2006 Archives
And the winners are Dave Pawson and Leon Bambrick. Both of them are getting Visual Studio 2005 Team Suite with 1 year MSDN Premium Subscription. Congrats guys! I hope it will help with your work and so benefit the community.
Sorry to the rest - I only have 2 cards to give away...
Now, Dave and Leon please contact me ASAP. I'm on vacation in heavily raining Seattle and tomorrow will be on 2 days flight back to Israel, while your offer is expired Dec 31.
XslCompiledTransform implements the following useful MSXML extension functions. But what if you need to use them in XPath-only context - when evaluating XPath queries using XPathNavigator?
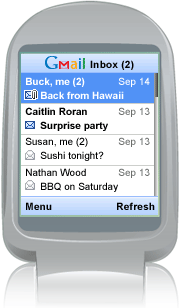 Gmail client for mobile devices was released by Google a month ago. It's Java ME MIDP2 application, cool looking as one could expect from Google. I went and installed it last week on my Motorola V3X. Gmail client for mobile devices was released by Google a month ago. It's Java ME MIDP2 application, cool looking as one could expect from Google. I went and installed it last week on my Motorola V3X.
Well, I found out that while Gmail for mobile work on hundreds of different mobile devices, it doesn't work on mine. I've got weird error message "Sorry, the Gmail mobile app will not work on your phone. Your phone doesn't have the appropriate certificate to communicate with Gmail. Try accessing Gmail on your mobile browser at http://m.gmail.com". It sucks. Apparently my phone lacks that Verisign Class 3 public certificate. Apparently that's known problem and on some phones it can be solved by adding that certificate available from Verisign. Alas, it seems to be impossible to add another root certificate to Motorola V3X phone - I was trying every single way - via Motorola Phone Tools, Bluetooth obex, P2K drivers - nothing helps. Even if I put new certificate into /a/mobile/certs/root/x509/kjava/ folder the phone still won't recognize it. Motodev support didn't help - "Can I help you? What is Gmail for mobile? Give me URL. It clearly says Download Gmail for the Motorola V3 RAZR (US/Canada). You are from Israel. Issue closed." Well, I still hope someone would solve this problem for Motorola phones too.
I saw today Josh Christie post about "Better HTML parsing and validation with HtmlAgilityPack". HtmlAgilityPack is an open source project on CodePlex. It provides standard DOM APIs and XPath navigation -- even when the HTML is not well-formed! Well, DOM and XPath over malformed HTML isn't new idea. I've been using XPath when screenscraping HTML for years - it seems to me way more reliable method that regular expressions. All you need in .NET is to read HTML as XML using wonderful SgmlReader from Chris Lovett. SgmlReader is an XmlReader API over any SGML document such as HTML. But what I don't get is why would anyone (but browser vendors) want to implement DOM and XPath over HTML as is? Reimplementing not-so-simple XML specs over malformed source instead of making it wellformed and using standard API? May be I'm not agile anough but I don't think that's a good idea. I prefer standard proven XML API. Here is Josh's sample that validates that Microsoft's home page lists Windows as the first item in the navigation sidebar implemented using SgmlReader: SgmlReader r = new SgmlReader();
r.Href = "http://www.microsoft.com";
XmlDocument doc = new XmlDocument();
doc.Load(r);
//pick the first <li> element in navigation section
XmlNode firstNavItemNode =
doc.SelectSingleNode("//div[@id='Nav']//li");
//validate the first list item in the Nav element says "Windows"
Debug.Assert(firstNavItemNode.InnerText == "Windows"); I stay with SgmlReader.
 I completely forgot that I still have one Visual Studio 2005 Team Suite with MSDN Premium Subscription gift card to give away. And it expires 12/31! Oh boy, what do I do now??? So for the next 2 weeks I'll be holding the "The Coolest XML Project Contest". I completely forgot that I still have one Visual Studio 2005 Team Suite with MSDN Premium Subscription gift card to give away. And it expires 12/31! Oh boy, what do I do now??? So for the next 2 weeks I'll be holding the "The Coolest XML Project Contest".
Better late than never - forthcoming Java 6 (currently Release Candidate) will include StAX, pull based streaming XML API. .NET has pull based XML parser (XmlReader) from the very beginning and Microsoft was arguing .NET's XmlReader is better than SAX since at least 2002. No, I'm not saying Java catches .NET up with one more feature, no. I'm just glad I wil be able to parse XML using the same model and very similar API on both platforms.
I was building NAnt and MSBuild tasks for the nxslt tool last two days and the bottom line of my experience is "previously I thought NAnt sucks, but now I know NAnt is brilliant and it's MSBuild who sucks really big way". My complaints about NAnt were that - NAnt being .NET Ant clone somehow has different license - while Java Ant is under Apache License, NAnt is under GPL. Now that Sun GPL-ed Java it might sound no big deal, but I personally was in a situation when a project manager said no we won't use NAnt because it's GPL and we don't want such a component in our big bucks product.
- NAnt core dlls aren't signed. That in turn means I can't sign my assembly and so can't put it into GAC. Weird.
Really minor ones as I realize now. Besides - NAnt is brilliant. While MSBuild appears to be more rigid and limited. Apparently it's impossible to create MSBuild task that uses something more than just attributes. I mean in NAnt I have this: <nxslt in="books.xml" style="books.xsl" out="out/params1.html">
<parameters>
<parameter name="param2" namespaceuri="foo ns" value="param2 value"/>
<parameter name="param1" namespaceuri="" value="param1 value"/>
</parameters>
</nxslt>
MSBuild doesn't seem to be supporting such kind of tasks. MSBuild task only can have attributes, not children elements. It can have references to some global entities defined at the project level, such as properties and task items. At first I thought task items seem good candidates for holding XSLT parameters, because task items can have arbitrary metadata. And that's exactly how the Xslt task from the MSBuild Community Tasks Project passes XSLT parameters: <ItemGroup>
<MyXslFile Include="foo.xsl">
<param>value</param>
</MyXslFile>
</ItemGroup>
<Target Name="report" >
<Xslt Inputs="@(XmlFiles)"
Xsl="@(MyXslFile)"
Output="$(testDir)\Report.html" />
</Target>
Parameters here get attached to an XSLT file item definition, which seems to be reasonable until you realize that you might want to run the same stylesheet with different parameters?
And what worse - above is actually plain wrong because it only provides "name=value" for a parameter, while in XSLT a parameter name is QName, i.e. XSLT parameter is a "{namespace URI}localname=value". And item metadata happens to be limited only to plain name=value. Metadata element can't have attributes or namespace prefix or be in a namespace... It's clear that MSBuild task item is a bad place to define XSLT parameters for my task.
Last option I tried and on which I settled down is defining XSLT task parameters as global MSBuild project properties. Thanks God at least properties can have arbitrary XML substructure! Here is how it looks: <PropertyGroup>
<XsltParameters>
<Parameter Name="param1" Value="value111"/>
<Parameter Name="param2" NamespaceUri="foo ns" Value="value222"/>
</XsltParameters>
</PropertyGroup>
<Target Name="transform">
<Nxslt In="books.xml" Style="books.xsl" Out="Out/params1.html"
Parameters="$(XsltParameters)"/>
</Target>
And here is how you implement it: create a string property "Parameters" in your task class. At the task execution time this property will receive <XsltParameters> element content (as a string!). Parse it with XmlReader and you are done. Beware - it's XML fragment, so parse it as such (ConformanceLevel.Fragment).
Two problems with this approach - it makes me to define parameters globally, not locally (as in NAnt) - hence if I have several transformations in one project I should carefully watch out which parameters are for which transformation. Second - XML content as a string??? Otherwise it's good enough.
Tomorrow I'm going to finish documenting the nxslt NAnt/MSBuild task and release it.
I'm missing something obvious and spent already about two hours on that simple problem. I hope somebody profficient in MSBuild drops me a line. How do I build MSBuild custom task that has XML subtree? Here is my NAnt task: <nxslt in="books.xml" style="books.xsl" out="out/catalog.html">
<parameters>
<parameter name="param1" namespaceuri="" value="val1"/>
</parameters>
</nxslt> How do I build custom MSBuild task that accepts such <parameters> subtree??? The documentation on MSBuild sucks. I mean it's fine if you just using tasks, but if you want to build your own task you screwd up.
 ISO published RELAX NG standard (also "Compact Syntax") for free at the "Freely Available Standards" page. Hmmm, since when ISO provides free standard downloads? ISO published RELAX NG standard (also "Compact Syntax") for free at the "Freely Available Standards" page. Hmmm, since when ISO provides free standard downloads?
Also: Schematron, NVDL and more. [Via Rick Jelliffe]
I've been reading about XProc, new XML Pipeline language proposed by W3C. Used to control and organize the flow of documents, the XProc language standardizes interactions, inputs and outputs for transformations for the large group of specifications such as XSLT, XML Schema, XInclude and Canonical XML that operate on and produce XML documents. The "Proc" part stands for "Processing", so it's XML processing language. Here is a sample "validate and transform" pipeline just to give you a taste of what XProc is about: 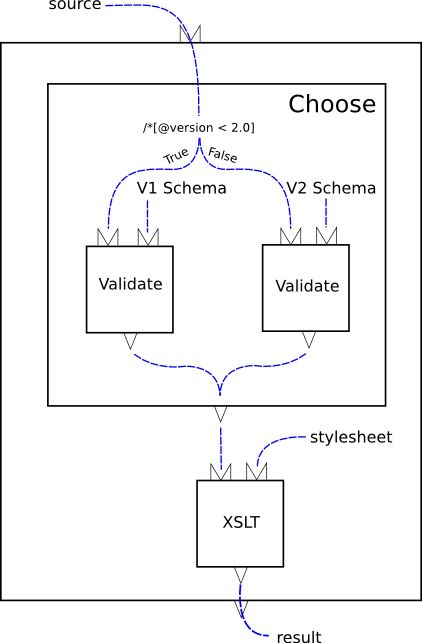
Here is how it's expressed: <p:pipeline name="fig2"
xmlns:p="http://example.org/PipelineNamespace">
<p:input port="doc" sequence="no"/>
<p:output port="out" step="xform" source="result"/>
<p:choose name="vcheck" step="fig2" source="doc">
<p:when test="/*[@version < 2.0]">
<p:output name="valid" step="val1" source="result"/>
<p:step type="p:validate" name="val1">
<p:input port="document" step="fig2" source="doc"/>
<p:input port="schema" href="v1schema.xsd"/>
</p:step>
</p:when>
<p:otherwise>
<p:output name="valid" step="val2" source="result"/>
<p:step type="p:validate" name="val2">
<p:input port="document" step="fig2" source="doc"/>
<p:input port="schema" href="v2schema.xsd"/>
</p:step>
</p:otherwise>
</p:choose>
<p:step type="p:xslt" name="xform">
<p:input port="document" step="vcheck" source="valid"/>
<p:input port="stylesheet" href="stylesheet.xsl"/>
</p:step>
</p:pipeline>
Syntax can spoil everything. We need visual XProc editor!
