city name="Barcelona" country="Spain"/>
<city name="Salzburg" country="Austria"/>
<city name="Bonn" country="Germany"/>
<city name="Lyon" country="France"/>
<city name="Hannover" country="Germany"/>
<city name="Calais" country="France"/>
<city name="Berlin" country="Germany"/>
</doc>
The task is to group them by countries:
<doc>
<country name="France">
<city>Paris</city>
<city>Lyon</city>
<city>Calais</city>
</country>
<country name="Spain">
<city>Madrid</city>
<city>Barcelona</city>
</country>
<country name="Austria">
<city>Vienna</city>
<city>Salzburg</city>
</country>
<country name="Germany">
<city>Bonn</city>
<city>Hannover</city>
<city>Berlin</city>
</country>
</doc>
Solution #1, classical Muenchian method:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:key name="kCountry" match="city" use="@country"/>
<xsl:template match="doc">
<doc>
<xsl:for-each
select="city[generate-id()=generate-id(key('kCountry', @country)[1])]">
<country name="{@country}">
<xsl:apply-templates select="key('kCountry', @country)"/>
</country>
</xsl:for-each>
</doc>
</xsl:template>
<xsl:template match="city">
<city><xsl:value-of select="@name"/></city>
</xsl:template>
</xsl:stylesheet>
Solution #2, EXSLT based one:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:set="http://exslt.org/sets" exclude-result-prefixes="set">
<xsl:key name="kCountry" match="city" use="@country"/>
<xsl:template match="doc">
<doc>
<xsl:for-each select="set:distinct(city/@country)">
<country name="{.}">
<xsl:apply-templates select="key('kCountry', .)"/>
</country>
</xsl:for-each>
</doc>
</xsl:template>
<xsl:template match="city">
<city><xsl:value-of select="@name"/></city>
</xsl:template>
</xsl:stylesheet>
Both stylesheets are almost the same except bolded parts. My measurements (using nxslt.exe with -t option) say it takes the same time to execute both stylesheets and frankly I don't see why it could be different. But set:distinct(city/@country) and city[generate-id()=generate-id(key('kCountry', @country)[1])] do differ, don't they?
Well, the only obvious contra is that Muenchian method is portable as pure XSLT, while EXSLT based method relies on optional EXSLT implementation.
Mike Gunderloy has been programming computers for over 25 years now, and still manages to keep up somehow. When he's not writing software or writing about software, he's living a life of near-hermitude in the hills of eastern Washington state, raising children, chickens, and garlic.
From "An Interview with author Mike Gunderloy" at the MCSE World.
The best bio I've ever read.
Just discovered that WordML to XSL-FO stylesheet does exist already. Well, I was talking about it since May, so no surprise somebody more effective than me just made it done. It's Antenna House guys, developers of the best XSL-FO formatter in the market. Check out this page. Sounds reasonable, they transform elements, say w:p to fo:block, expand styles and extract images to external files (via extension function written in java for Saxon).
But wait a minute, the price is $980! No evaluation version... Gosh...
Well, seems like images are one of the WordprocessingML trickiest parts, at least for me. Here are humble results of my investigations and experiments in embedding images into XSLT-generated WordprocessingML documents.
Images in WordprocessingML are represented by w:pict element, which holds both VML and binary data (obviously Base64 encoded). VML only or VML and binary . Even if you are embedding just plain binary gif, some VML elements still needed. So VML is your friend.
The "Overview of WordprocessingML" document only gives a couple of samples, saying that "A discussion of VML is outside the scope of this document". Great. Generally speaking VML is somewhat esoteric stuff for me. Here is why.
All we've seen funny import in office.xsd schema document:
<xsd:import namespace="urn:schemas-microsoft-com:vml"
schemaLocation="C:\SCHEMAS\vml.xsd"/>
Somebody at Microsoft does have vml.xsd in C:\SCHEMAS directory, but unfortunately they forgot to put it into "Microsoft Office 2003 XML Reference Schemas" archive. Then many elements in office.xsd have such annotation "For more information on this element, please refer to the VML Reference, located online in the Microsoft Developer Network (MSDN) Library." You can find VML reference at MSDN here. But it's dated November 9, 1999 so don't expect XSD schema there.
Some clarifications are expected, watch microsoft.public.office.xml newsgroup for details.
Anyway, when inserting raster image (GIF/JPEG/PNG/etc), Word 2003 creates the following structure: <w:pict>
<v:shapetype id="_x0000_t75" ...>
... VML shape template definition ...
</v:shapetype>
<w:binData w:name="wordml://02000001.jpg">
... Base64 encoded image goes here ...
</w:binData>
<v:shape id="_x0000_i1025" type="#_x0000_t75"
style="width:212.4pt;height:159pt">
<v:imagedata src="wordml://02000001.jpg"
o:title="Image title"/>
</v:shape>
</w:pict>
First element, v:shapetype, apparently defines some shape type (note, I'm complete VML ignoramus)
. I found it to be optional. Second one, w:binData, assigns an iternal name to the image in wordml:// URI form and holds Base64 encoded image. Third one, v:shape, is main VML building block - shape.
v:shape defines image style (e.g. size) and refers to image data via v:imagedata element.
So, to generate such structure in XSLT one obviously needs some way to get Base64 encoded image. XSLT doesn't provide any facilities for that, so one easy way to implement it is extension function. In the example below I'm using extension implemented in msxsl:script element. That's just for simplicity, if I wasn''t wrinting a sample I'd use extension object of course. Btw, I believe it's good idea to provide such extension function in EXSLT.NET lib.
Finally here is a sample implementation for .NET XSLT processor. Source XML:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="style.xsl"?>
<article title="Pussy cat">
<para>Here goes a picture: <image
src="d:\cat.gif" alt="Cat"/></para>
</article>
And here is XSLT stylesheet:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:w="http://schemas.microsoft.com/office/word/2003/wordml"
xmlns:msxsl="urn:schemas-microsoft-com:xslt"
xmlns:ext="my extension"
xmlns:v="urn:schemas-microsoft-com:vml"
exclude-result-prefixes="msxsl ext">
<msxsl:script language="C#" implements-prefix="ext">
public static string EncodeBase64(string file) {
System.IO.FileInfo fi = new System.IO.FileInfo(file);
if (!fi.Exists)
return String.Empty;
using (System.IO.FileStream fs = System.IO.File.OpenRead(file)) {
System.IO.BinaryReader br = new System.IO.BinaryReader(fs);
return Convert.ToBase64String(br.ReadBytes((int)fi.Length));
}
}
</msxsl:script>
<xsl:template match="/">
<xsl:processing-instruction
name="mso-application">progid="Word.Document"</xsl:processing-instruction>
<w:wordDocument>
<xsl:apply-templates/>
</w:wordDocument>
</xsl:template>
<xsl:template match="article">
<o:DocumentProperties>
<o:Title>
<xsl:value-of select="@title"/>
</o:Title>
</o:DocumentProperties>
<w:body>
<xsl:apply-templates/>
</w:body>
</xsl:template>
<xsl:template match="para">
<w:p>
<xsl:apply-templates/>
</w:p>
</xsl:template>
<xsl:template match="para/text()">
<w:r>
<w:t>
<xsl:attribute name="xml:space">preserve</xsl:attribute>
<xsl:value-of select="."/>
</w:t>
</w:r>
</xsl:template>
<xsl:template match="image">
<!-- internal url of the image -->
<xsl:variable name="url">
<xsl:text>wordml://</xsl:text>
<xsl:number count="image" format="00000001"/>
<xsl:text>.gif</xsl:text>
</xsl:variable>
<w:r>
<w:pict>
<w:binData w:name="{$url}">
<xsl:value-of select="ext:EncodeBase64(@src)"/>
</w:binData>
<v:shape id="{generate-id()}" style="width:100%;height:auto">
<v:imagedata src="{$url}" o:title="{@alt}"/>
</v:shape>
</w:pict>
</w:r>
</xsl:template>
</xsl:stylesheet>
And the result looks like:
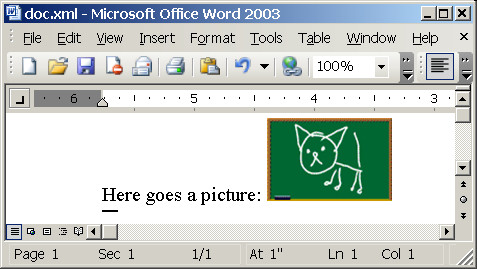
Another tricky part is image size. I found width:100%;height:auto combination to work ok for natural image size.
Still much to explore, but at least some reasonable results.
Finally I got a time to fully implement support for XmlResolver in XInclude.NET (see Extending XInclude.NET). Wow, this stuff looks so powerful! A friend of mine is writing an article about using resolvers in System.Xml, so no spoilers here, all I wanted is to illustrate what can be done now using XInclude.NET and custom XmlResolver.
So, somebody wants to include a list of Northwind employees into a report XML document. Yeah, directly from SQL Server database. Here comes XInclude.NET solution: custom XmlResolver, which queries database and returns XmlReader (via SQLXML of course).
report.xml:
<report>
<p>Northwind employees:</p>
<xi:include
href="sqlxml://LOCO055/Northwind?query=
SELECT FirstName, LastName FROM Employees FOR XML AUTO"
xmlns:xi="http://www.w3.org/2001/XInclude"/>
</report>
sqlxml:// URI schema is a proprietary schema, supported by my custom XmlResolver. LOCO055 is my SQL Server machine name, Northwind is the database I want to query and query is the query. Here goes SqlXmlResolver class:
public class SqlXmlResolver : XmlUrlResolver {
static string NorthwindConnString =
"Provider=SQLOLEDB;Server={0};
database={1};Integrated Security=SSPI";
public override object GetEntity(Uri absoluteUri,
string role, Type ofObjectToReturn) {
if (absoluteUri.Scheme == "sqlxml") {
//Extract server and database names from the URI
SqlXmlCommand cmd =
new SqlXmlCommand(string.Format(NorthwindConnString,
absoluteUri.Host, absoluteUri.LocalPath.Substring(1)));
cmd.RootTag = "EmployeesList";
//Extract SQL statement from the URI
cmd.CommandText =
absoluteUri.Query.Split('=')[1].Replace("%20", " ");
return cmd.ExecuteXmlReader();
} else
return base.GetEntity(absoluteUri, role, ofObjectToReturn);
}
}
}
Not really a sophisticated one, just checks if the URI schema is sqlxml:// and then extracts the data from the URI and runs the query via SQLXML plumbing.
Then we can read report.xml via XIncludingReader:
XIncludingReader reader = new XIncludingReader("report.xml");
reader.XmlResolver = new SqlXmlResolver();
XPathDocument doc = new XPathDocument(reader);
...
