March 30, 2005
wbloggar site hacked?
Generating Word documents using Java
Baby photos
Happy resource wasters
March 27, 2005
MSDN Webcast: Making the Most of XQuery with SQL Server 2005 (Level 300) - 4/26/2005
March 22, 2005
RSS Bandit v1.3.0.26 is here
The daughter!
March 15, 2005
MSDN Webcast on managing XML in SQL Server 2005 by Michael Rys
March 14, 2005
"XML Hacks" book review
March 12, 2005
MSDN upcoming webcasts RSS feed
VB6 is dead? Amen
March 10, 2005
How to speed up Muenchian grouping in .NET
Muenchian grouping includes a step of selecting unique nodes - first node for each group. Usually this is done using generate-id() or count() functions. There is another way to select nodes with unique value though - EXSLT's set:distinct() function, supported by EXSLT.NET. So I measured performance and scalability of all three methods.
The source XML is XML dump of the Orders database from the Northwind sample database, including 415 orders:
<root> <orders OrderID="10249" CustomerID="TOMSP" EmployeeID="6" OrderDate="1996-07-05T00:00:00" RequiredDate="1996-08-16T00:00:00" ShippedDate="1996-07-10T00:00:00" ShipVia="1" Freight="11.61" ShipName="Toms Spezialitten" ShipAddress="Luisenstr. 48" ShipCity="Munster" ShipPostalCode="44087" ShipCountry="Germany" /> <!-- 414 more orders --> </root>To unveil scalability issues I created bigger documents by multiplying number of orders by 2 (while keeping OrderID uniquness), so I got documents with 415, 830, 1660, 3320, 6640 and 13280 orders (from 135 Kb to 4.5 Mb). The task is to group orders by ShipCountry value. Here is the first stylesheet (classical Muenchian grouping with generate-id()):
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output indent="yes"/>
<xsl:key name="countryKey" match="orders" use="@ShipCountry"/>
<xsl:template match="root">
<table border="1">
<tr>
<th>Order ID</th>
<th>Ship City</th>
</tr>
<xsl:for-each select="
orders[generate-id()=generate-id(key('countryKey', @ShipCountry)[1])]">
<tr>
<th colspan="2">
<xsl:value-of select="@ShipCountry"/>
</th>
</tr>
<xsl:for-each select="key('countryKey',@ShipCountry)">
<tr>
<td>
<xsl:value-of select="@OrderID"/>
</td>
<td>
<xsl:value-of select="@ShipCity"/>
</td>
</tr>
</xsl:for-each>
</xsl:for-each>
</table>
</xsl:template>
</xsl:stylesheet>
Pretty trivial. Second version uses count() function instead of generate-id(), here is the relevant part:
<xsl:for-each select="
orders[count(.| key('countryKey', @ShipCountry)[1]) = 1]">
And third version uses set:distinct() function:
<xsl:for-each select="set:distinct(orders/@ShipCountry)/.." xmlns:set="http://exslt.org/sets">Here are the results I got when running all three stylesheets with above 6 XML documents on my ancient Dell workstation (P3 600MHz) using nxslt.exe:
| Grouping technique | Transformation time (ms) | |||||
|---|---|---|---|---|---|---|
| XML document size (number of orders to group) | ||||||
| 415 | 830 | 1660 | 3320 | 6640 | 13280 | |
| Muenchian Grouping (with generate-id()) | 151.722 | 407.619 | 1318.676 | 5290.962 | 27773.98 | 130860.1 |
| Muenchian Grouping (with count()) | 97.238 | 190.086 | 462.075 | 1401.199 | 4193.143 | 14015.86 |
| Muenchian Grouping (with (set:distinct()) | 94.499 | 155.035 | 276.465 | 687.494 | 1104.554 | 2503.871 |
The graph view works better:
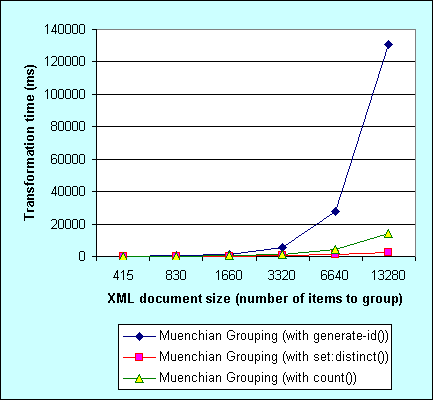
As can be seen, in .NET 1.1, Muenchian grouping using generate-id() is not only the slowest, but shows the worst scalability. Probably the reason is poor generate-id() function implementation. count() function performs much better, but still shows some scalability issues. And finally Muenchian grouping using set:distinct() function is the winner here - both in speed and good scalability. Sublinear running time, amazing. Kudos to Dimitre Novatchev for optimizing set:distinct() function implmentation in EXSLT.NET.