After all I think it's pretty damn good idea. I need it now. And we've got everything in .NET to implement it - XInclude, XSLT, validation, Canonical XML. So I'm going for this. This will be great addition to the Mvp.Xml project.
Here are some XProc resources to get you started:
- The XProc specification.
- XProc.org, the site tracking the progress of the XML Processing Model Working Group, maintained by Norman Walsh, chair of the WG. Lots of stuff, including XProc Wiki.
- public-xml-processing-model-comments mail list.
- Wikipedia article on the "XML pipeline"
- Norman Walsh's introductory essay on XProc, update.
- "Step By Step: Why XML Pipelines Make Sense" by Kurt Cagle.
- What people say about XProc - http://feeds.technorati.com/search/xproc
Just couple of months after XML Notepad 2006 release Microsoft ships another version, now called XML Notepad 2007. They even went and edited the article "XML Notepad 2006 Design" to be "XML Notepad 2007 Design". Cool. XML Notepad 2006 was released on the 1st September 2006, and 2 months later it had 175,000 downloads! So it looks like this little utility has found a useful place in your toolkit which is exactly what we were hoping. Thanks for all the great feedback and bug reports; many of which have been incorporated and fixed in this new version. While this is mostly a bug fix release (like fixing the install on Vista!) there are also a few new features thrown in just for fun. New in this version: - Added keyboard accelerators for find again (F3) and reverse find (SHIFT+F3).
- Added support for loading IXmlBuilder and IXmlEditor implementations from different assemblies using new vs:assembly attribute.
- Made source code localizable by moving all error messages and dialog strings to .resx files.
- Added a default XSL transform.
- New icons, a play on the Vista "Notepad" icons.
XML Notepad 2006 2007 is a tree view based XML editor, and it's not in my tool list because I can't work with XML editor which won't show me XML source, but then I'm XML geek and I feel more comfortable seeing angle brackets than tree view, while I'm sure lots of people will love it. Give it a try anyway. .gif)
I only wonder why all this stuff isn't in Visual Studio? Why is that Microsoft XML team can afford playing with another XML editor while Visual Studio XML Editor still sucks having no XML diff, no XPath search, no refactoring, no decent XSLT editor nor XML Schema designer?
Back in 2005 I was writing about speeding up Muenchian grouping in .NET 1.X. I was comparing three variants of the Muenchian grouping (using generate-id(), count() and set:distinct()). The conclusion was that XslTransform class in .NET 1.X really sucks when grouping using generate-id(), performs better with count() and the best with EXSLT set:distinct(). Here is that old graph: 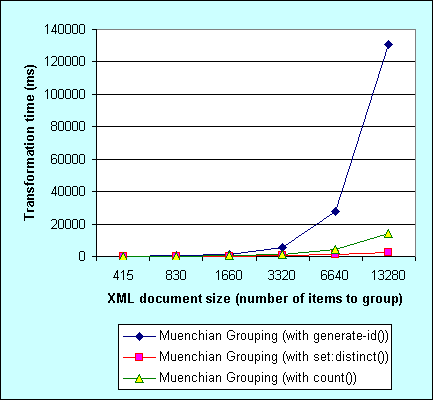
Today a reader reminded me I forgot to post similar results for .NET 2.0 and its new shiny XslCompiledTransform engine. So here it is. I was running simple XSLT stylesheet doing Muenchian grouping. Input documents contain 415, 830, 1660, 3320, 6640, 13280, 26560 and 53120 orders to be grouped. 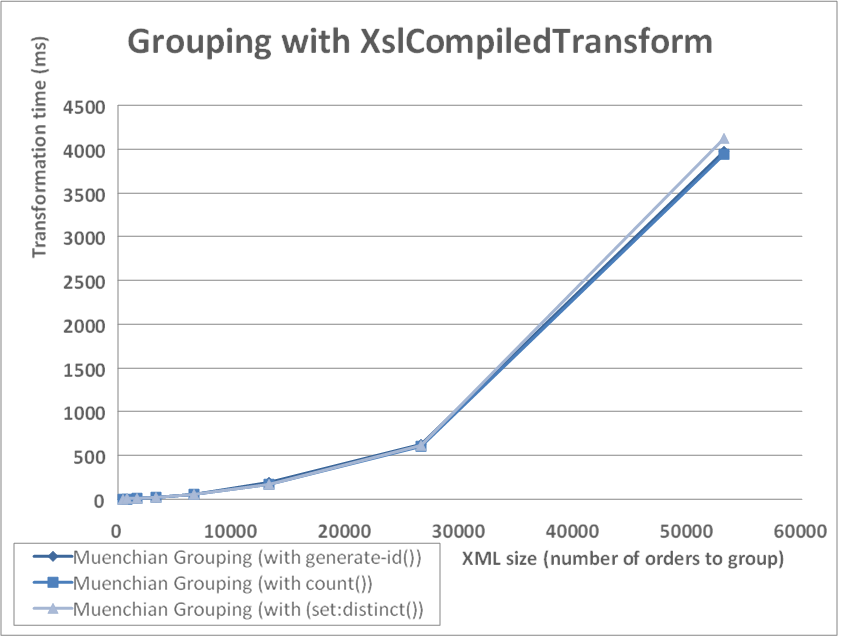
Besides being pretty damn faster that XslTransform, XslCompiledTransform shows expected results - there is no difference in a way you are doing Muenchian grouping in .NET 2.0 - all three variants I was testing are performing excellent with very very close results. Old XslTransform was full of bad surprises. Just switching to count() instead of generate-id() provided 7x performance boost in grouping. That was bad. Anybody digging into XslTransform sources knows how ridiculously badly generate-id() was implemented. Now XslCompiledTransform shows no surprises - works as expected. No tricks needed. That's a sign of a good quality software.
 From TSS.Net I found out that Raymond Chen, the man who can make Win32 programming exciting, published a book "The Old New Thing: Practical Development Throughout the Evolution of Windows". "The Old New Thing" is of course the name of his blog, described as "not actually a .NET blog". The book is to be available December 29. I want this book. From TSS.Net I found out that Raymond Chen, the man who can make Win32 programming exciting, published a book "The Old New Thing: Practical Development Throughout the Evolution of Windows". "The Old New Thing" is of course the name of his blog, described as "not actually a .NET blog". The book is to be available December 29. I want this book.
Why does Windows work the way it does? Why is Shut Down on the Start menu? And why is there a Start menu? Many of Windows' quirks have logical causes rooted in history. In The Old New Thing: Practical Development Throughout the Evolution of Windows, Raymond Chen, of Microsoft's Windows development team, reveals the "hidden Windows" developers and users need to understand. Chen helps readers understand Windows with behind-the-scenes explanations, technical information, and anecdotes. Topics include window and dialog management, performance optimization and why it can be so counterintuitive, an under-the-hood look at COM and the Visual C++ compiler, backwards compatibility, and little-known Windows program security holes. TSS.Net also publishes two chapters: Chapter One of The Old New Thing, titled "Initial Forays into User Interface Design," describes why Windows is the way it is. Chen answers some of the most frequently asked questions about the user interface, and tells the story and reasoning behind each tough decision and rule that the Windows team had to implement.
Download Chapter One: Initial Forays into User Interface Design Chapter Three of Chen's book, titled "The Secret Life of GetWindowText," addresses the complexity of GetWindowText, giving the full story behind the documentation. Chen also explains the compromises made around GetWindowText, and ways to escape its rules. Download Chapter Three: The Secret Life of GetWindowText Chapter one is particularly cool: - Why do you have to click the Start button to shut down?
- Why doesn’t Windows have an “expert mode”?
- The default answer to every dialog box is Cancel
- In order to demonstrate our superior intellect, we will now ask you a question you cannot answer
- Why doesn’t Setup ask you if you want to keep newer versions of operating system files?
- User interface design for vending machines
- User interface design for interior door locks
- The evolution of mascara in Windows UI
Reporting errors in XSLT stylesheets is a task that almost nobody gets done right. Including me - error reporting in nxslt sucks in a big way. Probably that's because I'm just lazy bastard. But also lets face it - XslCompiledTransform API doesn't help here. Whenever there are XSLT loading (compilation) errors XslCompiledTransform.Load() method throws an XsltException containing description of the first error encountered by the compiler. But as a matter of fact internally XslCompiledTransform holds list of all errors and warnings (internal Errors property). It's just kept internal who knows why. Even Microsoft own products such as Visual Studio don't use this important information when reporting XSLT errors - Visual Studio's XML editor also displays only first error. That sucks. Anyway here is a piece of code written by Anton Lapounov, one of the guys behind XslCompiledTransform. It shows how to use internal Errors list via reflection (just remember you would need FullTrust for that) to report all XSLT compilation errors and warnings. The code is in the public domain - feel free to use it. I'm going to incorporate it into the next nxslt release. I'd modify it a little bit though - when for some reason (e.g. insufficient permissions) errors info isn't available you still have XsltException with at least first error info. private void Run(string[] args) {
XslCompiledTransform xslt = new XslCompiledTransform();
try {
xslt.Load(args[0]);
}
catch (XsltException) {
string errors = GetCompileErrors(xslt);
if (errors == null) {
// Failed to obtain list of compile errors
throw;
}
Console.Write(errors);
}
}
// True to output full file names, false to output user-friendly file names
private bool fullPaths = false;
// Cached value of Environment.CurrentDirectory
private string currentDir = null;
///
/// Returns user-friendly file name. First, it tries to obtain a file name
/// from the given uriString.
/// Then, if fullPaths == false, and the file name starts with the current
/// directory path, it removes that path from the file name.