And finally the result is:
<report>
<p>Northwind employees:</p>
<EmployeesList>
<Employees FirstName="Nancy" LastName="Davolio"/>
<Employees FirstName="Andrew" LastName="Fuller"/>
<Employees FirstName="Janet" LastName="Leverling"/>
<Employees FirstName="Margaret" LastName="Peacock"/>
<Employees FirstName="Steven" LastName="Buchanan"/>
<Employees FirstName="Michael" LastName="Suyama"/>
<Employees FirstName="Robert" LastName="King"/>
<Employees FirstName="Laura" LastName="Callahan"/>
<Employees FirstName="Anne" LastName="Dodsworth"/>
</EmployeesList>
</report>
That magic is supported by XInclude.NET version 1.2, which I'm going to release right now. Well, actually I don't think including SQL into URI was a good idea, but bear in mind, that's just a dummy sample to illustrate the power of XmlResolvers. Enjoy!
XML is syntax, and only Unicode in angle brackets is real XML.
Elliotte Rusty Harold
Close your eyes and repeat it 100 times to yourself, then feel free to read xml-dev mail.
8 hours of meeting on extremely boring topic... Oooooooh, I feel like I'm in dead message queue.
It turned out people do use XInclude.NET already and even more - now they want to extend it! First one user wanted to be able to resolve URIs himself, via custom XmlResolver. I did that yesterday (download XInclude.NET v1.2beta if you're interested in such behaviour), but I didn't go beyound call to XmlResolver.ResolveUri().
New user case is about including XML documents generated on-the-fly. To avoid any interim layers like temporary files or HTTP calls this can be implemented by further unrolling of XmlResolver support - now to call XmlResolver.GetEntity() method on custom resolvers. This way custom XmlResolver may generate XML on the fly and return it say as XmlReader for best performance. Sounds interesting, will do.
By the way, Fawcette XML and Web Services Magazine has piblished a free book chapter of the "A First Look at ADO.NET and System.Xml v. 2.0" book by Alex Homer, Dave Sussman, and Mark Fussell.
I've devoured the chapter last night and now I think I'm going to buy the book to be prepared for the future. As per my taste it's too data-oriented, but that's exactly what document-oriented guy with HTML/Docbook/XSL-FO past like me really needs.
Oh, and recently published "The C# Programming Language" by Anders Hejlsberg et al of course!
This Wired report is overwhelming: the guy who has been sending threatening messages back to the spammers, which refused to unsubscribe him from their spam mail list now faces up to five years in prison and a $250,000 fine. /. discussion here. Mark Pilgrim's prediction has been proven.
Well, in fact I want my blog to be free of agitprop, I really got fed up enough with that stuff being born and grown up in the USSR. But today I feel tired after jogging on the beach and then shopping with my wife too much time so forgive me this one.
Note: if you happily have no idea what Geneva Draft is - just skip this rant out.
Tim Bray has ranted about Geneva Draft and even published it on his site. Seems like he likes it so much it makes him just blind. I know, Tim has been living in Lebanon some time and the permanent Middle East Crisis makes his heart bleeding, but this is just ridiculous if not rude:
Murderous Warmongering Scum This document has been denounced by the current government of Israel (no surprise there) and the Swiss Government has received complaints from the World Jewish Congress for sponsoring it (astounding). The title of this section expresses my feelings for anyone who stands in the way of the hope of peace.
Oh boy, how familiar that smells, just like from an editorial of some soviet newspaper in the middle of the 1970s. I mean, really, as a matter of fun, "israeli warmongers" was the most typical slogan in the soviet agitprop since Israel won the War of Independence. It's funny Tim is using this slogan too, but it's sad in the same time, because as per his words the current government of Israel and probably all Israelis voted for them (70% by the way, /me included) are just murderous warmongering scums.
Well, may be I'm murderous warmonger too, but I has just thrown my copy of the Geneva Draft to the trash once I got it because as per my understanding it is a trash.
Beside that I believe the national losers (authors of the Geneva Draft lose couple of the last elections) don't have any legitimate rights to carry on any state-level negotiations, I just don't believe in peace with terrorists, sorry Tim, just like many didn't believe in peace with Hitler. "Land-for-hope-for-piece" deal doesn't work, the WWII and the last "intifada" proved that perfectly. Terrorists must be stopped, otherwise one day you will see a suicide bomber parking his heavy loaded car near your office.
An appeaser is one who feeds a crocodile, hoping it will eat him last.
That was said by Sir Winston Churchill.
Update: Don't get me wrong, I'm not a radical, I'm (and vast majority of Israelis) against "Let's give up everything just for hope for peace" approach, which the Geneva Draft represents. The road map plan is a way more realistical - first stop terrorism, destroy Hamas and friends and then get the state, but not vice versa.
Interesting finding on XQuery from Elliotte Rusty Harold:
In XSLT 1.0 all output is XML. A transformation creates a result tree, which can always be serialized as either an XML document or a well-formed document fragment. In XSLT 2.0 and XQuery the output is not a result tree. Rather, it is a sequence. This sequence may contain XML; but it can also contain atomic values such as ints, doubles, gYears, dates, hexBinaries, and more; and there's no obvious or unique serialization for these things. For instance, what exactly are you supposed to do with an XQuery that generates a sequence containing a date, a document node, an int, and a parentless attribute? How do you serialize this construct? That a sequence has no particular connection to an XML document was very troubling to many attendees.
Looking at it now, I'm seeing that perhaps the flaw is in thinking of XQuery as like XSLT; that is, a tool to produce an XML document. It's not. It's a tool for producing collections of XML documents, XML nodes, and other non-XML things like ints. (I probably should have said it that way last night.) However, the specification does not define any concrete serialization or API for accessing and representing these non-XML collections. That's a pretty big hole left to implementers to fill.
Hmmm, that's kinda confusing. Let's see. Formally speaking what XQuery produces is one( zero) or more instances of XPath 2.0 and XQuery 1.0 Data Model (DM), which then are subject to the serialization process, defined in XSLT 2.0 and XQuery 1.0 Serialization spec. The problem (typo?) is that XQuery spec says:
Serialization is the process of converting a set of nodes from the data model into a sequence of octets... and thus doesn't mention what happens with items in the resulting DM, which are not nodes, but atomic values. I believe that's a mistake in XQuery spec, because XSLT 2.0 and XQuery 1.0 Serialization handles that pretty well - it defines serialzation of DM including all it can contain, particularly, atomic values are converted to their string representations.
By the way I've rummaged a bit in Google archive and found my first posting into microsoft.public.xsl newsgroup. It was 2002-11-02, more than year ago. I was totally Java-oriented guy at that time, just started learning .NET and feeling like entering a new world. And the new world hooked me on its drugs rapidly and cruelly. That's all.
Microsoft Announces Availability of Open and Royalty-Free License For Office 2003 XML Reference Schemas : To ensure broad availability and access, Microsoft is offering the royalty-free license using XML Schema Definitions (XSDs), the cross-industry standard developed by the W3C. The license provides access to the schemas and full documentation to interested parties and is designed for ease of use and adoption. The Microsoft Office 2003 XML Reference Schemas include WordprocessingML (Microsoft Office Word 2003), SpreadsheetML (Microsoft Office Excel 2003) and FormTemplate XML schemas (Microsoft Office InfoPath 2003).
Wow, respect. I hope next step will be standardizing schemas just how it was done with CLI and C#. By the way "Generating Word documents using XSLT" approach I was talking about back in May is completely legal now and even kinda encouraged.
Funny enough, WordML is now called WordprocessingML, probably the longest ML-related acronym ever. Download WordprocessingML schema and documentation now and get back to that link 12/5/2003 to grab SpreadsheetML (Microsoft Office Excel 2003) and FormTemplate XML schemas (Microsoft Office InfoPath 2003).
The whole morning I'm trying to get rid of the idee fixe of writing XmlReader/XmlWriter based XML updater. The aim is to be able to update XML without loading it to DOM or even XPathDocument (which as rumored is going to be editable in .NET 1.2). Stream-oriented reading via XmlReader, some on-the-fly logic (quite limited though - filtering, values modifying) in between and then writing to XmlWriter. Cache-free, forward-only just as XmlReader is. If you're aware of SAX filters you know what I'm talking about. But I want the filtering/updating logic (hmmm, did you note I'm avoiding "transforming" term?) to be expressed declaratively.
Obviously the key task is how to express and detect nodes to be updated. If we go XPath patterns way we generally can get limited to single update per process, due to forward-only restriction. Subsetting XPath can help though. The only way to evaluate XPath expression without building tree graph is so-called ForwardOnlyXPathNavigator aka XPathNavigator over XmlReader. This beast is mentioned sometimes in articles, but I'm not aware of any implementation availble online yet. Btw, a friend of mine did that almost a year ago, may be I can get him to publish it. As per name it limits XPath to forward axes only (the subset seems to be the same as Arpan Desai's SXPath) and of course can't evaluate more than one absolute location path. But it can evaluate multiple relative location pathes though, e.g. /foo/a, then b/c in
<foo>
<a>
<b>
<c/>
</b>
</a>
</foo> tree. Another way to express which nodes are to be updated is [NodeType][NodeName] pattern, probably plus some simple attribute-based predicates. Sounds ugly, I know, but limiting scope to a node only fits better to forward-only way I'm trying to think.
Another problem is how to express update semantics. I have no idea how to avoid inventing new syntax. Something like:
<update match="/books/book[@title='Effective XML']">
<set-attribute name="on-load" value="Arthur"/>
</update>
I have no idea if it's really feasible to implement though. All unmatched nodes should be passed untouched forward to the result, on the matched one the update logic should be evaluated and then go on.
Yes, I'm aware of STX, but I feel uneasy about this technology. Too coupled to SAX (CDATA nodes in data model ugh!), assignable variables etc. No, I'm talking about different thing, even more lightweight one (thought even more limited).
Does it make any sense, huh ?
Here are the sacral list of simple exercises to improve your karma and become a real guru. Just for neophytes and those who missed this practice somehow:
More links are welcome.
Interesting article about incremental XSLT. I only wish it comes true some day.
From saxon-love-in-department: >>
>> How did Michael do it .
>>
The biggest factors are a total absence of project managers, marketeers,
junior programmers, and paying customers who think they know best.
Michael Kay
Just found new beast in the Longhorn SDK documentation - OPath language: The OPath language is the query language used to query for objects using an ObjectSpace. The syntax of OPath also allows you to query for objects using standard object oriented syntax. OPath enables you to traverse object relationships in a query as you would with standard object oriented application code and includes several operators for complex value comparisons.
Orders[Freight > 5].Details.Quantity > 50 OPath expression should remind you something familiar. Object-oriented XPath cross-breeded with SQL? Hmm, xml-dev flamers would love it.
The approach seems to be exactly opposite to ObjectXPathNavigator's one - instead of representing object graphs in XPathNavigable form, brand new query language is invented to fit the data model. Actually that makes some sense, XPath as XML-oriented query language can't fit all. I wonder what Dare think about it. More studying is needed, but as for me (note I'm not DBMS-oriented guy though) it's too crude yet.