The bottom line - if you are looking for ways to speed up grouping in XSLT under .NET 1.X, use Muenchian grouping with set:distinct() function from EXSLT.NET to get the best perf and scalability. Otherwise use Muenchian grouping with count() function, which sucks less in .NET than generate-id() function does.
I wonder what would be results in .NET 2.0? Stay tuned guys.
Microsoft Certification Second Shot Offer - if you fail, try second time for free
March 6, 2005
XmlTextReader video tutorial from Dan Wahlin
March 3, 2005
Indexing XML article, part 1 - done
Another interview with Michael Rys on Microsoft SQL Server 2005 and XQuery
Microsoft SQLXML is not SQL/XML, which is written with a slash. SQL/XML is the common name for part 14 of the official ANSI SQL 2003 standard, which defines an xml data type, operations on the xml data type, a set of xml publishing functions, mapping rules from relational to xml data, and so on. SQL Server 2005's new XML data type is based on this standard.Hey, nice clarification. On XQuery support in SQL Server 2005:
So, we've chosen to focus on what is considered to be the more stable parts of the specification, which I believe address the majority of the use cases - I think that those who take advantage of SQL Server 2005's XQuery support functionality will reap the benefits that XQuery has to offer. Obviously, some customers will want more, but they should understand that we're committed to delivering more extensive support for XQuery over time as the XQuery specification becomes an official W3C recommendation.That should be safe. So get prepared, because:
Currently, the plan is to ship Microsoft SQL Server 2005 sometime this summer though the exact date has not been publicly announced.Now - the long awaited news - MSXML is back and kicking! I knew I'll happen.
As far as MSXML is concerned, we don't have a lot of requests for XQuery. And with Version 6.0, we think that MSXML will become the XML tools library for the native C and C++ code environment, and we'll continue to support it.XQuery in SQL Server 2005 internals:
If you get down to the nuts and bolts of it, SQL Server's XQuery processing facilities rely on the underlying SQL query processor -- they're really quite integrated and there's no easy way to separate the two. But this actually brings up an interesting point about SQL Server's XQuery processor architecture - that under the hood, we're able to leverage our top-of-the-line relational query optimization engine technologies. As XQuery is a declarative language, we're able to do a pretty advanced job at decomposing and optimizing the underlying query. We've brought several innovations to this space to make optimization of XQuery expressions possible, and there is much more that can be done. [See Microsoft's recent SIGMOD 2004 and VLDB 2004 papers for more information - Ed.]The papers are: "ORDPATHs: Insert-Friendly XML Node Labels" and "Indexing XML Data Stored in a Relational Database". ORDPATH is a hierarchical labeling scheme implemented in SQL Server 2005. Both articles are worth reading and contemplating.
And when it comes to XQuery support on client side - that's what I suspected:
If I was to summarize the state of XQuery support at Microsoft, I'd say that we think it's a great server-side technology for accessing large amounts of XML, its declarative nature makes it particularly well suited for optimization, and we support it 100%. On the client-side, we're still investigating here- we haven't seen our users crying out for declarative languages on the client side just yet.Fair enough.
And finally really good news:
The XQuery working group - we're currently preparing a final last call, and there's light at the end of the tunnel. I see the process leading to a recommendation, probably in Q1 2006.Now that sounds like a call for action. XQuery in SQL Server is soon to be here, so it's time to start learning and playing with this amazing technology. And that's what I'm gonna do.