///
private string GetFriendlyFileName(string uriString) {
Uri uri;
if (uriString == null ||
uriString.Length == 0 ||
!Uri.TryCreate(uriString, UriKind.Absolute, out uri) ||
!uri.IsFile
) {
return uriString;
}
string fileName = uri.LocalPath;
if (!fullPaths) {
if (currentDir == null) {
currentDir = Environment.CurrentDirectory;
if (currentDir[currentDir.Length - 1] != Path.DirectorySeparatorChar) {
currentDir += Path.DirectorySeparatorChar;
}
}
if (fileName.StartsWith(currentDir, StringComparison.OrdinalIgnoreCase)) {
fileName = fileName.Substring(currentDir.Length);
}
}
return fileName;
}
private string GetCompileErrors(XslCompiledTransform xslt) {
try {
MethodInfo methErrors = typeof(XslCompiledTransform).GetMethod(
"get_Errors", BindingFlags.NonPublic | BindingFlags.Instance);
if (methErrors == null) {
return null;
}
CompilerErrorCollection errorColl =
(CompilerErrorCollection) methErrors.Invoke(xslt, null);
StringBuilder sb = new StringBuilder();
foreach (CompilerError error in errorColl) {
sb.AppendFormat("{0}({1},{2}) : {3} {4}: {5}",
GetFriendlyFileName(error.FileName),
error.Line,
error.Column,
error.IsWarning ? "warning" : "error",
error.ErrorNumber,
error.ErrorText
);
sb.AppendLine();
}
return sb.ToString();
}
catch {
// MethodAccessException or SecurityException may happen
//if we do not have enough permissions
return null;
}
}
Feel the difference - here is nxslt2 output: An error occurred while compiling stylesheet 'file:///D:/projects2005/Test22/Test22/test.xsl':
System.Xml.Xsl.XslLoadException: Name cannot begin with the '1' character, hexadecimal value 0x31.
And here is Anton's code output: test.xsl(11,5) : error : Name cannot begin with the '1' character, hexadecimal value 0x31.
test.xsl(12,5) : error : Name cannot begin with the '0' character, hexadecimal value 0x30.
test.xsl(13,5) : error : The empty string '' is not a valid name.
test.xsl(14,5) : error : The ':' character, hexadecimal value 0x3A, cannot be included in a name.
test.xsl(15,5) : error : Name cannot begin with the '-' character, hexadecimal value 0x2D.
It's surprisingly easy in .NET 2.0. Obviously it can't be done with pure XSLT, but an extension function returning line number for a node takes literally two lines. The trick is to use XPathDocument, not XmlDocument to store source XML to be transformed. The key is IXmlLineInfo interface. Every XPathNavigator over XPathDocument implements this interface and provides line number and line position for every node in a document. Here is a small sample: using System;
using System.Xml;
using System.Xml.XPath;
using System.Xml.Xsl;
public class Test
{
static void Main()
{
XPathDocument xdoc = new XPathDocument("books.xml");
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load("foo.xslt", XsltSettings.TrustedXslt,
new XmlUrlResolver());
xslt.Transform(xdoc, null, Console.Out);
}
}<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:ext="http://example.com/ext"
extension-element-prefixes="ext">
<ms:script implements-prefix="ext"
xmlns:ms="urn:schemas-microsoft-com:xslt" language="C#">
public int line(XPathNavigator node)
{
IXmlLineInfo lineInfo = node as IXmlLineInfo;
return lineInfo != null ? lineInfo.LineNumber : 0;
}
</ms:script>
<xsl:template match="/">
<foo>
<xsl:value-of select="ext:line(//book)">
</foo>
</xsl:template>
</xsl:stylesheet>
Ability to report line info is another reason to choose XPathDocument as a store for your XML (in read-only scenarios such as query or transformation) - in addition to better performance and smaller memory footprint.
If you really need the same, but with XmlDocument, you have to extend DOM.
I'm finally decided to switch web hosting. I'm currently on webhost4life, but I'm really not up to that "4life" part. It's getting slower and slower while people seem to be runnig away from them. So I'm looking for ASP.NET hosting recommendations. I need to host at least 3 domains with DotnetNuke, CommunityServer, MS SQL, MySQL, nothing special. I've heard both good and bad words about ASPNix, but what about HostingFest? Where do you host your Windows stuff? Update: problem totally solved, got hosting I couldn't even dream about. All like me mentally retarded Microsoft MVPs - subscribe to the private "3rd offers" newsgroup now, I mean NOW!
If you are up to Microsoft certification you might be interested in this new offer from Microsoft called Exam Insurance: Get two chances to pass your Microsoft Certification exam With Microsoft Exam Insurance, you can retake a Microsoft Certification exam if you need to. You'll have two chances to pass and validate your knowledge of critical IT job functions. Or, pass on your first try and save 25 percent on your next exam You'll receive a 25 percent discount on any future Microsoft Certification exam. With each additional Microsoft Certification that you earn, you'll be further along the path to getting the recognition you deserve. Really sounds like a win-win situation. The offer expires May 2007 and is available exclusively through Microsoft Certified Partners for Learning Solutions.
 W3C presented Planet Mobile Web site aggregating multiple blogs that discuss Mobile Web. It's hosted by the W3C Mobile Web Initiative. Really interesting reading. W3C presented Planet Mobile Web site aggregating multiple blogs that discuss Mobile Web. It's hosted by the W3C Mobile Web Initiative. Really interesting reading.  Subscribed. Subscribed.
I skimmed some posts and it looks like the million dollar question every mobile blogger now think about is "how the hell we can get AJAX work on the mobile???". Mobile Web 2.0 is another revolution still waiting to happen.
 Man is driven to create; I know I really love to create things. And while I’m not good at painting, drawing, or music, I can write software. I believe that the purpose of life is, at least in part, to be happy. Based on this belief, Ruby is designed to make programming not only easy, but also fun. It allows you to concentrate on the creative side of programming, with less stress. Yukihiro Matsumoto, inventor of Ruby I just started learning Ruby and I already feel it might be the language I love (well, after XSLT of course).
 W3C announced the Mobile Web Best Practices 1.0 as Proposed Recommendation: W3C announced the Mobile Web Best Practices 1.0 as Proposed Recommendation:
Written for designers of Web sites and content management systems, these guidelines describe how to author Web content that works well on mobile devices. Thirty organizations participating in the Mobile Web Initiative achieved consensus and encourage adoption and implementation of these guidelines to improve user experience and to achieve the goal of "one Web." Read about the Mobile Web Initiative. That's actually a very interesting document. It's definitely a must for anybody targeting Mobile Web, which is a very different from the Web we know and it's not only because of limitations: Mobile users typically have different interests to users of fixed or desktop devices. They are likely to have more immediate and goal-directed intentions than desktop Web users. Their intentions are often to find out specific pieces of information that are relevant to their context. An example of such a goal-directed application might be the user requiring specific information about schedules for a journey they are currently undertaking. Equally, mobile users are typically less interested in lengthy documents or in browsing. The ergonomics of the device are frequently unsuitable for reading lengthy documents, and users will often only access such information from mobile devices as a last resort, because more convenient access is not available. Still there is dream about "One Web": The recommendations in this document are intended to improve the experience of the Web on mobile devices. While the recommendations are not specifically addressed at the desktop browsing experience, it must be understood that they are made in the context of wishing to work towards "One Web". As discussed in the Scope document [Scope], One Web means making, as far as is reasonable, the same information and services available to users irrespective of the device they are using. However, it does not mean that exactly the same information is available in exactly the same representation across all devices. The context of mobile use, device capability variations, bandwidth issues and mobile network capabilities all affect the representation. Furthermore, some services and information are more suitable for and targeted at particular user contexts (see 5.1.1 Thematic Consistency of Resource Identified by a URI). Some services have a primarily mobile appeal (location based services, for example). Some have a primarily mobile appeal but have a complementary desktop aspect (for instance for complex configuration tasks). Still others have a primarily desktop appeal but a complementary mobile aspect (possibly for alerting). Finally there will remain some Web applications that have a primarily desktop appeal (lengthy reference material, rich images, for example). It is likely that application designers and service providers will wish to provide the best possible experience in the context in which their service has the most appeal. However, while services may be most appropriately experienced in one context or another, it is considered best practice to provide as reasonable experience as is possible given device limitations and not to exclude access from any particular class of device, except where this is necessary because of device limitations. From the perspective of this document this means that services should be available as some variant of HTML over HTTP. What about "Web 2.0"? Well, No support for client side scripting. I recently got Motorola RAZR V3X - cool 3G phone (btw 3G really rocks) and all of a sudden I'm all about Mobile Web. This is fascinating technology with huge future. I've got lots of plans that gonna make me millions... if I only had some more spare time :(
Remember that catchy RubyCLR motto? 
Now C# (Anders Hejlsberg) is playing catch up talking about automatic properties: public string Bar { get; set; }Above is meant to be translated by a compiler into private string foo;
public string Bar
{
get { return foo; }
set { foo = value; }
}
Now I'm not sure I like reusage of the abstract property notation, but still way to go guys.
Just one morning topics: Wikipedia Used To Spread Virus "The German Wikipedia has recently been used to launch a virus attack. Hackers posted a link to an all alleged fix for a new version of the blaster worm. Instead, it was a link to download malicious software. They then sent e-mails advising people to update their computers and directed them to the Wikipedia article. Since Wikipedia has been gaining more trust & credibility, I can see how this would work in some cases. The page has, of course, been fixed but this is nevertheless a valuable lesson for Wikipedia users." Wikipedia and Plagiarism Daniel Brandt found the examples of suspected plagiarism at Wikipedia using a program he created to run a few sentences from about 12,000 articles against Google Inc.'s search engine. He removed matches in which another site appeared to be copying from Wikipedia, rather than the other way around, and examples in which material is in the public domain and was properly attributed. Brandt ended with a list of 142 articles, which he brought to Wikipedia's attention.... 'They present it as an encyclopedia," Brandt said Friday. "They go around claiming it's almost as good as Britannica. They are trying to be mainstream respectable.'" Long-Term Wikipedia Vandalism Exposed "The accuracy of Wikipedia, the free online encyclopedia, came into question again when a long-standing article on 'NPA personality theory' was confirmed to be a hoax. Not only had the article survived at Wikipedia for the better part of a year, but it had even been listed as a 'Good Article,' supposedly placing it in the top 0.2-0.3% of all Wikipedia articles — despite being almost entirely written by the creator of the theory himself." Good thing is that once discoveded all problems were immediately cleared and offenders banned. Wikipedia is really fast on fixing problems. The concusion is of course - Wikipedia is a great free resource, but don't believe everything you read there.
