It is possible to extend the power of XSLT using JavaScript embedded into the XSL file. Therefore any web application that allows the user to upload their own XSL file will be vulnerable to Cross Site Scripting attacks.
Well, that's not exactly true, at least on Microsoft platform.
Microsoft tackled this issue long time ago. Both MSXML 6.0 and .NET (since 2.0) don't allow script extensions and document() function in XSLT by default. One has to enable them explicitly. So the truth is s bit different: any web application that allows the user to upload their own XSL file and explicitly allows executing embedded scripts will be vulnerable to Cross Site Scripting attacks.
While we at this, here is some refresher for this important to know topic:
Untrusted style sheets are those that come from an untrustworthy domain. There is no way to eliminate denial of service (DoS) attacks when processing untrusted style sheets or untrusted documents without removing necessary functionality. If denial of service is a concern, do not accept untrusted style sheets or untrusted documents for transformation.
Cross-Site Attacks
It is not safe to compile and execute an untrusted style sheet within a trusted page (such as a page from your local hard drive). The style sheet may contain the document() function or xsl:include / xsl:import statements, which are capable of loading trusted files and sending them back to the untrusted domain.
XSLT Scripts Are Prohibited by Default
The DOM supports XSLT transformations via calls to the transformNode method and transformNodeToObject method. XSLT supports scripting inside style sheets using the <msxsl:script> element. This allows custom functions to be used in an XSLT transformation. In MSXML 6.0 this feature is disabled by default. If you require scripting in your XSLT transformations, you can enable the feature by setting the AllowXsltScript Property to true.
To allow XSLT scripting (JScript):
doc.setProperty("AllowXsltScript", true);
To disallow XSLT scripting:
doc.setProperty("AllowXsltScript", false);
Internet Explorer uses MSXML 3.0 by default, so when using the MIME viewer to transform scripts, Internet Explorer's security settings are used.
However, if you use MSXML 6.0 via script in Internet Explorer to execute transformations, when the AllowXsltScript property is set to false scripting is disabled no matter what Internet Explorer's settings are. When AllowXsltScript is set to true, Internet Explorer's security settings are used for executing.
The XSLT document Function Is Disallowed by Default
The DOM supports XSLT transformations via calls to the transformNode and transformNodeToObject methods. The XSLT document function provides a way to retrieve other XML resources from within the XSLT style sheet beyond the initial data provided by the input stream. In MSXML 6.0 this feature is disabled by default. If you must use the document function in your XSLT transformations, you can enable the feature by setting the AllowDocumentFunction property to true.
The following is the JScript code to allow the document function:
doc.setProperty("AllowDocumentFunction", true);
To disallow the document function:
doc.setProperty("AllowDocumentFunction", false);
If you enable the document function, you should be aware that the document function runs with the same security settings as the style sheet. If your style sheet is running in a trusted security context, then all files loaded using the document function will run in the same security context. For example, if scripts are allowed in the main style sheet, they will be allowed in all the included and imported files. You should not load untrusted documents via the document function.
Loading External Files Is Prohibited by Default
External files loaded via xsl:include or xsl:import are allowed and processed by default in MSXML 4.0 and 5.0 for backward compatibility. In MSXML 6.0, external files are not processed by default – they must be explicitly enabled by the developer.
If you are using MSXML 6.0 and all of your XSLT style sheets and XML documents come from a secure site, you can allow external schemas by setting the resolveExternals property to true. If you are using MSXML 4.0 or 5.0 and your XSLT style sheets and XML documents do not come from a secure site, you can operate in a safer mode by setting resolveExternals to false.
The XslCompiledTransform class supports the xsl:import or xsl:include elements by default. The XslCompiledTransform class disables support for the document() function by default. The XsltSettings class is used to enable the document() function.
The Load and Transform methods include overloads that take an XmlResolver object as one of its arguments. If an XmlResolver is not specified, a default XmlUrlResolver with no credentials is used.
You can control how external resources are accessed by doing one of the following:
Restrict the resources that the XSLT process can access by using an XmlSecureResolver object.
Do not allow the XSLT process open any external resources by passing in null to the XmlResolver argument.
Script Blocks
The XslCompiledTransform class does not support script blocks by default. Script blocks are enabled using the XsltSettings class. XSLT scripting should be enabled only if you require script support and you are working in a fully trusted environment.
Extension Objects
Extension objects add programming capabilities to XSLT transformations. This feature is enabled by default. If extension objects are passed to the Transform method, they are used in the XSLT transformation.
"Debug" page in XSLT Library project properties, which has Startup stylesheet dropdown list
"Set as StartUp Stylesheet" context menu item for XSLT stylesheets
"Start Debugging(F5)/Start Without Debugging(Ctrl+F5)" commands support - runs startup stylesheet
My goal was to make F5/Ctrl+F5 working intuitively right - when you work on XSLT Library project F5 should run project with debugger and Ctrl+F5 - without. When you have more that one stylesheet it's nice time saving feature, not to mention that start debugging command finally starts debugger as it should.
But what to run? So I introduced a notion of a startup XSLT stylesheet in a project. It's kinda like startup object in C# projects, but currently only affects debugging within Visual Studio. You mark your startup stylesheet either via project properties (Debug tab):
or via new context menu item I added to XSLT stylesheets:
Once you have startup stylesheet in XSLT Library project you can start it as you usually start project with or without debugging:
I also spent unbelievable amount of time trying to make startup stylesheet bolded in Solution Explorer. It still doesn't work on project load...
This book looks like one of the best Ruby on Rails book I've seen so far. It's probably more an introductionary one, but seems pretty solid. Hey Amazon marks it as [ILLUSTRATED] book :)
Here goes nxslt3.exe/NxsltTask v3.0. It's nxslt tool for .Net 3.5. It can do everything nxslt2/NxsltTask v2.3 can plus the ability to run compiled XSLT stylesheets.
Now short documentation about running compiled XSLT stylesheets.
Let's say you have a stylesheet called mytransform.xsl. First you compile it using nxsltc:
nxsltc mytransform.xsl /out:mytransform.dll
The result is mytransform.dll, containing mytransform class.
-c option says you want to run compiled stylesheet. Instead of XSLT stylesheet file name you pass compiled stylesheet class name (fully qualified if it has a namespace). And you need to specify dll file, where compiled stylesheet can be found.
Of course if you can afford assume things you can make it shorter. If dll is named after stylesheet and can be found in the current directory, you can omit it:
nxslt3 document.xml -c mytransform
Alternatively if dll contains single compiled stylesheet you can specify dll and omit stylesheet:
nxslt3 document.xml -c -af mytransform.dll
If you happens to compile your stylesheets into a strongly named dll:
nxsltc mytransform.xsl /keyfile:d:\keys\test.snk
and then installed it into the GAC, you run it by specifying full or partial dll name after -an option:
And finally. nxslt3 is a free feature-rich .NET 3.5 XSLT command line utility and NAnt/MSBuild task which uses .NET XSLT processor - XslCompiledTransform class and supports XML Base, XInclude, XPointer, EXSLT, compiled stylesheets, embedded stylesheets, processing instruction, multioutput, custom URI resolving, custom extension functions, pretty printing, XHTML output, XSLT 2.0-like character maps and more.
nxslt3.exe/NxsltTask are free tools under BSD license. Download here.
I updated nxsltc - XSLT compiler for .NET 3.5 tool one more time. I added /version:<x.x.x.x> and /keyfile:<file> options. Former is used to specify resulting DLL version and latter - to sign it with a strong name.
D:\>nxsltc.exe /?
XSLT Compiler version 1.0beta2 for .NET 3.5
(c) 2007 Oleg Tkachenko, http://www.xmllab.net
Usage: nxsltc [options]
where possible options include:
/out: Specifies the output file name
/debug[+|-] Emit debugging information
/nowarn Disable all warnings
/namespace: Specifies namespace for compiled stylesheets
/version: Specifies assembly version
/keyfile: Specifies strong name key file
/help Display this usage message (Short form: /?)
/nologo Do not display compiler copyright banner
I also updated nxsltc.exe (well, just rebuilt it using Visual Studio 2008 Beta2).
nXSLTC is an experimental XSLT to MSIL compiler for the forthcoming .NET 3.5. nXSLTC compiles one or more XSLT stylesheets into DLL. Compiled stylesheets then can be used for transforming XML documents using XslCompiledTransform class.
What's the probability of having two car accidents in one month? It must be high enough. Just a month after the first one some asshole hit me and run away. I wonder if it's a bad luck or actually a good luck? Sure, my own car is totaled and a company car doesn't look good either, but hey, I didn't get even a scratch, so I believe I'm a lucky guy.
Ok, back to work. I uploaded version 2.3 of the nxslt2.exe/NxsltTask tool. It's probably the last version for .NET 2.0. Anyway, here is what's new:
nxslt.exe options files (@file option) - useful when your command line gets too long.