The day started with bad news from W3C - XInclude 1.0 has been whithdrawn back to Working Draft maturity level. Actually Last Call WD, but anyway the step backward. The main reason is most likely primarily architectural one - seems like URI syntax with XPointers in fragment identifier part has been considered too revolutionary and now they broke it up to two separate attributes - href attribute contains URI or the resource to include and xpointer attribute - XPointer identifying the target portion of the resource. So instead of
<xi:include href="books.xml#bk101/>
another syntax should be used:
<xi:include href="books.xml" xpointer="bk101"/>
While it sounds good from "Make structure explicit through markup" perspective, it does smell bad with regard to URI syntax, which allows fragment identifiers for years.
Another new feature - now it's possible to control HTTP content negotiation via new accept, accept-charset and accept-language attributes. Well, again quite dubious stuff. And possible security hole as Elliotte pointed out.
Also XInclude namespace is now "http://www.w3.org/2003/XInclude", but old one should be supported somehow too.
Anyway I have to update XInclude.NET library now. No big changes fortunately, so I'm going to release it in a couple of days.
Via Carnage4Life: Top 50 IRC Quotes
My favorite one:
*** Quits: TITANIC (Excess Flood)
Well, it's extremely well-chewed topic well-covered by many posters, but provided people keep asking it I feel I have to give a complete example of the most effective way (IMO) of solving this old recurring question - how to transform CSV or tab-delimited file using XSLT?
The idea is to represent non-XML formatted data as pure XML to be able to leverage many's favorite XML hammer - XSLT. I want to make it clear that approaching the problem this way doesn't abuse XSLT as XML transformation language. Non-XML data is being represented as XML and XSLT operates on it via XPath data model prism actually having no idea it was CSV file on the hard disk.
Let's say what's given is this tab-delimited file, containing some info such as customer ID, name, address about some customers. You need to produce HTML report with customers grouped by country. How? Here's how: all you need is XmlCSVReader (cudos to Chris Lovett), XSLT stylesheet and couple lines of code to glue the solution:
Code:
using System;
using System.Xml;
using System.Xml.XPath;
using System.Xml.Xsl;
using System.IO;
using Microsoft.Xml;
public class Sample {
public static void Main() {
//XMLCSVReader setup
XmlCsvReader reader = new XmlCsvReader();
reader.Href = "sample.txt";
reader.Delimiter = '\t';
reader.FirstRowHasColumnNames = true;
//Usual transform
XPathDocument doc = new XPathDocument(reader);
XslTransform xslt = new XslTransform();
xslt.Load("style.xsl");
StreamWriter sw = new StreamWriter("report.html");
xslt.Transform(doc, null, sw);
sw.Close();
}
}
XSLT stylesheet
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:key name="countryKey" match="/*/*" use="country"/>
<xsl:template match="root">
<html>
<head>
<title>Our Customers Worldwide</title>
</head>
<body>
<table style="border:thin solid orange;">
<xsl:for-each select="*[count(.|key('countryKey',
country)[1])=1]">
<xsl:sort select="country"/>
<tr>
<th colspan="2"
style="text-align:center;color:blue;">
<xsl:value-of select="country"/>
</th>
</tr>
<tr>
<th>Customer Name</th>
<th>Account Number</th>
</tr>
<xsl:apply-templates
select="key('countryKey', country)"/>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="row">
<tr>
<xsl:if test="position() mod 2 = 1">
<xsl:attribute name="bgcolor">silver</xsl:attribute>
</xsl:if>
<td>
<xsl:value-of
select="concat(fname, ' ',mi, ' ', lname)"/>
</td>
<td>
<xsl:value-of select="account_num"/>
</td>
</tr>
</xsl:template>
</xsl:stylesheet>
Resulting HTML:
| Canada |
| Customer Name |
Account Number |
| Derrick I. Whelply |
87470586299 |
| Michael J. Spence |
87500482201 |
| Brenda C. Blumberg |
87544797658 |
| Mexico |
| Customer Name |
Account Number |
| Sheri A. Nowmer |
87462024688 |
| Rebecca Kanagaki |
87521172800 |
| Kim H. Brunner |
87539744377 |
| USA |
| Customer Name |
Account Number |
| Jeanne Derry |
87475757600 |
| Maya Gutierrez |
87514054179 |
| Robert F. Damstra |
87517782449 |
| Darren M. Stanz |
87568712234 |
Main virtue of this approach is that all transformation and presentation logic is concentrated in only one place - XSLT stylesheet (add CSS according to your taste), C# code is fully agnostic about data being processed. In the same fashion CSV file can be queried using XQuery or XPath. Once the data is represented as XML, all doors are open.
In W3C news:
5 November 2003: W3C is pleased to announce the advancement of Extensible Markup Language (XML) 1.1 and Namespaces in XML 1.1 to Proposed Recommendations. Comments are welcome through 5 December. XML 1.1 addresses Unicode, control character, and line ending issues. Namespaces 1.1 incorporates errata corrections and provides a mechanism to undeclare prefixes.
For those from another planet, here is a summary of changes:
- Namespaces can be undeclated now, using xmlns:foo="" syntax
- Namespace IRIs instead of namespace URIs
- Change in allowed--in-names-characters pholisophy - in XML 1.1 everything that is not forbidden (for a specific reason) is permitted, including those characters not yet assigned
- Two more linefeed characters - NEL (#x85) and the Unicode line separator character, #x2028
- Control characters from #x1 to #x1F are now allowed in XML 1.1 (provided they are escaped as character references)
Seems like old dreams about deep extending VisualStudio.NET up to adding new languages, editors and debuggers without funny-not-for-me COM programming but using beloved C# finally come true! Microsoft is inviting beta testers to VSIP Extras Beta program. The killer feature:
.NET Framework support. Interop assemblies are provided to allow VSIP packages to be developed in C#, managed extensions for C++, or Visual Basic. New samples have been provided in managed languages and the documentation has been updated to include information about managed code development.
Go to fill Beta Nomination Survey, may be you are lucky enough to be choosen.
I've got a bunch of ideas, from XSLT debugger to XQuery editor, postponed till this can be done in C#, because I'm really weak in COM.
Well, it's over. Just came back from the Matrix Revolutions. Couple of spoilers - its' not really about revolution, but peace talks. Nothing unexpected, the Hero is sacrificing himself to save the Mankind from the Dragon, an eternal archetype...
Anyway, this installment is certanly a way better than the Reloaded one.
While Don Box is declaiming of the VB glory, Mark Fussel is busy with quite opposite bussiness - he's reading the burial service over XmlDocument aka DOM, worth to quote as a whole:
The XML DOM is dead. Long live the DOM.
Dearest DOM, it is with little remorse,
to see that your API has run its course.
You expose your nodes naked and bare,
with no chance of any optimizations there.
Your (cough) data model is just to complex,
and causes developers to vex
over how to deal with CDATA, notations and entity refs.
So it is with a small tear welling in my eye,
that I watch the completion of your demise.
In .NET the XPathDocument has now taken your throne,
as the king of the XML API-dom.
Goodbye DOM, just disappear and die,
I will not miss you with your unweildly API.
Goodbye DOM, goodbye.
RIP DOM. Viva XPath!
So, nxslt version 1.3 is at your service. New features include:
- Support for XML Inclusions (XInclude) 1.0 Candidate Recommendation. Done by incorporating XInclude.NET library into nxslt. XML Inclusions are processed in both source XML and XSLT stylesheet, by default it's turned on and can be disabled using -xi option.
- Improved EXSLT support. Now nxslt leverages EXSLT.NET implementation. That means more EXSLT extension functions supported with much better performance and compatibility.
- Small advanced feature for EXSLT.NET developers - support for external EXSLT.NET assembly.
Download it here or here (GotDotNet). It's free of course. Thorough documentation is here.
I've been some time offline travelling around Israel with my wife, Mom and mother-in-law. Now, coming back to my mail and RSS Bandito I feel like I missed a revolution in the industry. The crowd is talking about declarative programming on Windows, Elliotte Rusty Harold likes Microsoft XAML design, hmmmmmmmm what's going on?
By the way I'm reading Elliotte's new book, "Effective XML" (check out some chapters online) right now. Well, that's the most interesting XML book I've read last years, probably becuase Elliotte doesn't try to teach us XML, but sorts out well-known XML problems and pitfalls and explains best practices how to solve them to make using XML effective. Of course not all he's writing I'm agree with, but still interesting. In fact it's java-related book, so "Effective XML" addendum for .NET world is needed. I believe it could be great subject for an article.
In the related news, by Mark Fussell:
Ubiquity and deployment! What planet are you living on! Where does deployment fit with the DOM! The DOM is a dying API, superced by improved XML stores such as the JDOM and in .NET the XPathDocument, now that this is editable in the System.Xml "Whidbey" release.
Ahhha, a honey for my soul...
To my delight, GotDotNet Workspaces have been upgraded to v1.1. Newly added features now make the environment really competing with SourceForge.net et al. Finally!
- Workspace aliases. Now I can use human readable alias URL http://workspaces.gotdotnet.com/xinclude instead of machine-readable long id-based URL for XInclude.NET project! Wooohoo! (Cough, cough, actually it doesn't seem to work now, probably some time is needed to propagate the URL alias).
Dare, book http://workspaces.gotdotnet.com/exslt alias before somebody takes it!
- Documentation. Finally we can place html and images to customize workspace home page and provide online documentation for projects. A must stuff I really missed.
- Access control, by user and group, notifications, cool control knobs.
Well done guys!
It's Sukkot holydays in Israel. My mother came from Ukraine to visit us and provided that she is the first time in Israel, this week (and next three) I'm working mostly in tourist guide mode. There are plans to be in Jerusalem, Dead Sea, Eilat, Sea of Galilee, Golans, Caesarea, Negev desert etcetera. This week we've spent walking in Tel-Aviv area and lying on the beach, except for Wednesday, when we've been in Haifa. This picture has been taken there, it's Bahai Temple:

These days my blog is under attack by some insane spammers. Hehe, funny huh? I have no idea what such a comment to one of my blog record means:
Name: Sex Toys
Email Address: Dave@Dave.net
URL: http://www.sextoys######.om/
Comments:
We live in strange times, but someday I think we will look back on all of this and marvel at how crazy it was. God, I hope so. I sure wouldn't want this insanity to become the norm.
The Matrix Revolutions movie will be unveiled at the exactly the same moment in every major city around the world on November 5. It's going to be at 6AM in LA, 9AM in NY, 11PM in Tokyo and apparently 4PM in Israel.
Kinda unusual, probably the first time in the cinema history. My bet is they are just trying to amplify the effect. May be finally they'll connect Matrix reality to ours, e.g. by finishing The Matrix Revolutions in a scene where Neo's gathering all zombie people to see some movie with a title written in green on black.
Are you guys going to see a movie at 6AM? You must be geeks. :)
Does anybody have any recommendations/advices for buyng a notebook? I want to get one, something like from Compaq Presario series, which I only have an experience with. May be this one? 
