
Muenchian technique of grouping is de-facto standard way of grouping in XSLT 1.0. It uses keys and is usually very fast, efficient and scalable. There used to be some problems with using Muenchian grouping in .NET though, in particular the speed was in question. To put it another way - .NET implementation of keys and generate-id() function is slow. Reportedly, as per KB article 324478, keys performance has been fixed, though I have no idea if the fix is within .NET 1.1 SP1 (.NET version 1.1.4322.2032). Anyway, writing the article on XML indexing I did some perf testing for XSLT keys and got interesting results I want to share.
Muenchian grouping includes a step of selecting unique nodes - first node for each group. Usually this is done using generate-id() or count() functions. There is another way to select nodes with unique value though - EXSLT's set:distinct() function, supported by EXSLT.NET. So I measured performance and scalability of all three methods.
The source XML is XML dump of the Orders database from the Northwind sample database, including 415 orders:
<root> <orders OrderID="10249" CustomerID="TOMSP" EmployeeID="6" OrderDate="1996-07-05T00:00:00" RequiredDate="1996-08-16T00:00:00" ShippedDate="1996-07-10T00:00:00" ShipVia="1" Freight="11.61" ShipName="Toms Spezialitten" ShipAddress="Luisenstr. 48" ShipCity="Munster" ShipPostalCode="44087" ShipCountry="Germany" /> <!-- 414 more orders --> </root>To unveil scalability issues I created bigger documents by multiplying number of orders by 2 (while keeping OrderID uniquness), so I got documents with 415, 830, 1660, 3320, 6640 and 13280 orders (from 135 Kb to 4.5 Mb). The task is to group orders by ShipCountry value. Here is the first stylesheet (classical Muenchian grouping with generate-id()):
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output indent="yes"/>
<xsl:key name="countryKey" match="orders" use="@ShipCountry"/>
<xsl:template match="root">
<table border="1">
<tr>
<th>Order ID</th>
<th>Ship City</th>
</tr>
<xsl:for-each select="
orders[generate-id()=generate-id(key('countryKey', @ShipCountry)[1])]">
<tr>
<th colspan="2">
<xsl:value-of select="@ShipCountry"/>
</th>
</tr>
<xsl:for-each select="key('countryKey',@ShipCountry)">
<tr>
<td>
<xsl:value-of select="@OrderID"/>
</td>
<td>
<xsl:value-of select="@ShipCity"/>
</td>
</tr>
</xsl:for-each>
</xsl:for-each>
</table>
</xsl:template>
</xsl:stylesheet>
Pretty trivial. Second version uses count() function instead of generate-id(), here is the relevant part:
<xsl:for-each select="
orders[count(.| key('countryKey', @ShipCountry)[1]) = 1]">
And third version uses set:distinct() function:
<xsl:for-each select="set:distinct(orders/@ShipCountry)/.." xmlns:set="http://exslt.org/sets">Here are the results I got when running all three stylesheets with above 6 XML documents on my ancient Dell workstation (P3 600MHz) using nxslt.exe:
| Grouping technique | Transformation time (ms) | |||||
|---|---|---|---|---|---|---|
| XML document size (number of orders to group) | ||||||
| 415 | 830 | 1660 | 3320 | 6640 | 13280 | |
| Muenchian Grouping (with generate-id()) | 151.722 | 407.619 | 1318.676 | 5290.962 | 27773.98 | 130860.1 |
| Muenchian Grouping (with count()) | 97.238 | 190.086 | 462.075 | 1401.199 | 4193.143 | 14015.86 |
| Muenchian Grouping (with (set:distinct()) | 94.499 | 155.035 | 276.465 | 687.494 | 1104.554 | 2503.871 |
The graph view works better:
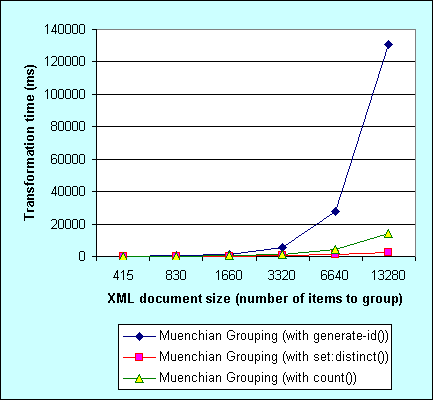
As can be seen, in .NET 1.1, Muenchian grouping using generate-id() is not only the slowest, but shows the worst scalability. Probably the reason is poor generate-id() function implementation. count() function performs much better, but still shows some scalability issues. And finally Muenchian grouping using set:distinct() function is the winner here - both in speed and good scalability. Sublinear running time, amazing. Kudos to Dimitre Novatchev for optimizing set:distinct() function implmentation in EXSLT.NET.
The bottom line - if you are looking for ways to speed up grouping in XSLT under .NET 1.X, use Muenchian grouping with set:distinct() function from EXSLT.NET to get the best perf and scalability. Otherwise use Muenchian grouping with count() function, which sucks less in .NET than generate-id() function does.
I wonder what would be results in .NET 2.0? Stay tuned guys.
eliasen, take a look at http://www.tkachenko.com/blog/archives/000638.html. In short - there is no difference in .NET 2.0. All three work the same.
Have you done your performance tests on .NET 2.0 yet? Which is to be preferred now?
Thanks in advance!
--
eliasen
I cannot expect all people to move to Net 2. immediately, so 1.1 XSLT will be used for long time. Namespace manager is fast and efficiant, I created some tests. If you use namespaces with single char it is much faster, so considering it uses NameTable it is strage. Then see memory usage. Even not used namespaces (just declared) add much memory. The dump managed memory statistics. What should people do with this? I beleive that compiled styleseets will not have this problem, but there must be some way to avoid this. If you take your 5Mbs document and add 5 long namespaces to your stylesheet at top level, probably your app will go out of memory. This is not an not efficient implementation, it looks like a mistake in implementation. I icannot imagine how unused declared namespaces can impact memory usage so much. I had to add some normalization to generated XSLTs and I could reduce working set very significantly. In real world all groupping mehtods in .Negt may become inefficient, because of other problems.
Feb TCP which includes only XslTransform class has the same problem.
Yeah, I've noticed it too - each additional namespace declaration slows down transformation. That's probably because of inefficient implementation of the XmlNamespaceManager class.
AFAIK it's fixed in .NET 2.0 already.
Oleh, I am still trying to show people another problem, so just add several not used namespace to prefix binding on stylesheet element and compare times. I think you should notice a difference ;)