XHTML output mode (-xhtml option) - this approach in action.
XSLT 2.0-like character maps (-cm option) - just like in XSLT 2.0, but in a proprietary namespace. I have to blog about this feature.
nxslt and NxsltTask are now debuggable - as it turned out when round-tripping assemblies with ildasm/ilasm there is still a solution to keep them debuggable.
resolving XInclude for XSLT stylesheets is now off by default - because usually nobody needs it and it breaks Docbooks stylesheets.
-xslxi option to turn XInclude for XSLT stylesheets on - if you still want it.
fixed several bugs preventing running Docbook stylesheets - XslCompiledTransfrom + DTD in imported stylesheets and documents loaded via document() function + custom XmlReaders= nightmare.
Oh, just in case: nxslt2 is a free feature-rich .NET 2.0 XSLT command line utility and NAnt/MSBuild task which uses .NET 2.0 XSLT processor - XslCompiledTransform class and supports XML Base, XInclude, XPointer, EXSLT, embedded stylesheets, processing instruction, multioutput, custom URI resolving, custom extension functions, pretty printing, XHTML output, XSLT 2.0-like character maps and more.
Today, Microsoft took another step in its relationship with the open source software community. We did this by bringing up a new web property that clearly outlines Microsoft’s position on OSS by providing specific information about Microsoft, the OSS community and the interaction between the two. The new site also details information about getting started with OSS and Microsoft technologies. We'll keep the site updated with new content featuring Microsoft’s engagements with the OSS community - be that events like OSCON, partnerships, offers or just interesting articles highlighting different work we're doing across the company. Port 25 will continue to be the source for technical analysis and community with the Open Source Software Lab.
John Lam announced the very first pre-alpha drop of IronRuby - Microsoft open source (!) implementation of the Ruby language, licensed under Microsoft Permissive License. This release contains early bits of Ruby implementation for .NET based on the DLR(Dynamic Language Runtime), you actually have to build it if you want to run it. Scott Guthrie shows command line and WPF hello-world sample apps built with IronRuby.
IronRuby team takes unique (for Microsoft) approach - not only IronRuby implementation is going to be open source (IronPython is open source already), they actually plan to host it on RubyForge and accept source code contributions:
IronRuby Project Plans
Next month we will be moving the IronRuby source code repository to be hosted on RubyForge. As part of this move we are also opening up the project to enable non-Microsoft developers to enlist in the project and contribute source code. We'll then work to implement the remaining features and fix compatibility issues found as more libraries and source are ported to run on top of it.
The end result will be a compatible, fast, and flexible Ruby implementation on top of .NET that anyone can use for free.
Unbelievable. Either Microsoft don't see any money behind IronRuby or this is some kind of evil experiment.
I love Ruby and .NET. Sure I will be contributing.
I'm playing with IronRuby right now. This is cool stuff, now I want it to be fast, I want full Visual Studio support and I want it to be my primary language. Screw Java and C#, Ruby is where all fun is.
And finally another great news about Visual Studio 2008 from Scott Guthrie:
You'll see Beta2 ship later this week - so only a few more days now.
It's known that .NET XSLT engine - XslCompiledTransform natively supports two EXSLT extension functions - exsl:node-set() and exsl:object-type(). Not that it's widely known (msdn still says nothing about it), but lots of people are using this handy feature. The main benefit is that using EXSLT's version of node-set() function allows complex XSLT stylesheets (and I guess 80% of complex stylesheets can't live without xxx:node-set() function) to be portable between .NET, Java and libxslt.
Now, let's admit this fact is very little known. I've seen even advanced XSLT developers still using annoying techniques like switching "http://exslt.org/common" and "urn:schemas-microsoft-com:xslt" namespaces or awkward xsl:choose "function-available('exslt:node-set')" blocks. That's wrong.
These days you don't need any special handling for EXSLT exsl:node-set() function in your server-side oriented XSLT stylesheets. Just use it. .NET, Java and libxslt all support it.
I think (.NET and MSXML)-only msxsl:node-set() function should be avoided. Unless you are targeting browsers (in which case you need this trick).
I found it useful to insert EXSLT common namespace declaration into Visual Studio templates for XSLT files. It works as a reminder and is just handy. Here is how you can do it. Open XSLT templates for "Add new item" and "New File" commands:
C:\Program Files\Microsoft Visual Studio 8\Common7\IDE\ItemTemplatesCache\CSharp\1033\XSLTFile.zip\XSLTFile.xslt
C:\Program Files\Microsoft Visual Studio 8\Common7\IDE\ItemTemplatesCache\VisualBasic\1033\XSLTFile.zip\XSLTFile.xslt
C:\Program Files\Microsoft Visual Studio 8\Common7\IDE\NewFileItems\xsltfile.xslt
and add xmlns:exsl="http://exslt.org/common" and exclude-result-prefixes="exsl" to the xsl:stylesheet element:
I've been in a car accident a week ago. First time ever. The car is totaled, but I'm totally fine, just a couple of scratches. Happily I was alone and was driving slowly enough.
That's been interesting experience though, but not that I wish to anybody to have. Kind of "driving the very right lane, nobody ahead of me, life is perfect, music is great, BOOM!, totally new reality". As it turned out there was another car accident on the left line just a second before and one car bounced off to my line literally a meter before me. What's amazing is that no matter how hard I try I can't recall a moment when there is another car before mine. All I remember is empty line and then airbag. How come? Is it eyes or brains limitation or was I just looking somewhere else at the moment? Or may be my brain doesn't want me to remember such shocking moments? That's sort of disappointing, like been in a car accident, but haven't seen anything.
Producing XHTML using XSLT 1.0 processor is tough (no wonder - XSLT 1.0 is so old - it was published even before XHTML 1.0). While XHTML is just XML, XHTML spec defines a set of very specific formatting rules called "HTML Compatibility Guidelines". The goal is to facilitate rendering of XHTML by HTML browsers (such as Internet Explorer :).
The guidelines say for instance that elements with non-empty content model (such as <p>) must never be serialized in minimized form (<p />), while elements with empty content model (such as <br>) must never be serialized in full form (<br></br>).
While XML doesn't care about such nonsense, HTML browsers might be confused and so XHTML generation should be smart enough. And XSLT 1.0 processors can only output text, HTML or XML (XSLT 2.0 processors can also do XHTML). That's why generating XHTML using XSLT 1.0 processor is tough.
I implemented one simple solution to the problem in the Mvp.Xml library 2.3. Here is a sample that says it all:
XSLT stylesheet:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" indent="yes"
doctype-system="http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
doctype-public="-//W3C//DTD XHTML 1.0 Transitional//EN"/>
<xsl:template match="/">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title/>
</head>
<body>
<p>Para element must have end tag even if empty:</p>
<p/>
<p>These elements must not have end tags:</p>
<p>
<br></br>
<hr></hr>
<img src="foo.jpg" alt="bar"></img>
</p>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
The code:
using System;
using System.Xml.XPath;
using System.IO;
using Mvp.Xml.Common.Xsl;
class Program
{
static void Main(string[] args)
{
XPathDocument doc = new XPathDocument(
new StringReader(""));
MvpXslTransform xslt = new MvpXslTransform();
xslt.Load("../../XSLTFile1.xslt");
xslt.EnforceXHTMLOutput = true;
xslt.Transform(new XmlInput(doc), null,
new XmlOutput(Console.Out));
}
}
The result:
<?xml version="1.0" encoding="DOS-862"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title></title>
</head>
<body>
<p>Para element must have end tag even if empty:</p>
<p></p>
<p>These elements must not have end tags:</p>
<p>
<br />
<hr />
<img src="foo.jpg" alt="bar" />
</p>
</body>
</html>
If for some weird reason you don't want to use MvpXslTransform class, you can stay with XslCompiledTransform and just output via XhtmlWriter class:
using System;
using System.Xml.XPath;
using System.Xml.Xsl;
using System.Xml;
using System.IO;
using Mvp.Xml.Common;
class Program
{
static void Main(string[] args)
{
XPathDocument doc = new XPathDocument(
new StringReader(""));
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load("../../XSLTFile1.xslt");
xslt.Transform(doc, null,
new XhtmlWriter(
XmlWriter.Create(Console.Out, xslt.OutputSettings)));
}
}
Saxon, famous XSLT 2.0 and XQuery processor, supports XInclude since version 8.9. But in Java version only! When I first heard about it I thought "I have good XInclude implementation for .NET in Mvp.Xml library, let's check out if Saxon on .NET works with XInclude.NET". I did some testing only to find out that they didn't play well together.
Turned out Saxon (or JAXP port to .NET, don't remember) relies on somewhat rarely used in .NET XmlReader.GetAttribute(int) method (yes, accessing attribute by index), and XIncludingReader had a bug in this method.