When working with XPath be it in XSLT or C# or Javascript, apostrophes and quotes in string literals is the most annoying thing that drives people crazy. Classical example is selections like "foo[bar="Tom's BBQ"]. This one actually can be written correctly as source.selectNodes("foo[bar=\"Tom's BBQ\"]"), but what if your string is something crazy as A'B'C"D" ? XPath syntax doesn't allow such value to be used as a string literal altogether- it just can't be surrounded with neither apostrophes nor quotes. How do you eliminate such annoyances? The solution is simple: don't build XPath expressions concatenating strings. Use variables as you would do in any other language. Say no to selectNodes("foo[bar=\"Tom's BBQ\"]")
and say yes to selectNodes("foo[bar=$var]")
How do you implement this in .NET? System.Xml.XPath namespace provides all functionality you need in XPathExpression/IXsltContextVariable classes, but using them directly is pretty much cumbersome and too geeky for the majority of developers who just love SelectNodes() method for its simplicity.
The Mvp.Xml project comes to rescue providing XPathCache class: XPathCache.SelectSingleNode("//foo[bar=$var]",
doc, new XPathVariable("var", "A'B'C\"D\""))
And this is not only stunningly simple, but safe - remember XPath injection attacks?
You can download latest Mvp.Xml v2.0 drop at our new project homepage at the Codeplex.
 This is a great picture my wife took. It's Tel-Aviv beach view from a landing plane. Speaking of Tel-Aviv, we've got something unusual happenning here. There was a tornado near the beach and UFO over the city. Btw, I believe I've seen that tornado while driving to work via Tel-Aviv. This is a great picture my wife took. It's Tel-Aviv beach view from a landing plane. Speaking of Tel-Aviv, we've got something unusual happenning here. There was a tornado near the beach and UFO over the city. Btw, I believe I've seen that tornado while driving to work via Tel-Aviv.
  Remember this famous Mars face? So recently NASA found another one, here in the Earth, in Australia actually. They call it "Ghostly Face In South Australian Desert". I first though it's about upside-down face that reminds Dali paintings, but no. Can you see a ghost face here? That's really stupid, but still cool picture. Btw, if you are not yet subscribed to the NASA Earth Observatory you might want. They publish some really cool pictures every week. Remember this famous Mars face? So recently NASA found another one, here in the Earth, in Australia actually. They call it "Ghostly Face In South Australian Desert". I first though it's about upside-down face that reminds Dali paintings, but no. Can you see a ghost face here? That's really stupid, but still cool picture. Btw, if you are not yet subscribed to the NASA Earth Observatory you might want. They publish some really cool pictures every week.
I still own xsl.info and xpath.info domain names and still have no time to build anything around there. If anybody have any ideas about any community driven projects - let me know, I'm willing to donate domain name and may be participate. And if anybody want to buy these domain names - I'm willing to sell.
.NET's XmlReader is a great XML parser, but it has one big flaw in its API: XmlReader doesn't expose attribute types. XML actually defines 8 attribute types: CDATA, ID, IDREF, IDREFS, ENTITY, ENTITIES, NMTOKEN, NMTOKENS. Yes, it's DTD, which apparently Microsoft considers to be dead, but ID, IDREF, IDREFS types are really important ones. They provide support for cross-references and many XML languages rely on them, particularly XPath, XSLT, XQuery, XPointer, XInclude. That means XmlReader cannot be used to develop third-party implementations of those languages unless one sticks to XPathDocument/XmlDocument, which know attribute types internally. I wonder if XLinq will have this information, because if not - XSLT over XLinq won't be supporting id() function. Btw, in Java SAX and Stax both happily expose attribute types... Makes me envy. I though I filed it as a bug years ago, but I didn't. So although it's too late, here it is. I'm sure it will be another "thanks for suggestion, we'll consider it for the next release", but anyway. Vote please whoever cares.
Another coding horror story was reported in the microsoft.public.dotnet.xml newsgroup: I've been experiencing OutOfMemory errors on our prodution webserver for a few weeks now. I've finally managed to isolate (I think) the problem to our use of c# script blocks in our xsl files.
While debugging I discovered that the app domain for one of our sites had 13000+ assemblies loaded. Cool. This is just a remainder for those who use XSLT scripting (msxsl:script) in .NET: watch out, this feature can be pure evil if used unwisely - it leaks memory and there is nothing you can do about it. The problem is that when XSLT stylesheet is loaded in .NET, msxsl:script is compiled into an assembly via CodeDOM and then loaded into memory, into the current application domain. Each time the stylesheet is loaded above process is repeated - new assembly is being generated and loaded into the application domain. But it's impossible to unload an assembly from application domain in .NET! Here is KB article on the topic. It says it applies to .NET 1.0 only, but don't be confused - the problem exists in .NET 1.1 and 2.0. Moreover I'm pretty much pessimistic about if it's gonna be fixed in the future. The solution is simple - just don't use script in XSLT unless you really really really have to. Especially on the server side - XSLT script and ASP.NET should never meet unless you take full resonsibility for caching compiled XslCompiledTransform. Use XSLT extension objects instead. Update. Of couse Yuriy reminds me that msxsl:script runs faster than an extension object, because msxsl:script is available at compile time and so XSLT compiler can generate direct calls, while extension objects are only available at run-time and so can only be called via reflection. That makes msxsl:script a preferrable but danger solution when your stylsheet makes lots of calls to extension functions. In a perfect world of course msxsl:script would be compiled into dynamic methods (just like XSLT itself), which are GC reclaimable, but I don't think CodeDOM is capable of doing this currently. I wonder if it's possible to compile C#/VB/J# method source into dynamic method anyway? Also it's interesting how to improve extension objects performance - what if extension objects could be passed at compile time? They are usually available anyway at that time too. Or what if compiled stylesheet could be "JITted" to direct calls instead of reflection? Sergey, Anton, can you please comment on this?
Joe Fawcett, XML expert and my fellow XML MVP has started a blog. Highly recommended. Subscribed.
 Ok, I'm off on vacation for 3 weeks. We gonna visit our families in Ukraine and introduce to them our little Catherine. Ok, I'm off on vacation for 3 weeks. We gonna visit our families in Ukraine and introduce to them our little Catherine.
AppDev is giving away these Microsoft training CDs. Free shipping in the US, nominal shipping charge outside. Quite impressive list: - Visual C# 2005: Developing Applications
- Visual Basic 2005: Developing Applications
- ASP.NET Using Visual C# 2005
- ASP.NET Using Visual Basic 2005
- Visual Studio 2005 Tools for Microsoft Office
- Exploring ASP.NET "Atlas" and Web 2.0
- Exploring Visual C# 2005
- Exploring Visual Basic 2005
- Exploring ASP.NET Using Visual C# 2005
- Exploring ASP.NET Using Visual Basic 2005
Visual Studio .NET - Developing Applications Using Visual C# .NET
Visual Basic .NET - ASP.NET Using Visual C# .NET
- ASP.NET Using Visual Basic .NET
- Exploring BizTalk Server 2006
- Exploring Microsoft SQL Server 2005
- Microsoft SQL Server 2005
- Microsoft SQL Server 2000
- Managing and Maintaining Windows Server 2003 (for MCSE or MCSA)
- Developing Applications Using Visual C# .NET (for MCSD or MCAD)
- Visual Basic .NET (for MCSD or MCAD)
- Microsoft SQL Server 2000 (for MCDBA)
This is just a paradise for XML geeks: Extreme Markup Languages 2006 Conference Proceedings Online. Happy reading: Blazevic, Mario. "Streaming component combinators." In Proceedings of Extreme Markup Languages 2006. Brown, Alex. "Frozen streams: an experimental time- and space-efficient implementation for in-memory representation of XML documents using Java." In Proceedings of Extreme Markup Languages 2006. Bryan, Martin. "DSRL - Bringing Revolution to XML Workers." In Proceedings of Extreme Markup Languages 2006. Chatti, Noureddine, Sylvie Calabretto and Jean Marie Pinon. "MultiX: an XML based formalism to encode multi-structured documents." In Proceedings of Extreme Markup Languages 2006. Clark, John L. "Structured Software Assurance." In Proceedings of Extreme Markup Languages 2006. Collins, Brad. "Sticky Stuff: An Introduction to the Burr Metadata Framework." In Proceedings of Extreme Markup Languages 2006. Dubin, David, Joe Futrelle and Joel Plutchak. "Metadata Enrichment for Digital Preservation." In Proceedings of Extreme Markup Languages 2006. Freese, Eric. "From Metadata to Personal Semantic Webs." In Proceedings of Extreme Markup Languages 2006. Gangemi, Joseph V. "XML for Publishing." In Proceedings of Extreme Markup Languages 2006. Gutentag, Eduardo. "Intellectual property policy for the XML geek." In Proceedings of Extreme Markup Languages 2006. Halpin, Harry. "XMLVS: Using Namespace Documents for XML Versioning." In Proceedings of Extreme Markup Languages 2006. Hennum, Erik. "Representing Discourse Models in RDF." In Proceedings of Extreme Markup Languages 2006. Lubell, Joshua, Boonserm (Serm) Kulvatunyou, KC Morris and Betty Harvey. "Implementing XML Schema Naming and Design Rules: Perils and Pitfalls." In Proceedings of Extreme Markup Languages 2006. Marcoux, Yves. "A natural-language approach to modeling: Why is some XML so difficult to write?" In Proceedings of Extreme Markup Languages 2006. M?ldner, Tomasz, Gregory Leighton and Jan Krzysztof Miziolek. "Using Multi-Encryption to Provide Secure and Controlled Access to XML Documents." In Proceedings of Extreme Markup Languages 2006. Novatchev, Dimitre. "Higher-Order Functional Programming with XSLT 2.0 and FXSL." In Proceedings of Extreme Markup Languages 2006. Pepper, Steve, Valentina Presutti, Lars Marius Garshol and Fabio Vitali. "Reusing data across Topic Maps and RDF." In Proceedings of Extreme Markup Languages 2006. Quin, Liam. "Microformats: Contaminants or Ingredients? Introducing MDL and Asking Questions." In Proceedings of Extreme Markup Languages 2006. Souzis, Adam. "RxPath: a mapping of RDF to the XPath Data Model." In Proceedings of Extreme Markup Languages 2006. Sperberg-McQueen, C. M. "Rabbit/duck grammars: a validation method for overlapping structures." In Proceedings of Extreme Markup Languages 2006. Tennison, Jeni. "Datatypes for XML: the Datatyping Library Language (DTLL)." In Proceedings of Extreme Markup Languages 2006. Wrightson, Ann. "Conveying Meaning through Space and Time using XML: Semantics of Interoperability and Persistence." In Proceedings of Extreme Markup Languages 2006.