New MVP Awards List for 2003-2004 has been published. My sincere congrats to Christoph and Kirk!
I've been told I was nominated too, but seems like I'm not lucky enough. May be what I'm doing is not enough or I'm doing something wrong, who knows. Well, may be next time.
Today's mentallogram:
FYI: Apache Xerces-J 2.5.0 release now partially supports XInclude. More info at http://xml.apache.org/xerces2-j/faq-xinclude.html. Kudos for Xerces team!
Finally full-fledged pull XML parser API for Java - StAX. James Clack in expert group, enough said.
The Streaming API for XML (StAX) is a Java based API for pull-parsing XML.
And here is " An Introduction to StAX" by Elliotte Rusty Harold. Nice!
If you'd ask me what's the best of the Tim Bray's ongoing, I say it's photos. Of course rants are great too, but I like his photos even more than holy XML homilies. So I decided that my blog needs photos too. The ship below is rusting in port of Istambul, Turkey, where my wife and I spent a weekend couple of weeks ago. Thoughtlessly missing weather forecast we've been shocked by the rainy cold weather when the airplane landed. Come on, it's hard core middle-east summer still goes on in Israel! Fortunately it was mostly sunny enough for such delicate heat-loving plants like Israeli tourists.
We've been wandering three days throughout the old city, trembling in front of 1.5 millennial Hagia Sophia, ploughing the Bosporus (not on the ship above) etcetera. I've never seen so much and so big mosques and as well as so much women in paranjas. It's probably the only Islamic country I can travel with my Israeli passport. Funny enough, turks seems to be speaking Russian better than English, so second day I switched to Russian to stop making them gesticulating. In another news - in less than an hour somebody is going to snap xquery.net domain name. It wasn't renewed by a previous owner and will be dropped by Network Solutions at 2:00PM EST today. Nice one, but looks like I won't win it, as too many people want it.
Today is the day, I'm glad to announce XInclude.NET 1.0 release. Download it here. For those who have no idea what XInclude.NET is:
XInclude.NET is free open-source implementation of XInclude 1.0 Candidate Recommendation and XPointer Framework Recommendation written in C# for .NET platform. XInclude.NET supports XPointer element() Scheme, XPointer xmlns() Scheme, XPointer xpath1() Scheme and XPointer xpointer() Scheme (XPath subset only).
Changes since 1.0beta release:
- Support for XPointer xpointer() schema (XPath subset only)
- Bug fixes
- Performance improvements
No big deal, but it took me the whole yesterday to fix reported bugs, optimize a bit and prepare the release. Hope you'll like it.
Now, the article about this plumbing is the agenda.
Now it's time to come back to my beloved XML plumbing - XInclude and XPointer. A bit of polish and tomorrow I'm going to release XInclude.NET 1.0. Changes since 1.0beta - XPointer xpointer() schema support (XPath subset only), bug fixes and minor performance improvements.
Along with that I've started an article about XInclude and XInclude.NET, what a good exercise for brains, much harder than regular programming. So more to come.
Finally I managed to run IM at my work (firewall issue), my sign-in name is oleg@tkachenko.com. So whenever you need me...
//Whoohaa!
XPathExpression expr = nav.Compile("set:distinct(//author)");
expr.SetContext(new ExsltContext(doc.NameTable));
XPathNodeIterator authors = nav.Select(expr);
while (authors.MoveNext())
Console.WriteLine(authors.Current.Value);
EXSLT's set:distinct in XPath-only selection. Sweet. Coming soon, watch announcements!
Michael Kay:
Namespaces were invented because someone was worried that XML was too
simple...
In related news - yesterday I've been given Mono CSV commit access, thanks to Ben and Miguel. Seems like I'm the first Oleg amongst Mono guys, so my account is just "oleg".
Now I desperately need one more hour in a day, it's a pity the Earth is so close to the Sun, 24 hours is really not enough for us!
Am I right that it's impossible to validate in-memory XmlDocument without serializing it to string and reparsing?
XmlValidatingReader requires instance of XmlTextReader and what's worse it uses its internal properties, not exposed as XmlTextReader public API, so that won't work even if one would provide fake instance of XmlTextReader, which encapsulates XmlNodeReader within. :(
For those interested - I'm selling old hebrew book "Diaspora and Assimilation" by Zeev Zhabotinsky. Just found it recently in the loft :) Published in 1936 in Tel-Aviv (Palestine at that time).
From Mono CVS Commit Rules:
Also, remember to pat yourself on the back after the commit, smile and think we're a step closer to a better free software world.
According to XPath data model an element node may have a unique identifier (ID), which can be used then to select a node by its ID using XPath's id() function and to navigate using XPathNavigator.MoveToId method. Querying by ID is extremely effective becuse in fact it doesn't require traversing the XML document, instead almost every XPath implementation I've ever seen just keeps internal hashtable of IDs, hence querying by ID is merely a matter of getting a value from a hashtable by a key.
XPath 1.0 Recommendation published back in 1999 of course says nothing about XML Schema, which was published in year 2001. May be that's the reason why XmlDocument and XPathDocument (and therefore XslTransform) classes in .NET don't support above tasty functionality when XML document is defined using XML Schema. Only DTD is supported unfortunately. Even if you have defined xs:ID typed attribute in your schema and validated document reading it via XmlValidatingReader it won't work. As a matter of fact it does work in MSXML4 though.
Whether it's right or wrong - I have no idea, it's quite debatable question.
On the one hand XPath spec explicitly says "If a document does not have a DTD, then no element in the document will have a unique ID.". On the other hand XML Schema was published 2 years after XPath 1.0 and provides semantically the same functionality as DTD does, so XPath 2.0 is now deeply integrated with XML Schema. And it works in MSXML4... I'm wondering what people think about it?
Anyway, here is another act of hackery: how to force XmlDocument and XPathDocument classes to turn on id() and XPathNavigator.MoveToId support when document is validated against XML Schema and not DTD.
Apparently XmlValidatingReader collects ID information anyway, but it's being asked for this collection only when XmlDocument/XPathDocument encounter DocumentType node in XML. So let's give them this node, I mean let's emulate it. Here is the code:
public class IdAssuredValidatingReader : XmlValidatingReader {
private bool _exposeDummyDoctype;
private bool _isInProlog = true;
public IdAssuredValidatingReader(XmlReader r) : base (r) {}
public override XmlNodeType NodeType {
get {
return _exposeDummyDoctype ?
XmlNodeType.DocumentType :
base.NodeType;
}
}
public override bool MoveToNextAttribute() {
return _exposeDummyDoctype?
false :
base.MoveToNextAttribute();
}
public override bool Read() {
if (_isInProlog) {
if (!_exposeDummyDoctype) {
//We are looking for the very first element
bool baseRead = base.Read();
if (base.NodeType == XmlNodeType.Element) {
_exposeDummyDoctype = true;
return true;
} else {
return baseRead;
}
} else {
//Done, switch back to normal flow
_exposeDummyDoctype = false;
_isInProlog = false;
return true;
}
} else
return base.Read();
}
}
And proof of concept:
source.xml
<root
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="D:\Untitled1.xsd">
<file id="F001" title="abc" size="123"/>
<file id="F002" title="xyz" size="789"/>
<notification id="PINK" title="Pink Flowers"/>
</root>
In Untitled1.xsd schema (elided for clarity) id attributes are declared as xs:ID.
The usage:
public class Test {
static void Main(string[] args) {
XmlValidatingReader vr =
new IdAssuredValidatingReader(
new XmlTextReader("source.xml"));
vr.ValidationType = ValidationType.Schema;
vr.EntityHandling = EntityHandling.ExpandEntities;
XmlDocument doc = new XmlDocument();
doc.Load(vr);
Console.WriteLine(
doc.SelectSingleNode("id('PINK')/@title").Value);
}
}
Another one:
public class Test {
static void Main(string[] args) {
XmlValidatingReader vr =
new IdAssuredValidatingReader(
new XmlTextReader("source.xml"));
vr.ValidationType = ValidationType.Schema;
vr.EntityHandling = EntityHandling.ExpandEntities;
XPathDocument doc = new XPathDocument(vr);
XPathNavigator nav = doc.CreateNavigator();
XPathNodeIterator ni = nav.Select("id('PINK')/@title");
if (ni.MoveNext())
Console.WriteLine(ni.Current.Value);
}
}
In both cases the result is "Pink Flowers".
I'm not sure which semantics this hack breaks. The only deficiency I see is that the dummy emulated DocumentType node becomes actually visible in resulting XmlDocument (XPathDocument is not affected because XPath data model knows nothing about DocumentType node type).
Any comments?
An interesting question has been raised in microsoft.public.dotnet.xml newsgroup: how to compile XPath expression without a XML document at hands? XPathNavigator class does provide such functionality via Compile() method, but XPathNavigator is abstract class hence this functionality is available only to its implementers, such as internal DocumentXPathNavigator and XPathDocumentNavigator classes, which are accessible only via corresponding XmlDocument and XPathDocument. Therefore obvious solutions are: using dummy XmlDocument or XPathDocument object to get XPathNavigator and make use of its Compile() method or implement dummy XPathNavigator class. Dummy object vs dummy implementation, hehe. Well, dummy implementation at least doesn't allocate memory, so I'm advocating this solution. Below is the implementation and its usage:
public sealed class XPathCompiler {
private sealed class DummyXpathNavigator : XPathNavigator {
public override XPathNavigator Clone() {
return new DummyXpathNavigator();
}
public override XPathNodeType NodeType {
get { return XPathNodeType.Root; }
}
public override string LocalName {
get { return String.Empty; }
}
public override string NamespaceURI {
get { return String.Empty; }
}
public override string Name {
get { return String.Empty; }
}
public override string Prefix {
get { return String.Empty; }
}
public override string Value {
get { return String.Empty; }
}
public override string BaseURI {
get { return String.Empty; }
}
public override String XmlLang {
get { return String.Empty; }
}
public override bool IsEmptyElement {
get { return false; }
}
public override XmlNameTable NameTable {
get { return null; }
}
public override bool HasAttributes {
get { return false; }
}
public override string GetAttribute(string localName,
string namespaceURI) {
return string.Empty;
}
public override bool MoveToAttribute(string localName,
string namespaceURI) {
return false;
}
public override bool MoveToFirstAttribute() {
return false;
}
public override bool MoveToNextAttribute() {
return false;
}
public override string GetNamespace(string name) {
return string.Empty;
}
public override bool MoveToNamespace(string name) {
return false;
}
public override bool MoveToFirstNamespace(XPathNamespaceScope
namespaceScope) {
return false;
}
public override bool MoveToNextNamespace(XPathNamespaceScope
namespaceScope) {
return false;
}
public override bool HasChildren {
get { return false; }
}
public override bool MoveToNext() {
return false;
}
public override bool MoveToPrevious() {
return false;
}
public override bool MoveToFirst() {
return false;
}
public override bool MoveToFirstChild() {
return false;
}
public override bool MoveToParent() {
return false;
}
public override void MoveToRoot() {}
public override bool MoveTo( XPathNavigator other ) {
return false;
}
public override bool MoveToId(string id) {
return false;
}
public override bool IsSamePosition(XPathNavigator other) {
return false;
}
public override XPathNodeIterator SelectDescendants(string name,
string namespaceURI, bool matchSelf) {
return null;
}
public override XPathNodeIterator SelectChildren(string name,
string namespaceURI) {
return null;
}
public override XPathNodeIterator
SelectChildren(XPathNodeType nodeType) {
return null;
}
public override XmlNodeOrder
ComparePosition(XPathNavigator navigator) {
return new XmlNodeOrder();
}
}
private static XPathNavigator _nav =
new DummyXpathNavigator();
public static XPathExpression Compile(string xpath) {
return _nav.Compile(xpath);
}
}
public class XPathCompilerTest {
static void Main(string[] args) {
//Document-free compilation
XPathExpression xe = XPathCompiler.Compile("/foo");
//Usage of the compiled expression
XPathDocument doc =
new XPathDocument(new StringReader("<foo/>"));
XPathNavigator nav = doc.CreateNavigator();
XPathNodeIterator ni = nav.Select(xe);
while (ni.MoveNext()) {
Console.WriteLine(ni.Current.Name);
}
}
}
I managed to transfer my xsl.info domain from NetworkSolutions (what an annoying registrar! terrible! very expensive!) to GoDaddy.com. Gosh, finally. Any ideas how to build it welcome.