Finally I fixed it and so XIncludingReader from recently released Mvp.Xml library v2.3 works fine with Saxon on .NET.
Here is a little sample how to process XML Inclusions in source XML document before XSLT transformation.
using System;
using Saxon.Api;
using Mvp.Xml.XInclude;
class Program
{
static void Main(string[] args)
{
Processor proc = new Processor();
XdmNode doc = proc.NewDocumentBuilder().Build(
new XIncludingReader("d:/test/document.xml"));
XsltExecutable xslt = proc.NewXsltCompiler().Compile(
new Uri("d:/test/foo.xsl"));
XsltTransformer trans = xslt.Load();
trans.InitialContextNode = doc;
Serializer ser = new Serializer();
ser.SetOutputStream(Console.OpenStandardOutput());
trans.Run(ser);
}
}
I released version 2.3 of the Mvp.Xml Library, which is part of the Mvp.Xml Project developed by Microsoft MVPs in XML technologies worldwide. It is aimed at supplementing .NET framework XML processing functionality. Mvp.Xml Library provides .NET implementations of the EXSLT, XML Base, XInclude, XPointer as well as a unique set of utility classes and tools making XML programming in .NET platform easier, more productive and effective.
This is another minor release of the Mvp.Xml Library for .NET 2.0. Version 2.3 fixes lots of bugs and introduces some new features. Most important new features include:
XHTML output mode for the MvpXslTransform class
XSLT2-like output character mapping for the MvpXslTransform class
XmlWrappingReader and XmlWrappingWriter to simplify creating of custom XmlReader or XmlWriter
XIncludingReader now implements IXmlLineInfo interface
MvpXslTransform.AddExsltExtensionObjects() method allows to add EXSLT extension functions to your XsltArgumentList instance
XIncludingReader.Encoding property
New Mvp.Xml Library API documentation site generated using Sandcastle/DocProject, hosted at http://www.xmllab.net/mvpxml
Most important bugs fixed:
XIncludingReader now works well with Saxon.NET, XmlSerializer, DataSet and others
Library DLL is now debuggable
No more XmlValidatingReader and XmlTextReader used
Seems like my wife has found the hobby of her life. She's all about photography now. Books, sites, forums. She's overgrown our little but powerful Canon S70 and got new shiny (not really shiny, but a black one) Canon 400D (aka XTi). S70 is finally mine again!
Awesome. Note that toolbar buttons are nowhere to be seen. I noticed that while I'm only barely use toolbar, it still takes lots of space and more irritating - distracts attention like xmas tree and tends to rearrange itself I have no idea why. Besides turning toolbar off is the best way to learn keyboard shortcuts and once you do so you never look back. While you at it, here is a nice Visual Studio .NET 2005 Keyboard Shortcuts poster from Jeff Atwood.
What is the hardcore way of extending Visual Studio: VSIP.
And what are the first things that come to mind when you think of “VSIP”: expensive and obscure. Expensive because it used to be 10k/year and obscure because its COM roots and it’s very poor (close to inexistent) documentation.
You tell me how do you build a huge community around expensive and obscure? You just simple can’t. I believe the past years were more than enough to prove this.
Can you build a community around VSX? Although this is surely an improvement over expensive and obscure, IMO, this is still not enough.
Why?
Because all of the “obscure” it’s still there. Because you still need to mess with COM interfaces all the time and the versioning craziness like “IVsComponentEnumeratorFactory3” and native structures and enumerations that were coded when naming like “__VSMEPROPID2.VSMEPROPID_LAST2” made any sense. Let alone the VBisms you can find in today’s DTE automation layer (like indexes starting at 1 instead of 0, etc). Also, I don’t want 45 different and incompatible ways of doing the same thing.
Well, again, I feel the same way. While VSIP is free now, I believe Microsoft already missed the chance to make Visual Studio the development platform of choice for masses. Think about it - when Eclipse didn't exist yet, Microsoft already had fully extensible rich Visual Studio platform, but they were stupid enough to make it fully closed, very complex and stunningly expensive. No wonder everybody loves extending Eclipse platform and even gurus hate extending Visual Studio.
Microsoft XML Team posted a series of screencasts unveiling some new features in Visual Studio Orcas 2008. Short ones, but to the point, without blablahblah. I particularly like XML Editor ability to generate stub XML document from XML schema in just one tab click. Oh, and XSLT debugging is getting better and better. Data breakpoints is a great feature.
Ok, done with sweet part. Black hat on. XSLT debugger still must be run using separate obscure button, called "Debug XSLT", which even has no keyboard shortcut. Hitting F5 will obviously start debugging C# or whatever actual project is. That sucks.
Every debugging menu item works for XSLT debugger, except well, "Start Debugger". I made this mistake zillion times - working on XSLT, want to debug, hit F5, getting C# debugger. Oh, wait, no I meant this button, where is it? That's wasted time. But come on, you are in C# project, that's why F5 starts C# debugger.
My solution to the problem is dedicated XSLT project type for Visual Studio I'm building in the IronXSLT. Separating is good here. The whole project is XSLT-centric, including of course F5 button. In XSLT project F5 will naturally start XSLT debugger.
Another painful point. Derek says his favorite XML Editor feature is "Go to definition":
One of my favorite 'hidden' features is goto-definition. Position the cursor on an element in a document with an associated schema, and F12 will jump you to the part of the schema that governs that element. I occasionally get some very complex customer schemas. F12 can also be used to navigate with-in a schema, from an element declaration to the declaration of it's type, or to the base type declaration. When the schema spans megabytes and multiple files, this is invaluable.
Call me a freak, but I hate "Go to definition" feature in Visual Studio XML Editor. Not because I think going to the definition is bad idea, but because it fools me too many times. It's useful feature when editing XML, but terrible joke when editing XSLT. And 80% of time spent in XML Editor I'm editing XSLT. Huge XSLT stylesheet, call to some template: <xsl:call-template name="go-find-me-template"/>. I want to see the template. Click on "go-find-me-template", F12 - Boom - XSD definition for xsl:template element. That sucks.
I mean it's not fully done. XSLT Editor must override "Go to definition" command and provide meaningful implementation. Currently it's wrong. Nobody wants to see XSD schema for XSLT. It's like when hitting F12 on a variable in C# code being shown C# grammar rule.
Again, I'm going to fix it in the IronXSLT. Not sure if I can override default "Go to definition" command, but at least I can provide my own, which will actually be useful in XSLT.
Craig Skibo of Microsoft writes about new thing they announced recently - Visual Studio Shell. What the hell is that? Marketing description is unreadable:
A streamlined Visual Studio development environment, the Visual Studio Shell provides the core foundation so you can focus on building your application’s unique features.
But Craig gives a description mortals like me can understand:
Over the years many people have been creating packages and Add-ins for Visual Studio, but if anybody wanted to use your package, they had to have a copy of Visual Studio (pro or above) installed on their computer or you had to license what we called the PPE (or “Premier Partner Edition” – another beautiful name) and it was not exactly cheap.
What I have been working on is allowing you to, by building a small exe program and editing an even smaller text file that looks like a .reg file, create your own application which consumes the Visual Studio shell. Your program is branded with your company name and logos in any way that you wish, the only place that any Microsoft logo appears is on the splash screen where on the bottom right we put the text “Powered By Visual Studio”. And best of all – it is free!!! You can also distribute the PPE version of Visual Studio Shell, for free!!!
Ok, so Visual Studio Shell looks like Microsoft answer to the Eclipse Platform.
That's a good move, but what bother me tough is the fact that building plugins for Visual Studio is still a nightmare compared to building Eclipse plugins. If Microsoft wants to achieve at least a portion of adoption Eclipse platform has they have to simplify Visual Studio SDK programming substantially. Which is hardly possible without substantial redesign/rewrite of this 10 years old monster.
Visual Studio Hawaii (next after Orcas) was supposed to be such new dramatically redesigned version. And this announcement sounds like a sign of a major Visual Studio redesign going on right now.
I found this gem in David Carlisle's blog. Smart Javascript trick allows to mask msxsl:node-set() extension function as exsl:node-set() and so you can easily write crossbrowser XSLT stylesheets using exsl:node-set() functionality. Opera 9, Internet Explorer 6-7 and Firefox 3 are covered, but sadly Firefox 2 is out of the game. Julian Reschke came with a nice trick using Javascript expressiveness:
That reminds me old days of mine when I came with a similar trick for EXSLT extension functions implemented in C# (for EXSLT.NET project). Except that C# isn't so dynamic as Javascript so I had to escape to renaming method names in MSIL bytecode. That trick still drives EXSLT.NET (now module of the Mvp.Xml library).
By the way just to remind you - .NET (XslCompiledTransform) supports exsl:node-set() function natively.