Dimitre Novatchev has uploaded another FXSL 2.0 release. FXSL is the best ever XSLT library: The FXSL functional programming library for XSLT provides XSLT programmers with a powerful reusable set of functions and a way to implement higher-order functions and use functions as first class objects in XSLT . Now XPath 2.0 functions, operators and constructors as well as XSLT 2.0 functions have "higher-order FXSL wrappers that makes possible to use them as higher order functions and to create partial applications from them". To fully understand the value of this stuff take a look at Dimitre's article "Higher-Order Functional Programming with XSLT 2.0 and FXSL".
 First hundred users of the AdSense Watch Toolbar and first nasty bug - when language other than English is set up for an AdSense account at Google the CSV report cannot be parsed. Apparently googlers generate CSV report in a localized form - headers are translated and numbers are in a locale-specific format. Weird. What about separation data and presentation, huh? Why on earth CSV report needs to be localized? It must be pure data in an easy to process form. Google doesn't think so. First hundred users of the AdSense Watch Toolbar and first nasty bug - when language other than English is set up for an AdSense account at Google the CSV report cannot be parsed. Apparently googlers generate CSV report in a localized form - headers are translated and numbers are in a locale-specific format. Weird. What about separation data and presentation, huh? Why on earth CSV report needs to be localized? It must be pure data in an easy to process form. Google doesn't think so.
Ok, I figured out that if I add "&hl=en" to the end of CSV report request I get CSV file in English no matter what language AdSense account works with. Good enough. I updated AdSense Watch Toolbar installation to fix this issue. If anybody got "Cannot parse AdSense data" error, download new version please.
SPI Dynamics has published a whitepaper "Ajax Security Dangers": While Ajax can greatly improve the usability of a Web application, it can also
create several opportunities for possible attack if the application is not
designed with security in mind. Since Ajax Web applications exist on both the
client and the server, they include the following security issues:
• Create a larger attack surface with many more inputs to secure
• Expose internal functions of the Web application server
• Allow a client-side script to access third-party resources with no builtin
security mechanisms
From all dangers one sounds the most horrible - authors claim that "Ajax Amplifies XSS". Ajax allows cross-site scripting (XSS) attacks to spread like a virus or worm. And that's not an imaginary threats, the attacks are already happening. The first widely known AJAX worm was "Samy worm" or "JS.Spacehero worm" hits 1,000,000+ MySpace users in less than 20 hours back in 2005 and then again. In 2006 "The Yamanner worm" infested Yahoo Mail and managed to capture thousands email addresses and uploaded them to a still unidentified Web site. Provided that the problem wasn't that Yahoo or MySpace staff is incompetent: "The problem isn't that Yahoo is incompetent. The problem is that filtering JavaScript to make it safe is very, very hard," said David Wagner, assistant professor of computer science at the University of California at Berkeley It's for sure just a matter of time before Google or Microsoft Ajax based applications will be hacked, not to mention vendors with less experienced developers driving to Ajax by the hype and widely leveraging "cut and paste” coding technique. "JavaScript was dangerous before Ajax came around," noted Billy Hoffman, lead R&D researcher at SPI Dynamics Inc., a computer security firm. With the addition of Ajax functionality in many other Web applications, the problem is going to get worse before it gets better, he said. Pessimistic summary, but what would you expect in a "Worse is Better" world?
Congratulations to all XSLT geeks - Dimitre Novatchev, XSLT extraordinaire is blogging! Whoha! Subscribed.
Ward Cunningham: "Wiki is the original Web 2.0 application." Read the Ward Cunningham talking on "Wikis, Patterns, Mashups and More". Interestng one.
I'm finishing another plugin for Visual Studio 2005, which will allow to one-click run XSLT transformations using different XSLT processors. Visual Studio 2005 can only perform XSLT transformations using XslCompiledTransform and that's not enough for XSLT geeks. To make Visual Studio 2005 a real XSLT IDE it must be able to run different XSLT engines, including XSLT 2.0 engines. The idea of such plugin comes from Dimitre Novatchev. I really hope to release first beta next week.
This is pretty cool blog post editor. I'm gonna test it and if it's ok I switch to Windows Live Writer cause wbloggar seems to be dead. Works fine with my MovableType powered blog also and has all features I need. Allows plugins to be added, cool huh? I want a plugin for autolinking certain words, wouldn't it be cool? I wonder if the SDK allows such plugins. What other plugins would be useful?
This Lebanon war had a terrible impact on my personal productivity. Too much TV, too much internet, too much pain, too little work. Hope it ends soon. Anyway I decided I need some short victorious war, oops I mean small interesting project to get me back on track. I've seen AdSense Notifier plugin for Firefox another day and I thought - cool, but I don't run Firefox 100% time, I want it on Windows taskbar, not a browser statusbar. So I had a spike project and got it working in just one night. Then I spent another two weeks polishing it. Ahhhhh, a joy of good old pure win32, MFC-free, just Windows and you and nothing in between. Unmanaged C++, LPTSTR, HWND, messages, win32 multithreading - sweet, I'm in The Old New Thing world again. The result is AdSense Watch Toolbar.   AdSense Watch is a Windows Explorer toolbar (a desk band technically speaking), usually docked to the Windows taskbar. AdSense Watch displays your current "Google AdSense for content" report - Page impressions, Clicks, Page CTR, Page eCPM and Earnings. The data is updated automatically or on demand. More info on AdSense Watch Toolbar usage can be found at the XML Lab site. AdSense Watch is a Windows Explorer toolbar (a desk band technically speaking), usually docked to the Windows taskbar. AdSense Watch displays your current "Google AdSense for content" report - Page impressions, Clicks, Page CTR, Page eCPM and Earnings. The data is updated automatically or on demand. More info on AdSense Watch Toolbar usage can be found at the XML Lab site.
Latest AdSense Watch installation is available at the XML Lab Downloads page. The latest version is currently 1.0b and as any other beta software AdSense Watch is currently free (but not open-source). AdSense Watch is written in C++ in Visual Studio 2005. AdSense Watch was tested on Windows 2000, Windows XP Pro and Windows Server 2003. Any suggestions, bug reports and comments are welcome at the AdSense Watch Toolbar forum. Sorry in advance to Allen G Holman that AdSense Watch looks similar to his great AdSense Notifier. Basic things usually similar in any environment... I wasn't aware of Google AdSense API (and I'm still unaware of what it provides) and so implemented AdSense login basically using screenscraping technique. I tried to make login code as robust as possible and I think I succeeded in that, at least AdSense Watch survived latest changes in Google AdSense login procedure AdSense Notifier stumbled upon. As for report data - AdSense Watch is using CSV data for reliability. Btw, AdSense Watch Toolbar is Windows Explorer Desk Band, but from implementation perspective it's not much different from Internet Explorer toolbar, so with minimal changes (mostly WRT registering) I actually can make AdSense Watch IE toolbar version. I want to investigate Google AdSense API possibilities and add more features in the next version if there will be any interest in this tool. Anyway, download AdSense Watch Toolbar for free and enjoy. Any comments are welcome!
XML processing is changing. In Java SAX slowly but steadily goes away or at least goes into low level and nowadays Java with StAX is not so different from .NET XmlReader. I found it pretty interesting to compare approaches to streaming filtering XML in Java and .NET. Filtering is a very useful technique for transforming XML on the fly, while XML is being read. Filtering out parts or branches application isn't interested to process is a great way to simplify XML reading code, which is especially important in streaming XML processing which usually tends to be more complicated than in-memory based (XML DOM) processing.
Let's say we have this dummy XML and we want to extract "interesting data" out of it.
<root>
<ignoreme>junk</ignoreme>
<data>interesting data</data>
</root>
StAX API has a dedicated built-in facility for filtering - StreamFilter/ EventFilter (as it happens in Java world StAX is a bit overengineered and contains actually two APIs - iterator-style and cursor-based one). Here is how it looks in Java with wonderful StAX:
XMLInputFactory xif = XMLInputFactory.newInstance();
XMLStreamReader reader = xif.createXMLStreamReader(
new StreamSource("foo.xml"));
reader = xif.createFilteredReader(reader, new StreamFilter() {
private int ignoreDepth = 0;
public boolean accept(XMLStreamReader reader) {
if (reader.isStartElement()
&& reader.getLocalName().equals("ignoreme")) {
ignoreDepth++;
return false;
} else if (reader.isEndElement()
&& reader.getLocalName().equals("ignoreme")) {
ignoreDepth--;
return false;
}
return (ignoreDepth == 0);
}
});
// move to <root>
moveToNextTag(reader);
// move to <data>
moveToNextTag(reader);
// read data
System.out.println(reader.getElementText());
reader.close();
Where moveToNextTag() is an utility method doing what its name says:
do {
reader.next();
} while (!reader.isStartElement() && !reader.isEndElement());
XmlStreamReader actually provides method nextTag(), but weirdly enough it can't skip text (even text filtered out by an underlying filter!) and throws an exception.
Now .NET code. Unlike StAX, .NET doesn't provide any facility for XML filtering so usual approach is to implement filter as a full-blown custom XmlReader and then chain it to another XmlReader instance. As I said before implementing custom XmlReader even .NET 2.0 still sucks (holy cow - 26 abstract methods or deriving from legacy nonconormant XmlTextReader). So I'm going to use XmlWrappingReader helper I was recommending to use:
public class Test
{
private class XmlFilter : XmlWrappingReader
{
public XmlFilter(string uri)
: base(XmlReader.Create(uri)) { }
public override bool Read()
{
bool baseRead = base.Read();
if (NodeType == XmlNodeType.Element &&
LocalName == "ignoreme")
{
Skip();
return base.Read();
}
return baseRead;
}
}
static void Main(string[] args)
{
XmlFilter filter = new XmlFilter("../../foo.xml");
XmlReader r = XmlReader.Create(filter, null);
//move to <root>
r.MoveToContent();
//Move to <data>
MoveToNextTag(r);
Console.WriteLine(r.ReadString());
}
private static void MoveToNextTag(XmlReader r)
{
do
{
r.Read();
} while (!(r.NodeType == XmlNodeType.Element) &&
!(r.NodeType == XmlNodeType.EndElement));
}
}
Amazingly similar but not so cool because of lack of anonymous classes in .NET 2.0 (expected in .NET 3.0).