Meanwhile XPath.info got a chance to get out its permanent under construction stage, more info coming soon!
I've got an invitation from Mono guys to consider contributing to Mono Managed XSLT Processor implemenation (now they have only a wrapper around libxslt engine). Well, we at Multiconn have designed and built one XSLT processor couple of years ago (it's quite specialized and highly (may be even too) optimized XSLT 1.0 engine for mainframe OLTP environment, written in ANSI C). It was great opportunity to learn XPath and XSLT thoroughly from cover to cover and it was actually cool (apart from programming in ANSI C nowadays). I definitely have some ideas about XSLT implementation, especially if you have C#, .NET plumbing available and considering rumors around next Microsoft .NET XSLT impl :). So it's really awfully tempting. But it's quite big open source project and I'm too busy unfortunately... I have long TODO list of not-less-interesing (but smaller) projects, I've started another article, I'm in MCAD cert preparation curve after all. And day work of course - we've just finished one trivial Web Service project, but another BizTalk-related one is on the horizon already. So I'm not sure...
Isn't it strange that Microsoft Outlook doesn't support reading newsgroups? Almost decided to move from Mozilla to Outlook 2003 today, but at the very last moment realized I have also to use Outlook Express for reading beloved newsgroups. That's really disappointing to use 2 apps instead of 1... so I'm still on Mozilla.
VSIP is free now. Terrific news!
One more logger with clunky text-based log file format and appropriate plumbing (object model, writer, parser and viewer) were written by me this week. Format was defined by customer and it was non disputable unfortunately. As for me it's just ugly. Why not use XML as log format? Pros: trivial writing/parsing, portability, readability, simplicity.
Constras: everybody seems to think it's unfeasible due to XML well-formedness and hence root element end tag problem - to append records you need to seek an appropriate place hence to parse the whole XML document. That's true for XML documents, but what about XML fragment?
XML fragment is actually external general parsed entity in XML 1.0 specification terms - it's freestanding fragment of XML, which can be incorporated into an XML document by entity reference, but it's still useful on its own - one can append elements to it (and because it's not XML document, root-level well-formedness rules don't apply to it, so one can just append elements to the end of file, without necessity to parse the whole log file) and then read such log file by XmlTextReader, which [thankfully to .NET developers] supports XML fragments (see "Reading XML Fragments with the XmlTextReader").
So here is small proof-of-concept example:
Writing to log:
class Test {
static void Main(string[] args) {
using (FileStream fs = File.Open("log.xml",
FileMode.Append, FileAccess.Write, FileShare.Read)) {
XmlTextWriter writer = new XmlTextWriter(fs, Encoding.ASCII);
for (int i=0; i<3; i++) {
writer.WriteElementString("item", "",
DateTime.Now.ToString());
writer.WriteWhitespace("\n");
}
writer.Close();
}
}
}
First run creates log.xml:
<item>7/22/2003 11:15:42 AM</item>
<item>7/22/2003 11:15:42 AM</item>
<item>7/22/2003 11:15:42 AM</item>
Second run appends three more items:
<item>7/22/2003 11:15:42 AM</item>
<item>7/22/2003 11:15:42 AM</item>
<item>7/22/2003 11:15:42 AM</item>
<item>7/22/2003 11:16:12 AM</item>
<item>7/22/2003 11:16:12 AM</item>
<item>7/22/2003 11:16:12 AM</item>
Reading log:
class Test {
static void Main(string[] args) {
using (FileStream fs = File.OpenRead("log.xml")) {
XmlParserContext context = new XmlParserContext(
new NameTable(), null, null, XmlSpace.Default);
XmlTextReader reader = new XmlTextReader(fs,
XmlNodeType.Element, context);
while (reader.Read()) {
if (reader.NodeType == XmlNodeType.Element) {
Console.WriteLine("Element: {0}, Value: {1}",
reader.Name, reader.ReadElementString());
}
}
}
}
}
And result is:
D:\projects\Test2\bin\Debug>Test2.exe
Element: item, Value: 7/22/2003 11:15:42 AM
Element: item, Value: 7/22/2003 11:15:42 AM
Element: item, Value: 7/22/2003 11:15:42 AM
Element: item, Value: 7/22/2003 11:16:12 AM
Element: item, Value: 7/22/2003 11:16:12 AM
Element: item, Value: 7/22/2003 11:16:12 AM
I like it. Comments?
A week with no internet connection at work - what could be more terrible? Finally it's over.
Don Box:
I started a new book today
Here's the first sentence:
Software lives at the boundary between objective and subjective reality.
More to follow.
Enough said.
This weekend I was completely unplugged, my wife took me away of computers and we drove to Tiberias. No laptop, no internet, just two days of swimming in the Sea of Galilee aka Kineret and fish-eating. It was great.

Apparently at the same time my article I was talking about finally made its appearance at XML Extreme Column of MSDN. Here it is: "Producing Multiple Outputs from an XSL Transformation". It's about how to achieve multiple output XSLT in .NET. My first article, so any comments espacially critical ones will be greatly appreciated. Is it well-written or at least clear? Should MultiXmlTextWriter be developed further? I've been thinking about HTML output method, this can be done by creating HTMLTextWriter:XmlWriter, like System.Web.UI.HtmlTextWriter one, but implementing XmlWriter instead. Probably not bad idea.
Like Tim Bray has no idea what to do with RDF.net domain he owned, I recalled today I own XPath.info and XSL.info domain names for almost two years now (since .info TLD was introduced back in 2001) and the same way never done a thing with them.
Why then did I register them? I don't know, there was a fever before .info were allowed and also there was sort of a lottery for the right to register .info domains, and I just filled a couple of preregistration forms and it turned out I won these two domains.
So, does anybody have any ideas what projects can be done at these domains? It would be nice to build sort of information repository at XSL.info for instance. Any volunteers, especially Web designers?
So version 1.2 of nxslt released.
Changes since 1.1:
- built-in support for 60 EXSLT extension functions (huge thanks to Dare)
- support for custom extension functions
- minor bug fixes
Built-in support for 60 EXSLT extension functions (yes, with conformant names :), full list of supported functions:
The killer!
New revelation from Chris Brumme, now about AppDomains. A must reading.
Have rummaged in http://www.simulation-argument.com all the morning.
Are You Living In a Computer Simulation? by Nick Bostrom
How to Live in a Simulation by Robin Hanson
Living in a Simulated Universe by John D. Barrow to name a few. Well, now the simulated programmer goes back to a simulating programming :)
Version 2.64 of Movable Type is now released. Security fixes and RSS 2.0 in the changelog. Upgraded without any hitch, good piece of software.
Here is another easy-to-solve-when-you-know-what-is-wrong problem. It took me couple of hours to find the solution, so I wanna share it. Hope it'll be useful to anybody.
The problem. When adding custom XPath extension functions as described in "HOW TO: Implement and Use Custom Extension Functions When You Execute XPath Queries in Visual C# .NET" KB article and "Adding Custom Functions to XPath" article at MSDN Extreme XML column you can find that any XPath expressions having namespace prefixes, like "/foo:bar" just can't be evaluated due to nasty System.ArgumentNullException deeply in the XPath engine.
The reason. It turned out that internal XPath classes, e.g. BaseAxisQuery expect custom XsltContext implementation to resolve namespaces prefixes (XsltContext extends XmlNamespaceManager) with respect to the NameTable, just as internal default XsltContext implementation - UndefinedXsltContext class does. The documentaion unfortunately omits that point and sample implementation in the above articles too.
The solution. Just override LookupNamespace(string prefix) method in your XsltContext implementation and pass given prefix through the NameTable:
public override string LookupNamespace(string prefix) {
if (prefix == String.Empty)
return String.Empty;
string uri = base.LookupNamespace(NameTable.Get(prefix));
if (uri == null)
throw new XsltException("Undeclared namespace prefix - " +
prefix, null);
return uri;
}
Easy, ain't it? I'm stupid spent two hours to get it.
Tim Bray on well-crafted spam: ongoing aloihin Backhuhn ambulant chopin. That's funny. You know, spam became a part of our life. But being behind mozilla's junk mail filtering I'd agree - we are winning.
Dare has published a new cool article at his MSDN Extreme XML column: "EXSLT: Enhancing the Power of XSLT". It's about Dare's implementation of 60+ EXSLT functions for .NET XSLT processor. Kudos! That was a pile of work due to number of functions, I'm sure the community will appreciate Dare's efforts to let users just write set:distinct(//foo) instead of using advanced Muenchian grouping method involving keys and fiddling with generated IDs just to get set of distinct nodes.
XSLT first of all is meant to be a declarative language, that's why such additional functionality worth much - it allows to keep declarative nature of the language in a real world allowing programmers to declare their intents and delegate actual implementation to an XSLT processor. Btw, forthcoming XPath 2.0 will provide even more: 200+ additional functions and operators!
One serious question is about function names: due to technical issues it's impossible in .NET to create XSLT extension function with hyphenated name, like add-duration(). That's because in .NET XSLT extension function names are reflected directly to extension object methods and afaik (I wish I'm wrong) there is no way to fake method's name other that hacking IL code in a compiled assembly. It really hurts portability, which is on the one hand what EXSLT initiative is about and I'm sure some people will say it's one more embrace-and-extend example of Microsoft politics. Come on, I'm not MSFT worker and believe me that's not the case, really. That's completely technical issue, I also desperately tried to find any clean workaround but with no success. Look at it from another point of view - XSLT programmers do really need these functions, and that's fine to give them EXSLT even if some functions have nonportable names.