Yes, I'm trying to change the way you work with XSLT in Microsoft Visual Studio. It must be a pleasure to develop and rocket fast at runtime. Yes, Visual Studio already supports editing, running and even debugging XSLT, but it's still a painfully limited support. So I'm started building IronXSLT - Visual Studio plugin aimed to provide total integration of the XSLT language in Visual Studio IDE.
Current list of planned and already implemented IronXSLT features includes:
XSLT Library Project (Visual Studio project type for compiling XSLT into DLL)
XSLT Refactorings
Multiple XSLT engines
XSLT Profiler
Extensive library of XSLT code snippets
XPath Intellisense
Visual XSLT builder
XSLT2XLinq and XLinq2XSLT converters
IronXSLT version 0.1 implements first point.
IronXSLT supports only forthcoming Microsoft Visual Studio version, codenamed "Orcas", which is about to be released later this year. That also makes IronXSLT ship date.
IronXSLT is free for personal and commercial usage, but not open source currently.
I was reading Scott's post on Reflector Addins and had this idea... Now (well, not now but in the next .NET version - Orcas) that XSLT can be compiled into dll, it must be time to think about XSLT decompiler (and appropriate Reflector addin of course). I believe that must be feasible. Would it be useful for you?
Google has started to migrate AdSense users to Google Accounts and it broke my little AdSense Watch Toolbar - it couldn't login into account. For the first time and only because I haven't coded login procedure flexible enough. The change was oneliner - just different URL.
Anyway, I uploaded AdSense Watch Toolbar v1.0.1, which supports both old AdSense and new Google Accounts. If you migrated to Google Accounts, please update.
Do you realize that PDF documents can contain embedded Javascript code? Yes, it can. Adobe Acrobat Reader supports Javascript 1.5 extended by Adobe and it allows such sweet things as dynamic PDF content and appearance manipulation, database-driven PDF documents, multimedia, layers, 3D, Flash in PDF (!) etc.
We've seen fancy PDF documents with animations, lame PDF calculators, but where is the real beef? Where is Web2-like stuff, where are AJAXy PDF eBooks?
The platform appears to be strong enough, the Adobe Acrobat Reader market penetration must be huge, so why smart eBooks still nowhere to be seen? I can imagine lots of opportunities:
Autcomplete search field prepopulated with index words? That would improve search in huge documents, which is still a nightmare despite all Adobe efforts
Dynamic context ads in eBooks? Many would hate it, but authors and publishers would appreciate such revenue stream. Say, small text-based context ad on every 5th page wouldn't harm much. After all unlike Web pages eBooks usually have lots the real content so it must be easy to produce really well targeted context ads.
Social features in eBooks? That might be huge. eBook readers form natural social community, which is currently completely hidden. "Recent readers" sidebar, annotations, ratings, comments, chatting, "Digg this book"?
Autoupdating eBooks? "New book edition is published, get it here" or even "Book updates available, download?". Why not?
These are just few the most obvious ideas. Sure you can come up with more.
I installed Microsoft Visual Studio Codename Orcas Beta1 and was really pleased to see that it's finally capable of targeting not only .NET 3.5. It supports .NET versions 2.0, 3.0 and 3.5. This is going to be the first multitargeted Visual Studio version, so far I had to keep Visual Studio .NET for maintaining .NET 1.0 applications, Visual Studio .NET 2003 for .NET 1.1 applications and Visual Studio 2005 for .NET 2.0, what a mess (especially provided that single Eclipse installation works just fine with Java 1.3, Java 2, Java 5 and Java 6). Now that's cool.
I mean pre-XProc XSLT pipeline - just when you need to transform an XML document by a sequence of XSLT stylesheets - output from the first transformation goes as input to the second one and so on. This is useful technique helping dramatically simplify your complex multi-stage XSLT stylesheets. Unfortunately there is no simple way to perform such task effectively in .NET 2.0. Here I show you how Mvp.Xml project comes to the rescue.
Note: there is old crappy Microsoft KB article 320847 suggesting pipelining XSLT via byte buffer, Bleh!, don't do this.
The problem is that while the most efficient (fastest, taking less memory) XML store for doing XSLT transformations in .NET 2.0 is still old good XPathDocument (not surprisingly specially designed and optimized for XPath and XSLT), there is no way to take XSLT output directly to XPathDocument. XslCompiledTransform doesn't provide XmlReader over its output. It can do XmWriter, but XPathDocument cannot be loaded via XmlWriter (this is likely to be fixed in post Orcas .NET version).
The problem was solved though. Sergey Dubinets from the Microsoft XML Team contributed his excellent XslReader implementation, which provides an efficient way to read XSLT results as XmlReader. I later wrapped it all into MvpXslTransform class, which extends capabilities of the XslCompiledTransform class by adding support for transforming into XmlReader , vast collection of EXSLT extension functions, multiple outputs and transforming of IXPathNavigable along with XmlResolver.
Here is finally code sample that says it all:
using System;
using System.Xml.Xsl;
using System.Xml.XPath;
using System.Xml;
using Mvp.Xml.Common.Xsl;
class Program
{
public static void Main()
{
MvpXslTransform xslt1 = new MvpXslTransform();
xslt1.Load("../../XSLTFile1.xslt");
MvpXslTransform xslt2 = new MvpXslTransform();
xslt2.Load("../../XSLTFile2.xslt");
XPathDocument doc = new XPathDocument("../../source.xml");
XmlReader stage1Output = xslt1.Transform(new XmlInput(doc), null);
xslt2.Transform(new XmlInput(stage1Output), null,
new XmlOutput(Console.Out));
}
}
Specifying the Sitemap location in your robots.txt file
You can specify the location of the Sitemap using a robots.txt file. To do this, simply add the following line:
Sitemap: <sitemap_location>
The <sitemap_location> should be the complete URL to the Sitemap, such as: http://www.example.com/sitemap.xml
This directive is independent of the user-agent line, so it doesn't matter where you place it in your file. If you have a Sitemap index file, you can include the location of just that file. You don't need to list each individual Sitemap listed in the index file.
By the way, the need to annotate HTML 5 with "W3C" means there is already a potential confusion. In fact WHATWG is working two specifications: Web Applications 1.0 and Web Forms 2.0, but who knows why they call them both HTML5. Now they are proposing W3C to adopt Web Applications 1.0 and Web Forms 2.0 ("WHATWG HTML5") along with editor as starting point to W3C next HTML version ("W3C HTML").
Dear HTML Working Group,
HTML5, comprising the Web Apps 1.0 and Web Forms 2.0 specifications,
is the product of many years of collaborative effort. It specifies
existing HTML4 markup and APIs with much clearer conformance criteria
for both implementations and documents. It specifies many useful
additions, in many cases drawing on features that have existed in
browser-based implementations for a long time. And it actively draws
on feedback from implementors and content authors. Therefore, we the
undersigned propose the following:
- that the W3C HTML Working Group adops the WHAT Working Group's
HTML5 as the starting point for further HTML development
- that the W3C's next-generation HTML specification is officially
named "HTML 5"
- that Ian Hickson is named as editor for the W3C's HTML 5
specification, to preserve continuity with the existing WHATWG effort
If HTML5 is adopted as a starting point, the contents of the document
would still be up for review and revision, but we would start with
the existing text. A suitable next step might be a high-level review
of functionality added and removed relative to HTML4.01, followed by
focused discussion and review of individual topic areas, including
both content already in the spec and proposed new features.
Discussions should be guided by common principles along the lines of
<http://esw.w3.org/topic/HTML/ProposedDesignPrinciples>
If the group is agreeable to these proposals, Apple, Mozilla and
Opera will agree to arrange a non-exclusive copyright assignment to
the W3 Consortium for HTML5 specifications.
L. David Baron, Mozilla Foundation
Lars Erik Bolstad, Opera Software ASA
Brendan Eich, Mozilla Foundation
Dave Hyatt, Apple Inc.
Håkon Wium Lie, Opera Software ASA
Maciej Stachowiak, Apple Inc.
As you can see Mozilla, Opera, Apple and Google (Ian Hickson) are all here. Now W3C HTML WG chairs Chris Wilson (Microsoft) and Dan Connolly (W3C/MIT) have to decide. Interesting. So far seems like people on the public-html mail list like the idea, but personally I don't believe it's gonna happen. I'd like to be wrong though.
If the HTMLWG adopts the WHATWG spec as a starting point, and asks me to edit the HTML spec, then there will only be one spec. The WHATWG spec and the HTML WG spec would be one and the same.
Ian Hickson
And if not then what? Two different HTML 5 specifications? OMG. Interesting times ahead.
Amazon has launched Context Links Beta program. The idea is that you insert a little Amazon script into your pages and when the page is open in a browser the script identifies words and phrases it thinks are relevant and makes them links to whatever Amazon products.