In short - what I like in Java version - built-in support for XML filtering, anonymous classes. What I don't like in Java version: filter can be called more than one time on the same position, what means that real filter implementation must support such scenario; very ascetic API, too few utility methods.
What I like in .NET version: lots of useful methods in XmlReader such as Skip(), ReadToXXX() etc. What I don't like - no built-in support for filters, no anonymous methods.
Besides - if you work with StAX you can readily work with .NET XmlReader and the other way. Great unification saves hours learning for developers. I wonder if streaming XML processing API should be standardized?
Microsoft, BEA, IBM, Cisco, Intel , HP etc mix XML Schema, Schematron and XPointer to create a draft of
the Service Modeling Language (SML) used to model complex IT services and systems, including their structure, constraints, policies, and best practices.
A model in SML is realized as a set of interrelated XML documents. The XML documents contain information about the parts of an IT service, as well as the constraints that each part must satisfy for the IT service to function properly. Constraints are captured in two ways:
1. Schemas - these are constraints on the structure and content of the documents in a model. SML uses a profile of XML Schema 1.0 [2,3] as the schema language. SML also defines a set of extensions to XML Schema to support inter-document references.
2. Rules - are Boolean expressions that constrain the structure and content of documents in a model. SML uses a profile of Schematron [4,5,6] and XPath 1.0 [9] for rules.
Once a model is defined, one of the important operations on the model is to establish its validity. This involves checking whether all data in a model satisfies the schemas and rules declared.
This specification focuses primarily on defining the profile of XML Schema and Schematron used by SML, as well as the process of model validation.
Sort of XML Schema without some crappy features enhanced with Schemtron rules and XPointer based partial inclusions. Sounds cool not only in the domain of the service modeling. I wish I could use it for plain XML validation.
[Via Don Box]
Anton Lapounov is blogging! He's one of the brilliant guys responsible for XSLT in the Microsoft XML Team. If you are subscribed to my blog, you want to subscibe to "Anton Lapounov: XML XSLT and Beyond" blog too.
Just in case if somebody have missed this cool new tool - check out DonXML's into into XPathmania. It's free open-source Visual Studio add-in for XPath development. I just can't live without it already. Very cool stuff, part of our Mvp.Xml project.
Microsoft finally released MSXML6 (aka Microsoft Core XML Services) SDK. I've been told it was expected back in December. Anyway, it's ready. Now it would be nice if Microsoft updated MSXSL utility to support MSXML6 (I know it was also ready back in December too).
I've been reading some Lebanese blogs trying to understand what people from the other side of the bleeding border think. And I realized how weird country Lebanon is. Where in the world a government would strongly refuse to control a half of its own country? It's like the whole world is asking the Lebanese government - come on, you guys are the Lebanon government, please, please, take control over south Lebanon, that's your land. No, no, no, never ever said the freaking government - there is a bunch of bad guys over there, terrorists you know they can bite so we better don't. Oooooookay. Now they badly surprised it hurts to host bad guys, hmmm.
Yes, I found out that almost every single Lebanese blog I spotted says something like "That f#cking Hezbollah terrorists! That's all their fault! Hezbollah != Lebanon, we have nothing to do with this war, we are just suffering here". That even made sense for a moment, but then - who are those bad Hezbollah guys? As it turned out they are not martians not even iranians, but ordinar lebanese people, moreover Hezbollah (being widely recognized as a terrorists group) is representing the largest Lebanon's religious group, it's a recognized political party holding 23 seats in the 128-member Lebanese Parliament and participating in Lebanese government. So, again - "Hezbollah != Lebanon"? Oh come on, that's ridiculous. Hezbollah == Lebanon, face it.
I think in fact there is no one single country of Lebanon. I have no idea how such different groups can live in the same state. Those normal lebanese people whose blogs I read - you should do something about this, guys. Otherwise don't be surprised to be paying painfully for what your evil brothers do.
How would you validate XSLT output on the fly without caching transformation result as a whole? That's easy - just use MvpXslTransform class that adds to the XslCompiledTransform class ability to transform into XmlReader and wrap that reader witth a validating reader. As a result - streaming validation, no memory hogging and ability to abort transformation at first validation error. Simple sample below.
XPathDocument doc =
new XPathDocument("source.xml");
MvpXslTransform xslt = new MvpXslTransform();
xslt.Load("XSLTFile1.xslt");
XmlReader resultReader =
xslt.Transform(new XmlInput(doc), null);
XmlReaderSettings settings = new XmlReaderSettings();
settings.ValidationType = ValidationType.Schema;
settings.Schemas.Add("", "orders.xsd");
XmlReader validatingReader =
XmlReader.Create(resultReader, settings);
XmlWriter w = XmlWriter.Create(Console.Out);
w.WriteNode(validatingReader, false);
w.Close();
You can get MvpXslTransform class with Mvp.Xml library v2.0 at the Mvp.Xml project site.
ScriptAculoUs autocomplete web control from SimoneB is a nice lightweight easy to use ASP.NET autocomplete textbox control with many virtues. The only problem I had with it was that dropdown autocomplete list has no scrolling and so long autocomplete lists look ugly. Happily it comes with sources so I hacked it to add scrolling, here is the solution in case somebody needs it.
- In Suggestion.cs add a CSS class to the UL tag generated for an autocomplete list:
StringBuilder returnValue = new StringBuilder("<ul class=\"autocomplete\">");
- In a stylesheet constrain autocomplete list height and enable scrolling on overflow:
UL.autocomplete
{
height: 10em;
overflow:auto;
}
- In controls.js, modify "render" function to make autocomplete list automatically scrolling so a selected item is always visible:
render: function() {
if(this.entryCount > 0) {
for (var i = 0; i < this.entryCount; i++) {
this.index==i ?
Element.addClassName(this.getEntry(i),"selected") :
Element.removeClassName(this.getEntry(i),"selected");
if (this.index == i) {
var element = this.getEntry(i);
element.scrollIntoView(false);
}
}
if(this.hasFocus) {
this.show();
this.active = true;
}
} else {
this.active = false;
this.hide();
}
},
That does it. Works fine in both IE and FF.
This is old news, but I somehow missed it so I'll post for news-challenged like me. Microsoft has released "Shared Source Common Language Infrastructure 2.0" aka Rotor 2.0 - buildable source codes of the ECMA CLI and the ECMA C#. This is roughly .NET 2.0 sources with original comments. Priceless! It's released under "MICROSOFT SHARED SOURCE CLI, C#, AND JSCRIPT LICENSE".
New in this release:
- Full support for Generics.
- New C# 2.0 features like Anonymous Methods, Anonymous Delegates and Generics
- BCL additions.
- Lightweight Code Generation (LCG).
- Stub-based dispatch. (What the hell is that?)
- Numerous bug fixes.
There is always the Reflector, but Rotor is different - you build it, debug with it, learn and extend CLI. Now what do I want to play with? Editable XPathDocument or XSLT2DLL compiler or extendable XmlReader factory may be...
And going on with Word as XSL-FO editor theme - take a look at a brand new tool called foActive <X>Styler:
foActive <X>Styler is a plug-in for Microsoft Word 2003 Professional which allows a user to design and test dynamic document templates right from within the Word authoring environment.
<X>Styler is used to create XSL templates for server-based transformation for high-volume dynamic document print applications such as direct mail, correspondence, invoicing, statements, contracts, and legal forms.
And more:
Writing XSL templates that generate XSL FO output can be a difficult task, one suited for an engineer and not a marketing person. What the industry needed was an easy-to-use tool for designing templates to convert XML to XSL FO using XSL. There are applications that have recently emerged to do just this, however these are standalone applications designed from the ground-up for just this purpose. As such, they can be unnecessarily complex and require specific custom training to master. They expose all the functionality and complexities of XSL to the end-user.
And so foActive designed <X>Styler, merging the most common desktop application in use -- Microsoft Word -- with the difficult to master XSL design. We coupled the whole system to the industry's best XSL FO engine -- RenderX -- to deliver a complete solution for a wide variety of XSL design tasks.
That's what I was talking about all the way.
The price is set at $199, beta program is open. Sounds really cool.
 jCatalog Software AG has releaed XSLfast 3.0 - XSL-FO WYSIWYG editor. What's new in version 3.0. In general XSL-FO doesn't meant to be authored, the idea is that XSL-FO is generated using XSLT. Unfortunately that requires knowledge of XSL-FO twisted vocabulary and, well, XSLT. I always knew WYSIWYG editor could save XSL-FO and XSLfast might be that one. If only the price wasn't freaking 890,00 EUR per license. And that probably doesn't include XSL-FO formatter itself! jCatalog Software AG has releaed XSLfast 3.0 - XSL-FO WYSIWYG editor. What's new in version 3.0. In general XSL-FO doesn't meant to be authored, the idea is that XSL-FO is generated using XSLT. Unfortunately that requires knowledge of XSL-FO twisted vocabulary and, well, XSLT. I always knew WYSIWYG editor could save XSL-FO and XSLfast might be that one. If only the price wasn't freaking 890,00 EUR per license. And that probably doesn't include XSL-FO formatter itself!
Btw, after years and years Apache FOP Team's finally discussing 1.0 release...
And you thought XML is done? No way. It's alive and kicking technology. And here is just one more proof: yet another new XML API from Microsoft - the XmlLite. It's a native library for building high-performance secure XML-based applications. XmlLite library is a small one by design - it only includes pull XML parser (native analog of the .NET's XmlReader), XML writer (native analog of the .NET's XmlWriter) and XML resolver (similar to the .NET's XmlResolver). XmlLite's meant to be small, simple, secure, standards-compliant but damn fast library to read and write XML. It's claimed to be able to parse XML even faster than MSXML. What I found especially compelling is XmlLite API similarity with .NET - no need to learn yet another way to read and write XML, it's a lite version of the .NET's XmlReader/XmlWriter, but for native programming. It's a "lite", so: no validation, very limited DTD processing (entity expansion and defaults for attributes only), no ActiveX, no scripting languages, not thread-safe etc.
Bruce Eckel doesn't like XML. But alas - it's everywhere and he has to deal with it. So as you can expect, he goes and creates "general purpose XML manipulation library called xmlnode." for Python. That should be easy, right? Just one class, no need for more. Alas, it doesn't support namespaces, mixed content, CDATA sections, comments, processing instructions, DTD, Doctype, doesn't check well-formedness rules such as element and attribute names or allowed in XML characters etc. Well, that must be version 0.0...