Fortunately we've found a solution for another even more serious problem.
I believe Dare's implementation should outgrow article's boundaries and become a project on its own, e.g. at GotDotNet Workspaces, there is much room for enhancements and I'm sure more versions to come.
I'm going to provide EXSLT support to my nxslt pygmy - .NET XSLT command line utility, that should be handy to encapsulate (hacked to provide EXSLT-conformant function names?) Dare's implementation within nxslt and to get EXSLT-aware .NET XSLT processor. Tomorrow.
May Issue of .Net Developer Journal is available for free in PDF format. Good for those not subscribed like me.
[Via Roy Osherove].
Wow, while reading CORPORATE MOFO reloads THE MATRIX by Ken Mondschein I felt my flesh crawled when he shows how deep the ideas behind the Matrix movie can be. "cinematic ass-stomping" :) Worthwhile reading anyway. I knew it at the heart - the Matrix movie is just a postindustrial holy book evangelizing ancient ideas about the universe and insubstantial nature of the real world.
<silly-lyrical-digression>Before I became a programmer I was a guy mostly reading and trying to practice zen, gnostical apocryphs, Kastaneda, Gurdjieff and all that jazz. Prolonged rebel youth, hehe. Then being in a permanent deadlock I've modified myself into a techie, mostly reading and thinking about specs and practical life questions, that's who I am now. Actually I thought there is no way back and it was just a wacky wasted years, but now funny enough the Matrix movie makes me guessing it wasn't 180-degree turn and I'm still going my own way? Gurdjieff cannot be wrong after all: "There do exist enquiring minds, which long for the truth of the heart, seek it, strive to solve the problems set by life, try to penetrate to the essence of things and phenomena and to penetrate into themselves. If a man reasons and thinks soundly, no matter which path he follows in solving these problems, he must inevitably arrive back at himself, and begin with the solution of the problem of what he is himself and what his place is in the world around him."
</silly-lyrical-digression>
I like this from XSL-List by David Carlisle:
XSLT 2 appears to be based on user concerns and problems.
Apart from this character encoding feature (which is also useful in non
xml outout, eg outputting TeX commands in text output) It also has a lot
of help for grouping and of course user xslt defined portable extension
functions.
If only the same could be said for Xpath2....
Finally Matrix has been reloaded in Israel. Just back from the movie. Well, for sure I have to contemplate on that and to see it again, may be then I will be able to formulate my feelings...
Update: This hack is about .NET 1.X. In .NET 2.0 you don't need it. In .NET 2.0 with XslCompiledTransform class you can return a nodeset as XPathNodeNavigator[].
As all we know, unfortunately there is a confirmed bug in .NET Framework's XSLT implementation, which prevents returning a nodeset from an XSLT extension function. Basically the problem is that XSLT engine expects nodeset resulting from an extension function to be an object of internal ResetableIterator class. Full stop :(
Some workarounds were discovered, first one - to create new interim DOM object and query it by XPath, what returns instance of ResetableIterator class. Main deficiency - loss of nodes identity, because returned nodes belong to the interim DOM tree, not to input nodeset. Another workaround, discovered by Dimitre Novatchev is to to run interim XSL transformation within an extension function - this also allows to create instance of ResetableIterator class to return.
This morning I've found another workaround, which doesn't require creation of any interim objects. It's frontal attack and someone would call it a hack, but I wouldn't. Here it is. There is internal XPathArrayIterator class in System.Xml.XPath namespace, which represents XPathNodeIterator over ArrayList and also kindly implements our beloved ResetableIterator class. So why not just instantiate it by reflection and return from an extension function, huh?
Assembly systemXml = typeof(XPathNodeIterator).Assembly;
Type arrayIteratorType =
systemXml.GetType("System.Xml.XPath.XPathArrayIterator");
return (XPathNodeIterator)Activator.CreateInstance(
arrayIteratorType,
BindingFlags.Instance | BindingFlags.Public |
BindingFlags.CreateInstance,
null, new object[]{myArrayListofNodes},
null);
Below is proof-of-concept extension function to filter distinct nodes from a nodeset:
Extension function impl and test class:
using System;
using System.Xml.XPath;
using System.Xml.Xsl;
using System.IO;
using System.Reflection;
using System.Collections;
namespace Test2 {
class Test {
static void Main(string[] args){
XPathDocument doc = new XPathDocument(args[0]);
XslTransform trans = new XslTransform();
trans.Load(args[1]);
XsltArgumentList argList = new XsltArgumentList();
argList.AddExtensionObject("http://foo.com",
new MyXsltExtension());
trans.Transform(doc, argList, new StreamWriter(args[2]));
}
}
public class MyXsltExtension {
public XPathNodeIterator distinct(XPathNodeIterator nodeset) {
Hashtable nodelist = new Hashtable();
while(nodeset.MoveNext()) {
if(!nodelist.Contains(nodeset.Current.Value)) {
nodelist.Add(nodeset.Current.Value, nodeset.Current);
}
}
Assembly systemXml = typeof(XPathNodeIterator).Assembly;
Type arrayIteratorType =
systemXml.GetType("System.Xml.XPath.XPathArrayIterator");
return (XPathNodeIterator)Activator.CreateInstance(
arrayIteratorType,
BindingFlags.Instance | BindingFlags.Public |
BindingFlags.CreateInstance,
null, new object[]{new ArrayList(nodelist.Values)},
null);
}
}
}
Source xml doc (exsl:distinct()'s example):
<doc>
<city name="Paris"
country="France"/>
<city name="Madrid"
country="Spain"/>
<city name="Vienna"
country="Austria"/>
<city name="Barcelona"
country="Spain"/>
<city name="Salzburg"
country="Austria"/>
<city name="Bonn"
country="Germany"/>
<city name="Lyon"
country="France"/>
<city name="Hannover"
country="Germany"/>
<city name="Calais"
country="France"/>
<city name="Berlin"
country="Germany"/>
</doc>
Stylesheet:
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"
xmlns:ext="http://foo.com" extension-element-prefixes="ext">
<xsl:template match="/">
<distinct-countries>
<xsl:for-each select="ext:distinct(//@country)">
<xsl:value-of select="."/>
<xsl:if test="position() != last()">, </xsl:if>
</xsl:for-each>
</distinct-countries>
</xsl:template>
</xsl:stylesheet>
And the result is:
<distinct-countries>
Germany, Austria, Spain, France
</distinct-countries>
I like it. Comments?
Just released XInclude.NET 1.0beta.
Changes since 1.0alpha:
So enjoy.
Sometimes at rainy days of our life we can found ourself looking for a way to create something impossible, say a method containing dash in its name ;)
Well, if it seems to be impossible in one reality, try another one. It's impossible in C#, but it's possible in MSIL, so here is a hack:
- Disassemble your dll or executable using the MSIL Disassembler:
ildasm.exe /out=Lib.il Lib.dll
(Note, ildasm creates also resource file Lib.res along with Lib.il, you'll need this file afterwards).
-
Find your method in the decompliled MSIL (Lib.il), usually it looks like
.method public hidebysig instance string
FunnyMethod(string s) cil managed
and make its name more funny, inserting a dash (then you have to surround method's name by apostrophes to satisfy the syntax analyzer):
.method public hidebysig instance string
'Funny-Method'(string s) cil managed
- Now just assemble fixed MSIL file back to dll or executable using the MSIL Assembler:
ilasm.exe Lib.il /RESOURCE=Lib.res /DLL
That's it, you've created Lib.dll assembly, which contains Funny-Method(string) method in your class. Of course you can't invoke this method directly, but only through reflection, but sometimes that's enough.
Oh, and last thing - it's a hack, don't use it.
I've implemented XPointer support (shorthand pointer, xmlns(), element() and xpath1() schemas) for the XInclude.NET project.
(Btw, I'm wondering if XPointer may be useful not only in XInclude context?)
It was really fun and good exercise. Here are some details:
Parsing. XPointer grammar is actually one of the simplest and can be easily parsed even by regexp, as Gudge has demonstrated in his implementation. But I'm not regexp fan, especially for parsing. (I'm lex/yacc fan for ages). Instead I decided to write custom lexer and parser, just as .NET guys did for XPath and C#. Lexer (aka scanner) scans the expression char by char, taking care about escaping and builds low-level lexemes (NCName, QName, Number etc). Parser then assembles those lexemes into a higher-level grammar constructs (PointerPart, SchemaName, SchemaData etc) according to the grammar and builds XPointer object model, aka compiled XPointer pointer, ready for evaluation.
It took me the whole day, but now I can agree to some degree with Peter Hallam, when he explained why they didn't use lex/yacc in C# compiler - sometimes it's really more fast and maintainable than lex/yacc based solution.
Evaluating. Well, I chose easy way and implemented XPointer evaluation using XmlDocument, just as Gudge did. It's so attractively easy. XPathDocument though should be a better candidate from many points of view: performace (it's more optimized for XPath evaluation), memory footprint (it's read-only) and data model conformance (there are subtle differences between underlying XmlDocument and XPathDocument data models, e.g. about adjacent text nodes - DOM allows them, but XPath data model doesn't). I'll consider to move to XPathDocument later, that would additionally require XmlReader wrapper around XPathNavigator, but fortunately Don has solved that problem already.
That's it. It looks quite powerful and seems to be working fine. E.g.
<xi:inlcude href="test2.xml#xmlns(foo=http://foo.com)
xpath1(//foo:item[@name='bar'])
element(items3/2)"/>
This includes all item elements in "http://foo.com" namespace, which have "bar" as name attribute's value or if such not found for some reason it includes second child element of the element with "items3" ID.
Now cleaning, commenting, documenting, testing and releasing.
Working on XPointer parser for the XInclude.NET project I just realized there is no way (if I'm not mistaken) in .NET to check if a character is XML whitespace character. Plus all that functionality needed when parsing XML lexical constructs. No big deal, had to resort to old java trick:
public static bool IsWhitespace(char ch) {
return (ch <= 0x0020) &&
(((((1L << 0x0009) |
(1L << 0x000A) |
(1L << 0x000C) |
(1L << 0x000D) |
(1L << 0x0020)) >> ch) & 1L) != 0);
}
And that's a double pity, because XmlCharType class does implement all that XML-related lexical jazz in a very optimized way, but it's internal and not all of its power is exposed through other means (e.g. it's possible to verify a string as XML NCName using XmlConvert.VerifyNCName(string) method, which leverages XmlCharType underneath).
More good news: as Joshua Allen has confirmed, they are working on making XmlReader easier to implement. Primarily by "making some stuff that is currently abstract virtual". I look forward to see it.
New XSLT 2.0 Working Draft has been published. Interesting changes since November 2002 version:
- A new bunch of date/time formatting functions.
- "It is now a static error for xsl:call-template to supply a parameter whose name does not match the name of any parameter declared in the called template.". Wow, that's incompatible change, XSLT 1.0 allows it.