I enabled the script on my blog's frontpage (pinky double underlined links) to see how relevant it is and here are the results:
So here is nXSLTC.exe v1.0b - an experimental XSLT compiler for .NET 3.5 (Visual Studio "Orcas"). Get it here (free open-source). I probably shouldn't be building this tool, but I have my reasons.
Why not? As a matter of fact, Mike Champion has announced back in February that Microsoft will provide XSLTC.exe tool in the next Visual Studio "Orcas", but apparently it didn't make it into March CTP, at least I didn't manage to find it. It probably will be included into the next drop.
Why yes? First - this is the best way of learning new technology and then - I plan to build something bigger, which Microsoft won't be doing - XSLT project for Visual Studio, so I need this code anyway.
Ok, so nXSLT.exe. It's a command line XSLT compiler for .NET 3.5. It compiles one or more XSLT stylesheets into DLL. These compiled stylesheets can be later used to transform XML documents using XslCompiledTransform class.
Apparently SourceForge.net is planning to come up with a feature that would allow to buy or sell services or support for open source projects. Here is a mail I received:
Dear SourceForge.net community member,
As an active participant in the Open Source community, you may be excited
to learn about a new feature that we will add to SourceForge.net in late
spring/early summer. This feature will allow you to buy or sell services
for Open Source software on SourceForge.net.
Interested? Follow the link below and we'll keep you updated as we move
towards the official launch of this feature:
https://ostg.wufoo.com/forms/marketplace-interest-list/
Thank you for your continued support,
The SourceForge.net Team
Sounds interesting. Another way to get rich - create great open source product, make your code unreadable, provide no documentation and then sell support :)
In ASP.NET when you building a server control that includes an HTTP handler you have this problem - the HTTP handler has to be registered in Web.config. That means it's not enough that your customer developer drops control on her Web form and sets up its properties. One more step is required - manual editing of the config, which is usability horror.
How do you make your customer aware she needs to perform this additional action? Documentation? Yes, but who reads documentation on controls? I know I never, I usually just drop it on the page and poke around its properties to figure out what I need to set up to make it working asap.
In your control's designer class override ControlDesigner.GetDesignTimeHtml() method, which is called each time your control needs to be represented in design mode.
In the GetDesignTimeHtml() method check if your HTTP handler in already registered in Web.config and if it isn't - just register it.
Here is a sample code that worth hundred words:
using System;
using System.Web.UI.Design;
using System.Security.Permissions;
using System.Configuration;
using System.Web.Configuration;
using System.Windows.Forms;
namespace XMLLab.WordXMLViewer
{
[SecurityPermission(SecurityAction.Demand,
Flags = SecurityPermissionFlag.UnmanagedCode)]
public class WordXMLViewerDesigner : ControlDesigner
{
private void RegisterImageHttpHandler()
{
IWebApplication webApplication =
(IWebApplication)this.GetService(typeof(IWebApplication));
if (webApplication != null)
{
Configuration configuration = webApplication.OpenWebConfiguration(false);
if (configuration != null)
{
HttpHandlersSection section =
(HttpHandlersSection)configuration.GetSection(
"system.web/httpHandlers");
if (section == null)
{
section = new HttpHandlersSection();
ConfigurationSectionGroup group =
configuration.GetSectionGroup("system.web");
if (group == null)
{
configuration.SectionGroups.Add("system.web",
new ConfigurationSectionGroup());
}
group.Sections.Add("httpHandlers", section);
}
section.Handlers.Add(Action);
configuration.Save(ConfigurationSaveMode.Minimal);
}
}
}
private bool IsHttpHandlerRegistered()
{
IWebApplication webApplication =
(IWebApplication)this.GetService(typeof(IWebApplication));
if (webApplication != null)
{
Configuration configuration =
webApplication.OpenWebConfiguration(true);
if (configuration != null)
{
HttpHandlersSection section =
(HttpHandlersSection)configuration.GetSection(
"system.web/httpHandlers");
if ((section != null) && (section.Handlers.IndexOf(Action) >= 0))
return true;
}
}
return false;
}
static HttpHandlerAction Action
{
get
{
return new HttpHandlerAction(
"image.ashx",
"XMLLab.WordXMLViewer.ImageHandler, XMLLab.WordXMLViewer",
"*"
);
}
}
public override string GetDesignTimeHtml(DesignerRegionCollection regions)
{
if (!IsHttpHandlerRegistered() &&
(MessageBox.Show(
"Do you want to automatically register the HttpHandler needed by this control in the web.config?",
"Confirmation", MessageBoxButtons.YesNo,
MessageBoxIcon.Exclamation) == DialogResult.Yes))
RegisterImageHttpHandler();
return base.CreatePlaceHolderDesignTimeHtml("Word 2003 XML Viewer");
}
}
}
Obviously it only works if your control gets rendered at least once in Design mode, which isn't always the case. Some freaks (including /me) prefer to work with Web forms in Source mode, so you still need to write in the documentation how to update Web.config to make your control working.
I was cleaning up my backyard and found this control I never finished. So I did. Here is Word 2003 XML Viewer Control v1.0 just in case somebody needs it. It's is ASP.NET 2.0 Web server control, which allows to display arbitrary Microsoft Word 2003 XML documents (aka WordML aka WordprocessingML) on the Web so people not having Microsoft Office 2003 installed can browse documents using only a browser.
The control renders Word 2003 XML documents by transforming content to HTML preserving styling and extracting images. Both Internet Explorer and Firefox are supported.
Word 2003 XML Viewer Control is Web version of the Microsoft Word 2003 XML Viewer tool and uses the same WordML to HTML transformation stylesheet thus providing the same rendering quality.
The control is free open-source, download it here, find documentation here.
I'm doing interesting trick with images in this control. The problem is that in WordML images are embedded into the document, so they need to be extracted when transforming to HTML. And I wanted to avoid writing images to file system. So the trick is to extract image when generating HTML (via XSLT), assign it guid, put it into session and generate <img> src attribute requesting image by guid. Then when browser renders HTML it requests images by guid and custom HTTP handler gets them from the session.
Having HTTP handler in ASP.NET control posed another problem - how do you register HTTP handler in Web.config automatically? AFAIK there is no out of box solution for the problem, but happily I found a solution that covers major use case. Here is piece of documentation:
When you are adding the first Word 2003 XML Viewer Control in your Web project, you should see the following confirmation dialog: "Do you want to automatically register the HttpHandler needed by this control in the web.config?". You must answer Yes to allow the control to register image handler in the Web.config. If don't answer Yes or if you add the control not in Design mode, you have to add the following definition to the Web.config in the <system.web> section: <httpHandlers> <add path="image.ashx" verb="*" type="XMLLab.WordXMLViewer.ImageHandler, XMLLab.WordXMLViewer" /> </httpHandlers>
Yep. the hint is the Design mode. I'll post about this trick tomorrow.
The usage is simple - just drop control and assign "DocumentSource" property (Word 2003 XML file you want to show).
I deliberately named this control "Word 2003 XML Viewer Control" to avoid confusion. But I'll update it to support Word 2007 as soon as there is Word 2007 to HTML transformation problem solution.
XSLT isn't the best language for string processing, but it (XPath actually) has a very handy pair of substring functions: substring-before() and substring-after(). I used to write XSLT a lot and always missed them in C# or Java. Yes, C# and Java have indexOf() and regex, but indexOf() is too low-level and so makes code more complicated than it needs to be, while regular expressions is overkill for such simple, but very common operation.
Anyway, as an exercise in C# 3.0 I built these string extension functions following XPath 1.0 semantics for the substring-before() and substring-after(). Now I can have clean nice
Well, I missed MVP Summit this year, so while fellow MVPs enjoying together in Redmond I'm playing with C# 3.0 at home. And I'm in the process of Ruby learning, so what I spotted immediately is the lack (correct me if I'm wrong) of Each() and Map() support in .NET 3.5 collections.
In Ruby you can apply a block of code to each element in a collection using very elegant each() method:
[1,2,3].each { |item| puts item*item }
Each() method is basically a Visitor pattern implementation. I wonder why no such handy method exists in .NET 3.5? Dozens and dozens of new extension methods on collections covering every single aspect of collection manipulation from filtering to aggregation, but no basic functional programming facilities like Each() and Map()? Probably whoever at Microsoft decided foreach loop is still preferable solution for processing each element in a collection. That's what foreach does and does well.
I just started coding some real application with C# 3.0 (this is my favorite way of learning things) and immediately I can say I love it. C# 3.0 is going to be the best C# version ever. For me personally C# 1.0 was "hey look, kinda Java for Windows", C# 2.0 was "finally generics" and C# 3.0 is "wow, that's cool!".
Anyway, how do you check if a regular unsorted array contains particular element? Loop over elements checking each? Boring imperative crap. C# 3.0 provides nice declarative solution via Contains<T>(this IEnumerable<T>, <T> value) extension method:
This is not particularly new, but I didn't know about it before today and it did save my ass when I needed to browse non-mobile-friendly site on my phone really bad this morning.