W3C has released fresh versions of the Candidate Recommendations of XML Query 1.0, XSLT 2.0, XPath 2.0 and supporting documents. No big deal changes - xdt:* types has been moved to xs:* namespace (damn XML Schema). See new XQuery1/XPath2 type system below. Looks like XSLT2/XPath2/XQuery1 are moving fast toward Proposed Recommendation. What's weird is that new documents all say
"This specification will remain a Candidate Recommendation until at least 28 February 2006." Must be a mistake. Anyway, what are now chances for XSLT 2.0 in the .NET? Next major .NET release (Orcas) is expected October 2007 or so (forget newly announced .NET 3.0, which is actually .NET 2.0 + Avalon + Indigo). Plenty of time for XSLT2 to reach Recommendation status, even provided that Microsoft actually freezes codebase 6 months before shipping.
 Hmmm, community-driven MSDN documentation... tempting. Hmmm, community-driven MSDN documentation... tempting.
Microsoft has launched the MSDN Wiki Beta - sort of a wrapper around MSDN documentation site, which adds "Community Content section" to the bottom of each MSDN page. Anybody can contribute any content to that section. Here is my test contribution to the "XslCompiledTransform Class" page. Basically such community-driven documentation could be awesome. MSDN documentation is huge and usually the subject you desperately need happens to be covered scarcely or even in a cryptic way. Microsoft admits they are just unable to cover all topics. Sadly but fact. So at least they can provide a centralized way for the community to contribute. One big question though is community content quality - somebody have to moderte all that stuff otherwise it's gonna be filled with spam and lame questions in just a week.
I was querying one remote and probably distributed database recently. I entered my name, sent query request and got "No such record" response - four freaking months later! What kind of crazy database is it? That's Russia's police database. I requested a police certificate from russian embassy in Israel and it took them four months to query that information. Wow. No doubts they are still using legacy database called "a huge pile of paper files" out there in Russia. As a matter of interest the same query in Ukraine takes 1 day, while in Israel - 5 minutes (mostly to print results).
 I had a voucher for a free Microsoft certification exam which I got at the MVP summit last year and it was due to expire May 31. So I went to see how can I use it. As you probably know Microsoft has launched new wave of certifications with .NET 2.0 and Visiual Studio 2005 release. So I found out that "Microsoft Certified Professional Developer" series is now my target in this game. I'm MCAD already and in order to upgrade to MCPD I have to take 3 upgrade exams (there is no single MCPD credentials, it's MCPD Web, MCPD Windows and MCPD Enterprise). The problem is that those upgrade exams aren't released yet. Happily I managed not to waste my expiring voucher though. MCPD Windows requires 3 exams and two of them I've already passed in beta form, which actually counts. So last week I took 70-526 exam, "TS: Microsoft .NET Framework 2.0 - Windows-Based Client Development". I don't write much for Windows these days so it wasn't piece of cake. But not a rocket engineering either. I should admit new exams are much more comprehensive and tough. Well, anyway I'm MCPD Windows now.
I had a voucher for a free Microsoft certification exam which I got at the MVP summit last year and it was due to expire May 31. So I went to see how can I use it. As you probably know Microsoft has launched new wave of certifications with .NET 2.0 and Visiual Studio 2005 release. So I found out that "Microsoft Certified Professional Developer" series is now my target in this game. I'm MCAD already and in order to upgrade to MCPD I have to take 3 upgrade exams (there is no single MCPD credentials, it's MCPD Web, MCPD Windows and MCPD Enterprise). The problem is that those upgrade exams aren't released yet. Happily I managed not to waste my expiring voucher though. MCPD Windows requires 3 exams and two of them I've already passed in beta form, which actually counts. So last week I took 70-526 exam, "TS: Microsoft .NET Framework 2.0 - Windows-Based Client Development". I don't write much for Windows these days so it wasn't piece of cake. But not a rocket engineering either. I should admit new exams are much more comprehensive and tough. Well, anyway I'm MCPD Windows now.
This is second part of the post. Find first part here.
So what is a better way of creating custom XmlReader/XmlWriter in .NET 2.0? Here is the idea - have an utility wrapper class, which wraps XmlReader/XmlWriter and does nothing else. Then derive from this class and override methods you are interested in. These utility wrappers are called XmlWrapingReader and XmlWrapingWriter. They are part of System.Xml namespace, but unfortunately they are internal ones - Microsoft XML team has considered making them public, but in the Whidbey release rush decided to postpone this issue. Ok, happily these classes being pure wrappers have no logic whatsoever so anybody who needs them can indeed create them in a 10 minutes. But to save you that 10 minutes I post these wrappers here. I will include XmlWrapingReader and XmlWrapingWriter into the next Mvp.Xml library release.
When developing custom XmlReader or XmlWriter in .NET 2.0 there is at least three options:
- implement XmlReader/XmlWriter
- extend one of concrete XmlReader/XmlWriter implementations and override only methods you need
- implement XmlReader/XmlWriter by wrapping one of concrete XmlReader/XmlWriter implementations and overriding only methods you need
From .NET 1.X experience Microsoft seems finally figured out that providing a set of concrete poorly composable XmlReader and XmlWriter implementations (XmlTextReader, XmlTextWriter, XmlValidatingReader, XmlNodeReader) and emphasizing on programming with concrete classes instead of anstract XmlReader/Xmlwriter was really bad idea. One notorious horrible sample was XmlValidatingReader accepting abstract XmlReader instance and downcasting it silently to XmlTextReader inside. In .NET 2.0 Microsoft (with a huge diffidence) is trying to bring some order to that mess:
- XmlReader and XmlWriter now follow factory method design pattern by providing static Create() method which is now recommended way of creating XmlReader and XmlWriter instances.
- While not being marked as obsolete or deprecated or not recommended, concrete implementations like XmlTextReader and XmlTextWriter are now just wrappers for internal classes used to implement Create() factory method.
- I was said that Microsoft will be "moving away from the XmlTextReader and XmlValidating reader" and "emphasize programming directly to the XmlReader and will provide an implementation of the factory design patterns which returns different XmlReader instances based on which features the user is interested.".
 I've uploaded HTML versions of the XLinq Overview, XLinq Overview Diff (Sep 2005/May 2006) and XLinq SDK Reference to the XLinq.net portal. I don't fee it's right that I have to install heavy preview-quality package into my system just to be able to read these stuff. Or may be I just used to MSDN online. Diff is also cool for lazy/busy devs like me. Anyway. Btw, XLinq Overview link at the LINQ Project homepage points to the old September 2005 version. I've uploaded HTML versions of the XLinq Overview, XLinq Overview Diff (Sep 2005/May 2006) and XLinq SDK Reference to the XLinq.net portal. I don't fee it's right that I have to install heavy preview-quality package into my system just to be able to read these stuff. Or may be I just used to MSDN online. Diff is also cool for lazy/busy devs like me. Anyway. Btw, XLinq Overview link at the LINQ Project homepage points to the old September 2005 version.
Via Brian Jones we learn that the Ecma International Technical Committee (TC45) has published draft version 1.3 of the Ecma Office Open XML File Formats Standard. This is 4000 pages document specifying new (alternative to Oasis OpenOffice/OpenDocument XML format) Office XML format to be used by Microsoft starting with Office 2007.
As a matter of interest:
- The draft is available in PDF, which was created by Word 2007
- The draft also available in Open XML format itself, which one will be use once Office 2007 Beta 2 is out
- The document is huge and specifies everything down to the "Maple Muffins" border style kinda details
- These guys help MIcrosoft in creating Ecma Office Open XML format: Apple, Barclays Capital, BP, The British Library, Essilor, Intel, Microsoft, NextPage, Novell, Statoil, and Toshiba
Microsoft has launched CodePlex Beta - kinda revamped GotDotNet, based on Team Foundation Server:
CodePlex is an online software development environment for open and shared source developers to create, host and manage projects throughout the project lifecycle. It has been written from the ground up in C# using .NET 2.0 technology with Team Foundation Server on the back end. CodePlex is open to the public free of charge.
CodePlex includes the following features:
* Release Management
* Work Item Tracking
* Source Code Dissemination
* Wiki-based Project Team Communications
* Project Forums
* News Feed Aggregation
My experience with GotDotNet was a nasty one and I don't expect its successor to bring SourceForge quality any soon, but anyway CodePlex looks interesting and promising. It already hosts several interesting projects including CodePlex itself, "Atlas" Control Toolkit, Commerce Starter Kit, IronPython etc.
I'm sure my next open-source .NET related project will be hosted at the CodePlex.
LINQ May 2006 CTP installs C# 3.0 compiler and new C# language service into Visual Studio 2005. New syntax, keywords, Intellisense for extension methods and all that jazz.
This essensially disables native C# 2.0 compiler and C# language service. If you installed LINQ on Virtual PC - big deal. But if not and you want to switch C# back to 2.0 - there is a solution. Folder bin contains two little scripts called "Install C# IDE Support.vbs" and "Uninstall C# IDE Support.vbs". Just run latter one and your native C# 2.0 is back. Somehow there are only scripts for C#.
I really enjoy seeing Michael Kay talking about working with XML in .NET. That makes me feel I might be not a freak after all.
According to Paul Vick VB9 LINQ query syntax will be switched from SQL-like "Select/From" to "From/Select" (Paul calls it "Yoda style" :) used by C# since the begining of LINQ. While for VB it's quite natural to follow SQL syntax (so not troubling poor busy VB developers), working Intellisense is more important. Anyway, I like it.
The changes should be in the next LINQ CTP, which is expected ... (wink wink) really really soon!
Here is one easy way:
- Go to xmllab.net, get free eXml Web server control and modified Microsoft's WordML2HTML XSLT stylesheet, version 1.3.
- Drop eXml control onto a Web form, assign DocumentSource property (WordML document you want to render), TransformSource property(wordml2html-.NET-script.xslt):
<xmllab:eXml ID="EXml1" runat="server"
DocumentSource="~/TestDocument.xml"
TransformSource="~/wordml2html-.NET-script.xslt"/>
- Create new folder to store external images
- In code behind allow XSLT scripting and pass couple XSLT parameters - real path to above image directory and its virtual name:
protected void Page_Load(object sender, EventArgs e)
{
EXml1.XsltSettings = System.Xml.Xsl.XsltSettings.TrustedXslt;
EXml1.TransformArgumentList =
new System.Xml.Xsl.XsltArgumentList();
EXml1.TransformArgumentList.AddParam(
"base-dir-for-images", "", MapPathSecure("~/images"));
EXml1.TransformArgumentList.AddParam(
"base-virtual-dir-for-images", "", "images");
}
Done.