- All serialization questions are moved to the new "XSLT and XQuery Serialization" WD.
- "It is now an error to reference the context item from a global variable definition, if no initial context node is supplied to the stylesheet."
- New instruction, xsl:next-match, which allows to apply matching templates, but with lower precedence and/or priority.
- A replacement for notorious disable-output-escaping feature - xsl:character-map instruction.
- The xsl:value-of instruction and attribute value templates now output all values in the supplied sequence, unless backwards compatible behavior is enabled.
- New system properties: xsl:product-name, xsl:product-version, xsl:is-schema-aware, xsl:supports-serialization and xsl:supports-backwards-compatibility.
Also 9 (yes, nine) other XPath/XQuery/XSLT related Working Drafts have been published, see http://www.w3.org/TR.
Gudge
thinks it's better to expose synthetic xml:base attribute as first one in order to solve access-by-index problem. Sounds convincing. I actually didn't implement index-based access yet, but only access by navigational methods MoveToFirstAttribute()/MoveToNextAttribute()/MoveToAttribute(). Last one is obvious, and in first and second ones my logic was as follows - when core method call returns false, I treat it as there-is-no-more-attributes and switch the state machine to exposing synthetic xml:base attribute, so it's always latest one.
But I wasn't clear about my main concern in this topic - in fact xml:base attribute might not be
synthetic if a top-level included element has already xml:base attribute. In this case according to XInclude spec its value should be replaced hence in GetAttribute(int index)/this[int index] method if index is existing xml:base attribute's index, another value should be returned, so the question is how to find out existing xml:base attribute's index without resorting to interim attribute collection.
Quite interesting analysis by Chris Suellentrop, unexpected conclusion - Neo is an early adopter of the Matrix product.
[Via Robert McLaws.]
The world is getting better. And the Word too! Word 2003 Beta2 now understands not only those *.doc files, but XML also. It's all as it should be in open XML world (what makes some people suspicious): there is WordML vocabulary, its schema (well documented one, btw) is available as part of Microsoft Word XML Content Development Kit Beta 2. Having said that it's obvious to go on and to assume that Word documents now may be queried using XPath or XQuery as well as transformed and generated using XSLT. Isn't it fantastic?
So here is "Hello Word!" XSLT stylesheet, which generates minimal, while still valid Word 2003 document:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<xsl:processing-instruction
name="mso-application">progid="Word.Document"</xsl:processing-instruction>
<w:wordDocument
xmlns:w="http://schemas.microsoft.com/office/word/2003/2/wordml">
<w:body>
<w:p>
<w:r>
<w:t>Hello Word!</w:t>
</w:r>
</w:p>
</w:body>
</w:wordDocument>
</xsl:template>
</xsl:stylesheet>
That <?mso-application progid="Word.Document"?> processing instruction is important one - that's how Windows recognizes an XML document as Word document. Seems like they parse only XML document prolog looking for this PI. Good idea I think.
Now let's try something more interesting - transform some XML document to formatted Word document, containing heading, italic text and link. Consider the following source doc:
<?xml-stylesheet type="text/xsl" href="style.xsl"?>
<chapter title="XSLT Programming">
<para>It's <i>very</i> simple. Just ask <link
url="http://google.com">Google</link>.</para>
</chapter>
Then XSLT stylesheet (quite big one due to verbose element-based WordML syntax):
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:w="http://schemas.microsoft.com/office/word/2003/2/wordml">
<xsl:template match="/">
<xsl:processing-instruction
name="mso-application">progid="Word.Document"</xsl:processing-instruction>
<w:wordDocument>
<xsl:apply-templates/>
</w:wordDocument>
</xsl:template>
<xsl:template match="chapter">
<o:DocumentProperties>
<o:Title>
<xsl:value-of select="@title"/>
</o:Title>
</o:DocumentProperties>
<w:styles>
<w:style w:type="paragraph" w:styleId="Heading3">
<w:name w:val="heading 3"/>
<w:pPr>
<w:pStyle w:val="Heading3"/>
<w:keepNext/>
<w:spacing w:before="240" w:after="60"/>
<w:outlineLvl w:val="2"/>
</w:pPr>
<w:rPr>
<w:rFonts w:ascii="Arial" w:h-ansi="Arial"/>
<w:b/>
<w:sz w:val="26"/>
</w:rPr>
</w:style>
<w:style w:type="character" w:styleId="Hyperlink">
<w:rPr>
<w:color w:val="0000FF"/>
<w:u w:val="single"/>
</w:rPr>
</w:style>
</w:styles>
<w:body>
<w:p>
<w:pPr>
<w:pStyle w:val="Heading3"/>
</w:pPr>
<w:r>
<w:t>
<xsl:value-of select="@title"/>
</w:t>
</w:r>
</w:p>
<xsl:apply-templates/>
</w:body>
</xsl:template>
<xsl:template match="para">
<w:p>
<xsl:apply-templates/>
</w:p>
</xsl:template>
<xsl:template match="i">
<w:r>
<w:rPr>
<w:i/>
</w:rPr>
<xsl:apply-templates/>
</w:r>
</xsl:template>
<xsl:template match="text()">
<w:r>
<w:t xml:space="preserve"><xsl:value-of
select="."/></w:t>
</w:r>
</xsl:template>
<xsl:template match="link">
<w:hlink w:dest="{@url}">
<w:r>
<w:rPr>
<w:rStyle w:val="Hyperlink"/>
<w:i/>
</w:rPr>
<xsl:apply-templates/>
</w:r>
</w:hlink>
</xsl:template>
</xsl:stylesheet>
And the resulting WordML document, opened in Word 2003:
Not bad.
Gudge is mediatating on exposing synthetic attributes in XmlReader.
Here are some details on how I've implemented synthetic xml:base attribute in the XIncludingReader.
List of members implementing the logic:
MoveToAttribute(), MoveToFirstAttribute(), MoveToNextAttribute(), ReadAttributeValue(), HasValue, IsDefault, Name, LocalName, NamespaceURI, NodeType, Prefix, QuoteChar, MoveToNextAttribute(), ReadAttributeValue(), Value, ReadInnerXml(), ReadOuterXml(), ReadString(), AttributeCount, GetAttribute().
It's 20 (+ overloaded ones), yeah, in SAX it's much easier, but anyway that's not a rocket engineering - it's only 2-3 lines in each member after all. I wonder if in V2 XML API something would be changed, they say they are working on improving the piping also.
Another point - I'm exposing xml:base on the fly, as last attribute (as Gudge has properly supposed), but this approach doesn't help with GetAttribute(int)/MoveToAttribute(int) methods, probably I have to collect all existing attributes to some collection once and operate only on it afterwards.
I've released first alpha version of XInclude.NET library today. Once I got xml:base working and meekly passed through XInclude Conformance Test Suite with almost no fails I decided to release this stuff. There is still plenty room for optimizations and XPointer is still not supported, anyway I like "release early/often" motto. So enjoy and file bugs :).
Exposing a virtual xml:base attribute in XmlReader was really a showstopper. I solved it by introducing simple state machine and fiddling with it in MoveToNextAttribute(), ReadAttributeValue() and other attribute-related methods.
So, XPointer is now the agenda. I still believe it's possible to avoid using
XmlDocument's or XPathDocument facilities, because that assumes loading the whole document into memory. element() schema and shorthand pointer both should be implementable in a forward-only manner, the only problem here is how to determine ID-typed attributes, which would require reading DTD or even schema. Hmmm, well, will see.
Everyone seems to be talking about WordML these days and it sounds really intriguing. Dare has posted a link to the Microsoft Word XML Content Development Kit Beta 2, which contains WordML XML schema.
Don Box is transforming WordML to RSS20+XHTML and says it's easier than transfroming HTML+CSS due to nonXML CSS format.
My interest though is quite opposite - to see if it's possible to transform another XML data to WordML or to put it into another way - how to implement XSLT users' ancient dream - to transform to a Word document.
WordML schema is well documented one - that's great news, well done guys. And as far as I can see it's not more complicated that XSL-FO format is, so it should be pretty doable.
So I'll give it a shot some time next week, after XInclude.NET 1.0alpha release.
Web Services rock! As I found out BizTalk Server is actually dead and is going to be transformed to Jupiter suite this year.
Not surprisingly, Jupiter is Web Services-based product. It will use Business Process Execution Language for Web Services and integrated with Office and Visual Studio.NET.
Chances are I'll be involved in a project, which uses first Jupiter beta soon, so I'm happy I shouldn't learn all that boring BizTalk stuff, but BPEL4WS instead.
Finally. Gudge has posted his C# implementation of XInclude CR. It's XmlReader-based, with XPointer support, fairly elegant, simple and very interesting. Especially to compare with GotDotNet XInlcude.NET impl.
After a quick look I can say of course it's much more elegant than my implementation. More structured and well-designed, while probably less caring about details. Unfortunately to me it seems like Gudge has omitted xml:base attribute generation problem, I was hoping he'll solve in a usual magic way. That's the only problem left in XInlcude.NET project before we can ship first alpha version.
What's the problem? When an element is included from another document with different base URI, the xml:base attribute should be added/substituted to this element to preserve its (and its descendants) base URI.
Sounds simple. When top-level included element item is read through XIcludingReader, xml:base attribute should be exposed if it doesn't exist else its value should be modified. It requires probably some state fiddling in MoveToNextAttribute() and other attributes-related methods. My first idea is to check when MoveToNextAttribute() returns false and then switch the reader to some new EXPOSING_XML_BASE state to emulate xml:base attribute. Anyway I'll try to implement it tomorrow.
According to GotDotNet download statistics my MultiXmlTextWriter class has been downloaded 398 times, while last version of nxslt utility, which includes it to support multioutput XSLT - only 91. Hmm, looks like people prefer a component to build own solutions rather than old-fashioned versatile command line tool (not really prominent observation, huh?).
My article about getting multple outputs in XSLT under .NET I was talking about probably will be published in June. That's my first authoring experience. Day-to-daily I write code documentation and specifications , but never an article, so I'm kinda worrying about it.
It's Passover holiday week in Israel now so I have the whole week free to be devoted to interesting things (well, almost free, I have also to study BizTalk until the end of the month) . So let's get back to Xinclude.NET project.
<?foreteller-mode on?>
This is new Apache FOP logo:

<?foreteller-mode off?>
Will see if I can predict anything, voting is still on ;)
Ivelin Ivanov has published first installment of a new regular column on XML.com, "Practical XQuery" -
XML.com: Processing RSS [Apr. 09, 2003].
The article's example looks quite provocative - generating of HTML from two XML sources (RSS feeds). I bet the first thought of many devs would be "Come on, that's XSLT's job for ages!". Indeed, even 3-years old XSLT 1.0 can easily perform such transformation at a very newbie level, so it's fairly enough to ask - "Why do we need one more language?".
Actually, this example just illustrates XML Query Requirements', first Usage Scenario:
Perform queries on structured documents and collections of documents, such as technical manuals, to retrieve individual documents, to generate tables of contents, to search for information in structures found within a document, or to generate new documents as the result of a query.