It's http://www.google.com/gwt/n - Google mobile proxy service. It allows to browse to any web site using your mobile by "adapting it" - reformatting content and soft of squizzing it. As a matter of interest it also strips out Google AdSense ads. Cool.
Yes, believe it or not, but after HTML 4.01, which was finished back in 1999, W3C did nothing to improve HTML.
Meantime Google, Apple, Mozilla and Opera being disappointed in W3C lack of interest in HTML further development, have created WHATWG (Web Hypertext Application Technology Working Group), whose tagline is not less but "Maintaining and evolving HTML since 2004".
The new W3C HTML working group is scheduled to deliver new HTML version (in both classic HTML and XML syntaxes) by 2010. It's 3 years only. I doubt W3C as it is now can deliver something as much important as HTML5 in just 3 years.
WHATWG must be pretty much pissed off now. From WHATWG blog:
Surprisingly, the W3C never actually contacted the WHATWG during the chartering process. However, the WHATWG model has clearly had some influence on the creation of this group, and the charter says that the W3C will try to “actively pursue convergence with WHATWG”. Hopefully they will get in contact soon.
Well, actually the chapter says more:
Web Hypertext Application Technology Working Group (WHATWG)
The HTML Working Group will actively pursue convergence with WHATWG, encouraging open participation within the bounds of the W3C patent policy and available resources.
Good enough.
I'm only afraid that W3C can kill WHATWG and then bury HTML5 down in endless meetings settling down dependencies, IP issues, conflicting corporate interests and such. W3C can spend on HTML5 5-10 years easily.
Hot, hot, hot! Microsoft Pre-release Software Visual Studio Code Name "Orcas" - March 2007 Community Technology Preview (CTP) is available for download.
This is the first mostly feature complete Visual Studio v.next version (Visual Studio 2007 I bet).
6Gb download, so before click on the link take a look at what's new and decide if you need it. It's Pre-release and Community Technology Preview too. Anyway here are some highlights:
Google launches Premier Edition of the google.com/a - Google Apps. It's:
Gmail (10Gb mailbox), Google Talk, Google Calendar, Docs & Spreadsheets, Page Creator and Start Page
99.9% uptime guarantee for email (only for email?)
opt-out for ads in email - doh!
Shared calendar
Single sign-on
User provisioning and management
Support for email gateway
Email migration tools (Limited Release)
24/7 assistance, including phone support
3rd party applications and services
for mere $50/year per user. Sounds tempting for microISVs and small businesses.
They say it's cheap alternative to Microsoft Office. I'm not convinced. $50 x 4-5 years = Microsoft Office price, but I'm not sure one can compare Google Apps and Microsoft Office featurewise (yet).
Microsoft decided to shut down GotDotNet site by July 2007. The official announcement goes like this:
Microsoft will be phasing out the GotDotNet site by July 2007.
Microsoft will phase out all GotDotNet functionality by July 2007. We will phase out features according to the schedule below. During the phase-out we will ensure that requests for features or pages that are no longer available will render enough information for you to understand what has changed. If you have any questions please don’t hesitate to contact the GotDotNet Support team. We are phasing out GotDotNet for the following reasons:
Microsoft wants to eliminate redundant functionality between GotDotNet and other community resources provided by Microsoft
Traffic and usage of GotDotNet features has significantly decreased over the last six months
Microsoft wants to reinvest the resources currently used for GotDotNet in new and better community features for our customers
If you still hosting anything at the GotDotNet - here is your moving deadlines:
Phase Out Schedule The GotDotNet phase out will be carried out in phases according the following timetable:
Target Date Areas to be Closed
February 20 Partners, Resource Center, Microsoft Tools
March 20 Private workspaces, Team pages, Message Boards
April 24 GDN CodeGallery (projected date)
May 22 GDN User Samples (projected date)
June 19 GDN Workspaces (projected date)
Well, obviously that was inevitable. GotDotNet sucked big despite any efforts made. Looks like Microsoft was learning how to do open source project hosting on the web and GotDotNet was first that first pancake that is always spoiled. CodePlex definitely tastes better.
There are couple of projects still hosted at the GotDotNet that I care about:
Chris Lovett's SgmlReader. Awesome tool for reading HTML via XmlReader. I suggested Chris to contribute SgmlReader to the Mvp.Xml project, let's see if he likes the idea.
XPathReader. Cool pull-based streaming XML parser supporting XPath queries. I'm admin there actually, so I think we are going to move XPathReader under the Mvp.Xml project umbrella real soon.
According to the Official Google Reader Blog Google feed crawler, Feedfetcher, started to report subscriber counts. "The count includes subscribers from Google Reader and the Google Personalized Homepage, and in the future may include other Google products that support feeds."
What I found it interesting is that they do it via User Agent string. That's a very simple and nice solution and it's apparently not something new as I just looked at my blog log file and found subscribers info from a variety of feed crawlers:
GET /blog/index.xml - x.x.x.x HTTP/1.1 Bloglines/3.1+(http://www.bloglines.com;+154+subscribers)
GET /blog/index.xml - x.x.x.x HTTP/1.1 NewsGatorOnline/2.0+(http://www.newsgator.com;+99+subscribers)
GET /blog/index.xml - x.x.x.x HTTP/1.1 Feedfetcher-Google;+(+http://www.google.com/feedfetcher.html;
+167+subscribers;+feed-id=xxxxxxx)
GET /blog/index.xml - x.x.x.x HTTP/1.1 Newshutch/1.0+(http://newshutch.com;+12+subscribers)
And even such funny user agent as
GET /blog/index.xml - x.x.x.x HTTP/1.1 Mozilla/5.0+(X11;+U;+Linux+i686;+en-US;+rv:1.2.1;
+Rojo+1.0;+http://www.rojo.com/corporate/help/agg/;
+Aggregating+on+behalf+of+15+subscriber(s)+online+at+http://www.rojo.com/?feed-id=xxx)+Gecko/20021130
One might claim that's user agent header abuse, but I don't think so. Here is what RFC 2616 (HTTP) has to say:
The User-Agent request-header field contains information about the user agent originating the request. This is for statistical purposes, the tracing of protocol violations, and automated recognition of user agents for the sake of tailoring responses to avoid particular user agent limitations. User agents SHOULD include this field with requests. The field can contain multiple product tokens (section 3.8) and comments identifying the agent and any subproducts which form a significant part of the user agent. By convention, the product tokens are listed in order of their significance for identifying the application.
Statistical purposes that's it.
Oh, and while at it I should admit I hooked up to the Google Reader completely and haven't run RSS Bandit for months now. RSS Bandit has tons of cool features, but I always knew I need lightweight Web based feed reader. I tried Bloglines repeatedly, but only with Google Reader I found myself really comfortable from the first minute. That's great application.
These guys are like gmail in web hosting - they talk hundreds gigabytes of space and terabytes of bandwidth.
And for this "oh my freaking God" hosting plan they want $9.95/mo only (or even $7.95 if you subscribe for 2 years). But wait, google for "Dreamhost" and you can find promo codes like "mddr" or "FLY", which give you $97 discount for the first year.
Bottom line - you have to pay only $22.40 for the whole first year.
Cool. I want this. Fuck Windows hosting, go Linux and Ruby :)
Where is the catch, anybody?
Update. Ok, here comes the tricky part. "DreamHost Web Hosting does not accept payments from Israel". Really weird. What's wrong with payments from Israel? Oh well, happily I have US card too.
Kzu, being also one of the Mvp.Xml project users has this wild feature request. He wants to reverse XInclude resolving back. The scenario is simple: you load XML document A.xml containing XML Inclusions for B.xml and C.xml, XInclude processor resolves XML Inclusions, you get a combined document, edit it and then you save it back to A.xml, B.xml and C.xml. So if you have modified an element coming from B.xml then B.xml gets updated on save.
Well, that sounds like a reasonable feature, but how it can be done? To be able to reverse XML Inclusions one has to know exactly where each node came from, i.e. to preserve original context in a post-XInclude document.
Inclusion preserving context information is also known as a transclusion. Visual transclusion is traditionally associated with XLink instead and technically speaking XInclude has nothing to do with it. From XInclude 1.0 spec:
1.1 Relationship to XLink
XInclude differs from the linking features described in the [XML Linking Language], specifically links with the attribute value show="embed". Such links provide a media-type independent syntax for indicating that a resource is to be embedded graphically within the display of the document. XLink does not specify a specific processing model, but simply facilitates the detection of links and recognition of associated metadata by a higher level application.
XInclude, on the other hand, specifies a media-type specific (XML into XML) transformation. It defines a specific processing model for merging information sets. XInclude processing occurs at a low level, often by a generic XInclude processor which makes the resulting information set available to higher level applications.