I had to add these two parameters so the WordML2HTML stylesheet could export images there and then refer to exported images in HTML. If you don't pass these parameters images will be exported into current directory - while that's ok when running WordML2HTML transformation in a command line, that's bad idea for ASP.NET environment.
Enjoy!
Martin Szugat, .NET and XML expert from Germany has published an article about using my eXml Web server control in ASP.NET 2.0. The article was published in the German
dot.net magazin and now it also went online in the German MSDN: "Von der Quelle zum Kunden. Anzeige von XML-Daten auf dem Client in ASP.NET 2.0". Yep, German only, no English translation yet afaik. Well, cool anyway.
XslCompiledTransform provides amazing transformation performance, but obviously not without a price. As with any compiling system the price is slower and quite resource consuming compilation stage. That's why it's very important to cache loaded XslCompiledTransform instance to avoid paying compilation price over again. One question that comes sometimes while implementing caching/pooling systems for XslCompiledTransform is how to check if XslCompiledTransform instance has been already loaded with a stylesheet?
XslCompiledTransform design separates object construction and initialization for the sake of reusability (to be able to load another XSLT stylesheet into the same XslCompiledTransform instance). I believe that's a legacy issue as it contradicts with always-cache-loaded-XslCompiledTransform mantra. And unfortunately currently XslCompiledTransform provides no property to check if the stylesheet was already loaded and XslCompiledTransform instance is ready to be used. Hopefully in the next version we will get such one. But currently here is a trick that can be used - check OutputSettings property for not null. It's always null when Load() method has not been called and always not null after that. This is pretty much safe and I was assured by guys at the Microsoft XML team responsible for the XslCompiledTransform that this behaviour won't be changed.
Yeah, my first ASP.NET 2.0 site went into production. It's a site hosted by the Israel Football Association for football referees so they can fill in game reports while relaxing at home. PowerBuilder backend - turned out to be not as bad as it could be (btw, if anyone ever want to interop with PowerBuilder from .NET via COM - never ever use OLE DB in PB code). No public access, so no URL, sorry. But what I wanted to say is that ASP.NET 2.0 and Visual Studio 2005 rock! It was just a plain coding pleasure.
Well, "XSLT 2.0 in .NET" survey at the XML Lab site has ended back in January and I forgot to select a winner. Ooops. Let's finish this now.
I obviously made a mistake requiring user registration for voting, but then I needed some way to identify a winner... Anyway, 40 people registered and voted (thanks guys), which is not bad for such a small unknown site. 72% need XSLT 2.0, 25% think it would be nice to have, 2% happy with XSLT 1.0. Quite predictable given my audience.
And the winner (choosen truly randomly using EXSLT random:random-sequence() function) is Yoeri Van de Moortel from Belgium. Congratulations, Yoeri! Get in touch with me, I need your address to send the "XSLT 2.0 Programmer's Reference" book by Mike Kay (or some other XSLT book if you happens to own this one already).
Hey, I'm a moderator on MSDN Forums now! Watch out you XSLT haters I'm gonna remove every post that shows no respect for XSLT :)
 Ok, I'm back. I have updated eXml Web Server Control, which uses XslCompiledTransform, supports 70+ EXSLT functions, XInclude, friendly XML rendering, <?xml-stylesheet?>, embedded stylesheets etc. Ok, I'm back. I have updated eXml Web Server Control, which uses XslCompiledTransform, supports 70+ EXSLT functions, XInclude, friendly XML rendering, <?xml-stylesheet?>, embedded stylesheets etc.
Martin Szugat found some bugs and kindly provided patches, thanks Martin! Additionally I implemented one small but useful feature users kept asking for - cache dependencies for imported/included stylesheets. That's when you have included or imported stylesheet and modify it - now eXml control notices it and recompiles XSLT on the next request. Go get eXml Web server control v1.1. Now I think about eXmlDataSource control... Free asp:XmlDataSource analog running XslCompiledTransform, supporting EXSLT, XInclude, <?xml-stylesheet?> and embedded stylesheets - it sounds useful, isn't it?
This is a book called "Working with Microsoft Visual Studio 2005" by Marc Young, Brian Johnson and Craig Skibo, which is an update of their "Inside Microsoft Visual Studio .NET 2003" book. Really great book explaining Visual Studio 2005 internals and ways to extend it. But you can't buy it. Weird huh? Instead you can download it as a benefit when registering your copy of Visual Studio 2005. Go to Help/Register Product menu item and once you done you should get an email with links how to download the book (along with bunch of other cool stuff like free icon collection) from the Visual Studio Benefit Portal.
Another alternative to purchasing a hexadecimal calculator is to obtain a TSR (Terminate
and Stay Resident) program such as SideKick which contains a built-in calculator.
However, unless you already have one of these programs, or you need some of the other
features they offer, such programs are not a particularly good value since they cost more
than an actual calculator and are not as convenient to use.
This is from " The Art of Assembly Language" book by Randy Hyde. Looks like software industry made some progress since then.
 "XSLT 2.0 in .NET" survey at the XML Lab site ends in a week. "XSLT 2.0 in .NET" survey at the XML Lab site ends in a week.
Vote now and get a chance to win the "XSLT 2.0" book by Mike Kay!
When the survey ends one lucky survey taker from whatever part of the world choosen randomly will get the book.
Note: you have to be registered on the Xml Lab site to vote. Sorry, but I need some simple way to identify the winner. Registration is simple and public - no email verification or something like, just fill in your name, password and email and then vote.
Now that XslCompiledTransform in .NET 2.0 supports exsl:object-type() extension function I think a little intro is needed as this is really new function for Microsoft-oriented XSLT developers.
 I've got an invitation to participate in Yahoo! Publisher Network Beta program, which seems to be another targeted ad system just like Google AdSense, but already supporting ads in RSS feeds. They support MovableType and WordPress. Alas I couldn't even login - it's currently USA only and USA tax information is required to setup an account. Why it has to be so lame? I've got an invitation to participate in Yahoo! Publisher Network Beta program, which seems to be another targeted ad system just like Google AdSense, but already supporting ads in RSS feeds. They support MovableType and WordPress. Alas I couldn't even login - it's currently USA only and USA tax information is required to setup an account. Why it has to be so lame?
Creators of the XQDoc, a free tool for documenting XQuery modules have released XQuery Style Conventions. They claim the document to be to be based on experience and feedback from the
XQuery development community. It does seem ok to me. In a perfect world every programmer would follow style conventions of course. But we live in another kind of world...
 As many other Microsoft MVPs I've been given 3 "Visual Studio 2005 Team Suite with MSDN Premium Subscriptions" redemption cards to share. So now I'm having hard time looking for smart ideas how to do so. One card I would give to Kevin Downs, the guy who runs NDoc if he still has no MSDN subscription, but for the rest two I probably would go the way my fellow MVPs went and arrange some sort of contest. XML contest, of course, hmmm. Ummm, any ideas, anyone? As many other Microsoft MVPs I've been given 3 "Visual Studio 2005 Team Suite with MSDN Premium Subscriptions" redemption cards to share. So now I'm having hard time looking for smart ideas how to do so. One card I would give to Kevin Downs, the guy who runs NDoc if he still has no MSDN subscription, but for the rest two I probably would go the way my fellow MVPs went and arrange some sort of contest. XML contest, of course, hmmm. Ummm, any ideas, anyone?
My wife's been chasing grasshoppers this fall:
Sometimes it's useful to detect which XSLT engine your XSLT stylersheet is being executed by, e.g. to shortcut processing using an engine-specific extension function or to workaround a bug in particlular engine. Now that Microsoft alone ships 3 different XSLT engines - MSXML3/MSXML4/MSXML5/MSXML6, XslTransform and XslCompiledTransform, detecting XSLT engine from within XSLT stylesheet may be vital requirement. Here is how it can be done.
There are two new killer but undocumented features in Microsoft .NET 2.0 pertaining to EXSLT. Anybody like me regularly digging in System.Xml assembly probably knows it, but general audience is still unaware. So I want to share these secrets.
You say you know XSLT well? Try answer this quiz of XSLT 1.0 oddities by James Fuller.
This guy Matt Cassell is 15 years old and now he's got C# MVP award. Boy, I feel like a dinosaur now...
Almost 2 years ago I published a post "Transforming WordML to HTML: Support for Images" showing how to hack Microsoft WordML2HTML stylesheet to support images. People kept telling me it doesn't support some weird image formats or header images. Moreover I realized it has a bug and didn't work with .NET 2.0. So finally I updated that damn stylesheet. Now I took another Microsoft WordML2HTML stylesheet as a base - that one that comes with Word 2003 XML Viewer tool. I think it's a better one. Anyway, I added to it a couple of templates so images now get decoded and saved externally and headers and footers are processed too (only header/footer for odd pages per section to be precise).
Note: this stylesheet uses embedded C# script to decode images and so only works with .NET XSLT processors, such as XslTransform (.NET 1.1) or XslCompiledTransform (.NET 2.0). You can also run it with nxslt/nxslt2 command line tool. Here is a small demo.
I've never tried working with natural keyboards. Somehow I thought they are kinda unnatural :) Now I want to give it a try, may be this new Microsoft Natural Ergonomic Keyboard 4000:

Seems like people love it. It's great to see the latest Microsoft keyboard with standard 2x3 home/end key location set. Damn F Lock button is turned on on reboot, but happily little registry hack by Jason Tsang can fix it.
The only thing I dislike about model 4000 is that nasty cord. It's not wireless! And I hate cords on my desk. Anybody knows if Microsoft plans to release wireless version?
Happy New Year everyone, I hope you are not sick and depressive as I am. But I'm slowly recovering...
 Good news in the mailbox yesterday - I got Microsoft MVP Award again, third year in a row, 2004, 2005 and now 2006. In the "Windows Server System - XML" category. Well, thanks! That's cool to be Microsoft MVP btw. You own nothing to Microsoft (well, except NDA) and get private access to internal information and people as well as nice benefits. And all it takes - helping people, which is nice on its own. Good news in the mailbox yesterday - I got Microsoft MVP Award again, third year in a row, 2004, 2005 and now 2006. In the "Windows Server System - XML" category. Well, thanks! That's cool to be Microsoft MVP btw. You own nothing to Microsoft (well, except NDA) and get private access to internal information and people as well as nice benefits. And all it takes - helping people, which is nice on its own.
|
|

 I just uploaded
I just uploaded 





{kind=link}
{kind=link}
Recent Comments