Sounds similar, huh?
So this is really a gray area, where XSLT and XQuery do overlap. The task of generating new document based on a source document may be thought either as source2result transformation or as building new document basing on a source querying. And I don't see what's wrong with that, both languages (XSLT2.0 and XQuery1.0 to be technically correct) may greatly complement each other. Many people don't like XSLT just because its XML-based syntax, many others don't take its rule-based nature and of course there is an horde hunger to return to their habitual procedural programming style. Many of them should be happy with XQuery. Not bad?
Keeping provocative line I would ask - isn't XQuery strongly typed subset of XSLT2?
Kirk Allen Evans has posted a recursive XSLT template to transform CSV into XML.
Being low-level substring functions based it's obviously quite verbose and convolute, what was fairly enough pointed out by Dare. He has provided 10-lines C# version also.
What I wanted to add to this subject is that such example perfectly illustrates how radically EXSLT extensions may improve XSLT 1.0 coding. (btw, Dare is working on the implementation of EXSLT functions for .NET and I believe it would be great addition to .NET XSLT programming practice). Look yourself: here is EXSLT version, which makes use of str:tokenize extension function (note, even smaller than Dare's C# one):
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:str="http://exslt.org/strings" exclude-result-prefixes="str">
<xsl:include href="d:/xsl/str.tokenize.msxsl.xsl"/>
<xsl:template match="root">
<root>
<xsl:for-each select="str:tokenize(.,'
')">
<row>
<xsl:for-each select="str:tokenize(.,',')">
<elem><xsl:value-of select="."/></elem>
</xsl:for-each>
</row>
</xsl:for-each>
</root>
</xsl:template>
</xsl:stylesheet>
So, XSLT perfectly able to handle this, it just needs tokenizing facility, like C# has and what for producing XML - IMO XSLT is the best hammer on the market.
I agree though that for pure CSV2XML conversion XSLT may be not a right tool, if it was my project, I'd make use of SAX filter or something like Chris Lovett's XmlCsvReader.
Oracle XDK v10 Beta Release supports XSLT 2.0, XPath 2.0 and
XPath 2.0 Data Model (all working drafts dated 11th November 2002). It's not clear to which extent all that jazz is supported, but anyway, that's good news.
And AFAIK Apache guys at Xalan team are working on Xalan 3.0, so more to come.
I'm moving to a new house these days, so practical life's questions totally occupy me, I just have no time to blog unfortunately. Hope I'll pop back in a week or so. Main question bothering me is how to get DSL before Passover holiday week in Israel has started, two days countdown.
Don Box's Spoutlet:
In the interest of generality, Simon asks if there is an XmlReader implementation that traverses an XPathNavigator.
Such implementation seems to be trivial, but an interesting point is that such XPathNavigatorReader could easily give xpath1() XPointer schema support for our XInclude.NET project!
And if I'm right in my assumption that element() XPointer schema can be translated to xpath1() schema on the fly by changing any NCName to id(NCName) and any numbers to *[number], this will give us also element() schema support with almost no efforts.
I'll elaborate it further on XInclude.NET Message Board.
Kirk Allen Evans's asking hard questions:
Should there be an XIncludeNodeList implementation that is the product of the merged Infosets? Or is this irrelevant since it would only apply to a fully-loaded DOM instance, which should already have been loaded?
I believe XInclude should keep low level of XML processing - just after XML parsing, before (or optionally after) validation, and surely before DOM or XPathDocument building and XSL transformations. This way it can stay simple and transparent.
Should loading an XIncludeDocument be in any part asynchronous?
Hmmm. What if we just feed XmlDocument through XIncludeReader to preserve XmlDocument own async loading logic?
Should the first version of XIncludeReader support XPointer? If so, to what degree? Should we only support the XPointer elements() scheme?
Well, XInclude rec requires (must level) support for XPointer Framework (probably it's about shorthand pointer) and element() schema. But I'm not sure about the very first version. Many other XInclude implementations don't support XPointer, so it's not a problem to omit it for a while. But certanly we have to take into account XPointer processing in XInclude.NET even in the first version.
I guess this all boils down to answering "How complete should revision 1 be?"
Yeah, that's the key question. Well, I personally have no idea, probably no support for XPointer at all should be our first milestone, why not?
What a mail I got today from Taiwan, really nice one:
")
"Mozilla thinks this message is junk mail". Well, probably ;)
Rambling in the blog space, found Alexis Smirnov's blog and there a link to quite interesting article named "Xslt Transformations and Xslt Intellesense within the .NET IDE" by Doug Doedens. It's about how to make XSLT authoring easier and more convenient in Visual Studio.NET.
That sounds similar to what I've been thinking about last few days - to implement for VS.NET all that XSLT-related authoring features I used to in XML Spy. Apart from adding XSLT schema to allow IntelleSense drop down hints, which is trivial as described in this article, I plan (but when?) to build VS.NET addin to allow one-click/one-key transformations with support for xml-stylesheet processing instruction. I've got some prototype already, hope it'll grow to something useful.
 I have released nxslt version 1.1. I have released nxslt version 1.1.
nxslt is .NET XSLT command line utility, written in C#.
Timings are now more accurate, I'm using System.Diagnostics.PerformanceCounter class now.
Two new features: custom URI resolver and multiple output.
First one is trivial - it's now possible to provide a resolver class name to resolve URI's in xsl:include, xsl:import elements and document() function. So basically nxslt is ready for
XML Catalogs, lets just wait till any .NET implementation appears. Actually I have considered to implement it, but decided XInclude.NET project looks more interesting to me at the moment.
Multiple output - using partially supported exsl:document extension element it's now possible to create multiple result documents in one transformation run. Extremely powerful stuff, believe me. I would like not to unveil implementation details though (haha, it's open source) as I'm going to publish an article about it.
So enjoy. nxslt can be used in command line or integrated into IDE, such as XML Spy or Xselerator. btw, wouldn't it be nice to intergate it with VS.NET? I imagine one-click XSLT transformation inside VS.NET XML editor for instance.
Dino Esposito has published a quite comprehensive article, named
Real-World XML: Manipulate XML Data Easily with Integrated Readers and Writers in the .NET Framework in May MSDN mag issue.
While reading the article two things caught my eye - usual negation of SAX usefulness and another API quirk, which should be remembered.
-
Being particlularly fan of XML pull processing I nevertheless don't understand why one may completely deny usefulness of push processing. I like both push and pull, why to limit myself to only one? Pull is good when application knows what it wants to pull out, and push is good for generic rule based processing.
"All the functions of a SAX parser can be implemented easily and more effectively by using an XML reader."
I'm still not convinced, in next version of XmlReader API may be, but not now. Consider MSDN example of attributes to elements convertor, based on XmlTextReader. Hmm, state machinery, 4 overrided members... And here is SAX version:
import org.xml.sax.*;
import org.xml.sax.helpers.*;
public class Attrs2ElementsFilter extends XMLFilterImpl {
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException {
AttributesImpl newAttributes = new AttributesImpl();
super.startElement(namespaceURI, localName,
qualifiedName, newAttributes);
for (int i = 0; i < atts.getLength(); i++) {
super.startElement("", atts.getLocalName(i),
atts.getQName(i), newAttributes);
super.characters(atts.getValue(i).toCharArray(), 0,
atts.getValue(i).length());
super.endElement("", atts.getLocalName(i),
atts.getQName(i));
}
}
}
As for me, SAX won in this particular task.
-
Quirky one, need-to-be-remembered. (Sure they will change it in the V2 API).
While the API allows XmlReader as argument to XmlValidatingReader constructor, it must be XmlTextReader.
Note that although the signature of one of the XmlValidatingReader constructors refers generically to an XmlReader class as the underlying reader, that reader can only be an instance of the XmlTextReader class or a class which derives from it. This means that you cannot use any class which happens to inherit from XmlReader (such as a custom XML reader). Internally, the XmlValidatingReader class assumes that the underlying reader is an XmlTextReader object and specifically casts the input reader to XmlTextReader. If you use XmlNodeReader or a custom reader class, you will not get any error at compile time but an exception will be thrown at run time.
I believe being bored some rainy evening Tim Bray has just decided to make a little stress test of XML community. Remember ongoingXML is too hard for programmers? Now read ongoingWhy XML Doesn't Suck.
XPointer goes to Recommendation today. Remember XPointer? It's about "pointing", i.e. identifying of XML parts or fragments. Well, after monsntrous XPath2 specs XPointer one looks like a miniature work. (It reminds me XPath1, which was about 30 pages also).
XPointer (funny enough, no version defined for the language) consists of 3 quite small documents:
- XPointer Framework, which defines basic semantics and syntax of XML addressing/fragment identifying.
- element() scheme, funny XPath-like syntax for pointing to elements in XML, e.g. "element(intro/3/1)" - which identifies first child of third child of the element with "intro" ID.
- xmlns() scheme, for dealing with namespaces in pointers.
Editors are just living legends: Norman Walsh, Jonathan Marsh, Eve Maler and Paul Grosso. They decided to leave the most powerful and (therefore?) contradictory xpointer() schema out of this release, it's still frozen at WD stage. Implemeters feels relief today probably.
Anyway, happy sailing in XML ocean, XPointer. There are many against you, but you can make it.
As a matter of fact main thing I wanted to say is that this event effectively means XInclude, which greatly depends on XPointer and still stays in Candidate Rec bed apparently may be also released very soon. So it's really right time to push my (our now) GotDotNet XInclude.NET
project. In fact that involves XPointer implementation also, so there is a big pile of design and coding here. We desperately need more volunteers, I urge everybody interested in free implementation of XInclude for .NET platform to participate.
They say it's snowing in Jerusalem again (at the end of March!) and as I can see outside it's hailing, thundering and heavily raining here near of Tel-Aviv.
I know, winter rains are a blessing for Israel, Kineret goes up 10cm everyday and this is daily-good-news here. Still almost two meters below the ecologically normal red line today:
But I don't know why it all makes me pessimistic. Blogs are almost empty these days, 100 emails at the morning was probably this year minimum, newsgroups are more dead than alive, the stuff I was working on last few weeks has stuck at the final stage for the reason I have no influence on... Well, I need to start doing something new and fresh, so I'm going to return to XInclude for .NET project. Kirk Allen has joined the team yesterday, probably more invitations are needed, lets spam newsgroups then ;)
PS. At least such news save me from the depression:
Well, blogging is really infectious disease and finally I got the infection. I have installed Movabletype engine on my site quite easily (c'mon, it's cgi based) and here is my first record.
Lets see how it works. Administering is not bad and default template looks really nice, but I'm sure I'll modify all the style once I get some free time.
I named my blog "Signs on the Sand" (it took me the whole evening and the night to formulate my feelings), because I believe that's what all these words worth and that's their final destiny. Hmmm, whatever, I like it.
So happy blogging to me.
|
|



")

Recent Comments