Simple information item inclusion as described in this specification differs from transclusion, which preserves contextual information such as style.
So in an ideal world I'd just suggest Kzu to use XLink instead of XInclude for transclusions. The problem though is that XLink is basically dead for years now and unfortunately there is none XLink implementations for .NET. That's why XInclude.
The inclusion history of each top-level included item is recorded in the extension property include history. The include history property is a list of element information items, representing the xi:include elements for recursive levels of inclusion. If an include history property already appears on a top-level included item, the xi:include element information item is prepended to the list. If no include history property exists, then this property is added with the single value of the xi:include element information item.
So basically for each node in a post-XInclude document it's possible to figure out it's original context:
If a node has no ancestors having "include history" property, it belongs to the including XML document.
If there is such ancestor node then "include history" can be used to find out where this node came from.
Of course that only sounds simple. For starters Mvp.Xml XInclude implementation doesn't support "include history". XIncludingReader keeps internal stack of xi:include elements though and can expose it in some way. Then "include history" should be preserved in XML Infoset implementation, e.g. XML DOM - XmlDocument. That means XIncludeXmlDocument class extending XmlDocument. And then "include history" should be used when saving XmlDocument. Still sounds feasible.
Problems. What about partial inclusions with XPointer? if a node was included from inside a document its full XPath must be preserved in "include history" so it can be saved back at exactly the same location. Still feasible.
Editing combined document opens Pandora's box. New nodes - where they should be saved. Deleting nodes - how to detect? Moving nodes around. Multiple inclusions of the same node - how to resolve conflicts?
Well, still it sounds mostly feasible to implement transclusion on top of XInclude.
Any comments? Does anybody think it might be useful?
Welcome to the new XForms.org Community Web Portal, a central clearinghouse for articles and resources on XForms based technologies. This site is intended as one gateway into the XForms community (the other primary one being http://www.xforms.org itself), and provides the static side of the XForms.org community.
If you were thinking about learning Ruby - this is what you need to get started smoothly. Just released One-Click Ruby Installer1.8.5-22 Final for Windows is "A self-contained installer that includes the Ruby language, dozens of popular extensions, a syntax-highlighting editor and the book "Programming Ruby: The Pragmatic Programmer's Guide".
You would also need FreeRIDE - free full-blown Ruby IDE, written of course in Ruby.
So you get full Ruby runtime, decent IDE and a book - what else do you need? Go for it.
openxml.biz announced the availability of the OpenXML Writer - open source text editor for creating OpenXML WordprocessingML files (.docx). Supported features include "text formatting options like bold, italic, underline, font color, font name , font size, paragraph justification and text indentation. Basic editing functions like cutting, copying, pasting and spell check are also provided".
If you were using my little AdSense Watch Toolbar 1.0b version and it expired, I'm sorry about that, go and download new version 1.0, which has no time limitation.
After 6 months in beta I can say AdSense Watch proved to be pretty stable, which is kinda unusual for screenscraping applications. Google used to change AdSense site once in a months or two, breaking various AdSense tools, but this toolbar kept working just fine. I never had to fix it because of Google site changes. That's because AdSense Watch is only using screenscraping technique for logging in, the AdSense data itself is fetched as CSV in English, which happens to be stable enough.
So if you are AdSense addict, that's for you. And it's free. Feature requests are welcome.
Here is a problem: XSLT 1.0 sucks on generating XML character or entity references. I mean getting &foo; out of XSLT 1.0 is hard. The only ugly solution is disable-output-escaping hack, but it's a) optional, b)doesn't work in all scenarios (only when XSLT engine controls output serialization into bytes and c) works only on text nodes. Latter is real showstopper - you can't generate character or entity reference in attribute using XSLT 1.0. But now that we have XSLT 2.0, which is oh so better. What's XSLT 2.0 solution for the problem?
Google somehow seems to be inaccessible (down?) from my place for at least 15 minutes now and I already feel uncomfortable if not desperate. I want my mail, news and search back! Seriously, WTF? How come can I be so dependent on google? Ok, great, who else does search on the Web?
Everybody who speaks English can communicate with anybody else who also happens to speak English. You can talk, you can mail, you can read books written in English by others.
Sure you can invent your own language, no big deal. You can even make somebody learn it and then talk to her.
But most prefer easy way and speak XML, I mean English.
[Well, technically speaking majority on this planet prefer Chinese anyway].
I'm blogging since March 2003 and as time goes I noticed my blog archive list became way too long and ugly. Finally I figured out how to generate it in a nice expandable list form you can see on the right. Here is a my small how to for MovableType powered blog. It's a little bit hacky, but works fine.
But why oh why would anyone embed their XSLT in the assembly? The point is to separate design from logic. Even if the xslt does a non-presentational transform it _will_ be a pain to have to redeploy the assembly instead of just the stylesheet. Or not?
The idea is simple - generate list of categories with count of posts embedded into class attribute and then in browser scan categories and set font size according to any kind of cloud algorithm.
It's blooming time in Israel. Really nice around. My favorite time.
The photos are taken by Alenka, my wife. I think she's outgrown out little Canon S70 and needs some SLR camera. Anybody has any advices for buying first digital SLR thing?
Our users have made it very clear that they want an XSLT 2.0 implementation once the Recommendation is complete. A team of XSLT experts is now in place to do this, the same people who have been working on the XSLT enhancements that will be shipped in the forthcoming "Orcas" release of Visual Studio / .NET 3.5. Orcas development work is winding down in advance of Beta releases over the next several months, so there is no possibility of shipping XSLT 2.0 in Orcas. The XSLT team will, however, be putting out Community Technology Previews (CTP) with the XSLT 2 functionality and appropriate tooling as the implementation matures. The eventual release date and ship vehicles (e.g. a future version of .NET or a standalone release over the Web) have not been determined, and depend on technical progress, customer demand, and other currently unknowable factors.
Good. Very good news for those who invested in XSLT. XSLT 2.0 is sooooo much better,so much easier to develop with language. And I'm sure this new Microsoft XSLT 2.0 engine is gonna rock.
SAN JOSE, Calif. — Jan. 29, 2007 — Adobe Systems Incorporated (Nasdaq:ADBE) today announced that it intends to release the full Portable Document Format (PDF) 1.7 specification to AIIM, the Enterprise Content Management Association, for the purpose of publication by the International Organization for Standardization (ISO).
Looks like everybody nowadays wants to be open and ISO standardized. ODF is already ISO standard, OOXML on the way and now PDF joins the club.
Btw, Wikipedia article on PDF is definitely wrong (or written by Adobe) - how on earth this fully proprietary document format is called "an openfile format created and controlled by Adobe Systems"?
Provided the fact that Adobe forced Microsoft to remove "Save as PDF" feature from Office 2007 - because they wanted to charge a fee for it, PDF format clearly cannot be called "open format" - it's proprietary format controlled by Adobe and they wanted a fee from at least one vendor trying to implement it. I don't think that is open format.
I'm going to try to change Wikipedia article on PDF to see how it works. I'll report my progress.
And at the end one more curious comparison showing how heavily biased Wikipedia is: PDF vs RTF. Both proprietary document formats, published and widely implemented by both commercial and open tools. But guess what:
With a piece of PDF conversion
software, whether it's an individual license or a larger
PDF server package, you may find that various PDF conversion
options are more useful than you realized and that a PDF
converter can help speed things up around the office.
This is disturbing story. An evil person doing phishing collected 56,000 MySpace user names and passwords and posted them to the "Full-Disclosure" mail list, which is open "unmoderated mailing list for the discussion of security issues" everybody can subscribe to.
Now, of course the mail list is open and is archived by dozens of sites and of course MySpace could just change passwords for compromised users, but no, they instead decided to shut down one particular security site (seclists.org, why only this one?) that happens to be also archiving the "Full-Disclosure" mail list.
And MySpace wanted to make it done real fast, so not bothering about bullshit like contacting seclists.org site owner or hosting company they contacted the domain name registrar (!) which happens to be well respected (so far) Go-Daddy.com, and somehow convinced them to remove the whole seclists.org domain name from the DNS. Now that's cool.
The site is back on now, but Go-Daddy still defends seclists.org takedown, which smells more and more bad. Go-Daddy used to be my favorite domain name registrar. Now I'm (and probably many others) not sure. It's amazing how Go-Daddy turned MySpace problem into their own problem.
The Rich Text Format (RTF) Specification provides a format for text and graphics interchange that can be used with different output devices, operating environments, and operating systems. Version 1.9 of the specification contains the latest updates introduced by Microsoft Office Word 2007.
If somebody forgot, RTF is proprietary but widely supported non-XML document markup format, which looks like this:
{\rtf1\ansi{\fonttbl\f0\fswiss Helvetica;}\f0
Hello!\par
This is some {\b bold} text.\par
}
2007-01-22: The World Wide Web Consortium has published eight new standards in the XML family for data mining, document transformation, and enterprise computing from Web services to databases. "Over 1,000 comments from developers helped ensure a resilient and implementable set of database technologies," said Jim Melton (Oracle). XSLT transforms documents into different markup or formats. XML Query can perform searches, queries and joins over collections of documents. Using XPath expressions, XSLT 2 and XQuery can operate on XML documents, XML databases, relational databases, search engines and object repositories.
Wow. Congrats to everybody envolved. Lots of reading now.
Everybody knows that XSLT stylesheet can be embedded into an assembly by setting in Visual Studio its "BuildAction" property to "Embedded Resource". Such stylesheet then can be loaded using Assembly.GetManifestResourceStream() method.
But in fact, this is actually wrong way of loading embedded stylesheets, because once smarty-pants XML developer goes and breaks XSLT stylesheet into modules it suddenly stops working - xsl:import/xsl:include are not compatible with loading stylesheet via Assembly.GetManifestResourceStream().
The right way of loading embedded stylesheets is via XmlResolver. Having custom XmlResolver loading stylesheet from an assembly solves the problem. And even better - you can use such resolver to load main XSLT stylesheet:
using (XmlReader doc = XmlReader.Create("books.xml"))
{
XslCompiledTransform xslt = new XslCompiledTransform();
EmbeddedResourceResolver resolver =
new EmbeddedResourceResolver();
xslt.Load("Catalog.xslt",
XsltSettings.TrustedXslt, resolver);
xslt.Transform(doc, XmlWriter.Create(Console.Out));
}
The EmbeddedResourceResolver class can be as simple as:
using System;
using System.Xml;
using System.Reflection;
using System.IO;
namespace EmbeddedStylesheetSample
{
public class EmbeddedResourceResolver : XmlUrlResolver
{
public override object GetEntity(Uri absoluteUri,
string role, Type ofObjectToReturn)
{
Assembly assembly = Assembly.GetExecutingAssembly();
return assembly.GetManifestResourceStream(this.GetType(),
Path.GetFileName(absoluteUri.AbsolutePath));
}
}
}
Obviously above implementation is way too simple. Particularly it loads resources embedded into the assembly where EmbeddedStylesheetSample class is defined. This can be parametrized so e.g. the resolver can accept assembly name and optional culture name and load class from an appropriate assembly. I think I need to generalize EmbeddedResourceResolver and include it into the Mvp.Xml library so we could just use it and not reinventing again and again.
We spent this holidays season in Seattle area. For my wife and our little Cat it was first trip to the USA. And traveling between Middle East and North West USA with 20 month old girl is a challenge (Scott gives pretty good advices for kid-wise traveling). She did very well though, mostly sleeping during those 33 hours in the sky.
Happily we missed the record storm that hit Western Washington so when we arrived things were normal and we got electricity and heat in the hotel and all our local friends got electricity in homes already.
The weather was Seattlish - rain rain rain and lots of gray color in the sky. There were couple of days though when we could see the sun.
Xmas evening we were at the Dimitre Novatchev's house. First time I met Dimitre in person. We talked about everything. He showed me some great stuff he's working on, including a new XPath related application he's developed and having trouble to release because he works for Microsoft now. That was really nice evening.
I also met my friend Sergey Dubinets who does XSLT in Microsoft. They are all about this new important XSLT debugger feature I will be posting about as soon as it goes public.
After all it was nice trip and we managed to get home without anybody catching even a cold.
Well, new year is here and I couldn't agree more with Kent Tegels - I'm glad 2006 is finally over. 2006 sucked on so many levels, but mostly on a personal one. 2007 must be a better year. This is my unexpressive but hopefully achievable new year resolution.
As a good sign the year started with Microsoft MVP award. This is fourth year in a row I'm getting MVP award (for XML of course) and this time I was really worried about getting reawarded - it was lousy year and I didn't accomplish much. Congratulations to all fellow MVPs getting their awards again this year.
John D.: Or, you can hack it by replacing apostrophes with a read more
Anonymous: It would explain all the bugs... read more
The D00D: Oh LOL, XSLT. I wondered where the conditionals were, and read more
Sam: Does this wok with custom XSD . I have custom read more
Anonymous: Check this: http://msdn.microsoft.com/en-us/library/system.collections.sortedlist.contains.aspx Towards the middle of the page you read more
Buzzer: As for the & ampersand issue, simply call HTTPUtility.HTMLEncode in read more
Victor Conesa: Hi Oleg, I'm using the wml2xslt.exe to generate reports in read more
Ethyl Kruk: Have you read any of Cem Kaner's books? He is read more
steve oak: yes, tried and it works! you know what? I even read more
Tim: @Martin Kool Thanks for the registry-hint read more

 Better later than never. I uploaded
Better later than never. I uploaded  My goal was to make F5/Ctrl+F5 working intuitively right - when you work on XSLT Library project F5 should run project with debugger and Ctrl+F5 - without. When you have more that one stylesheet it's nice time saving feature, not to mention that start debugging command finally starts debugger
My goal was to make F5/Ctrl+F5 working intuitively right - when you work on XSLT Library project F5 should run project with debugger and Ctrl+F5 - without. When you have more that one stylesheet it's nice time saving feature, not to mention that start debugging command finally starts debugger 



 Here goes nxslt3.exe/NxsltTask v3.0. It's nxslt tool for .Net 3.5. It can do everything nxslt2/NxsltTask v2.3 can plus the ability to run compiled XSLT stylesheets.
Here goes nxslt3.exe/NxsltTask v3.0. It's nxslt tool for .Net 3.5. It can do everything nxslt2/NxsltTask v2.3 can plus the ability to run compiled XSLT stylesheets. I updated
I updated 




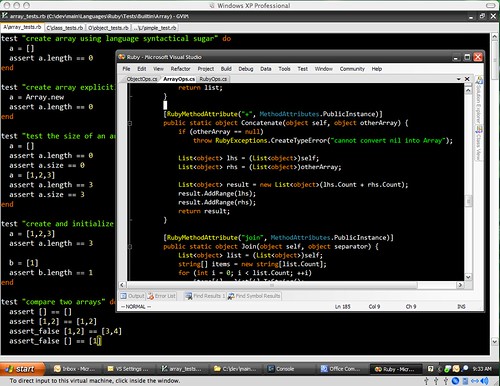





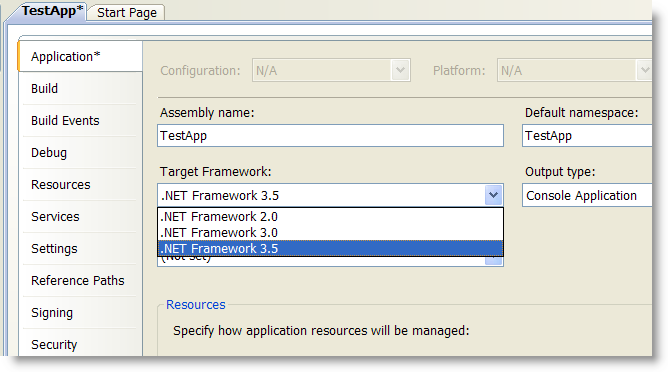

 So here is nXSLTC.exe v1.0b - an experimental XSLT compiler for .NET 3.5 (Visual Studio "Orcas").
So here is nXSLTC.exe v1.0b - an experimental XSLT compiler for .NET 3.5 (Visual Studio "Orcas").  I was cleaning up my backyard and found this control I never finished. So I did. Here is
I was cleaning up my backyard and found this control I never finished. So I did. Here is  Hot, hot, hot! Microsoft Pre-release Software Visual Studio Code Name "Orcas" - March 2007 Community Technology Preview (CTP)
Hot, hot, hot! Microsoft Pre-release Software Visual Studio Code Name "Orcas" - March 2007 Community Technology Preview (CTP)  Google launches Premier Edition of the
Google launches Premier Edition of the 






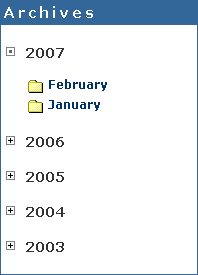 I'm blogging since March 2003 and as time goes I noticed my blog archive list became way too long and ugly. Finally I figured out how to generate it in a nice expandable list form you can see on the right. Here is a my small how to for MovableType powered blog. It's a little bit hacky, but works fine.
I'm blogging since March 2003 and as time goes I noticed my blog archive list became way too long and ugly. Finally I figured out how to generate it in a nice expandable list form you can see on the right. Here is a my small how to for MovableType powered blog. It's a little bit hacky, but works fine. I was writing about
I was writing about 






Recent Comments