November 2006 Archives
 ISO published RELAX NG standard (also "Compact Syntax") for free at the "Freely Available Standards" page. Hmmm, since when ISO provides free standard downloads? ISO published RELAX NG standard (also "Compact Syntax") for free at the "Freely Available Standards" page. Hmmm, since when ISO provides free standard downloads?
Also: Schematron, NVDL and more. [Via Rick Jelliffe]
I've been reading about XProc, new XML Pipeline language proposed by W3C. Used to control and organize the flow of documents, the XProc language standardizes interactions, inputs and outputs for transformations for the large group of specifications such as XSLT, XML Schema, XInclude and Canonical XML that operate on and produce XML documents. The "Proc" part stands for "Processing", so it's XML processing language. Here is a sample "validate and transform" pipeline just to give you a taste of what XProc is about: 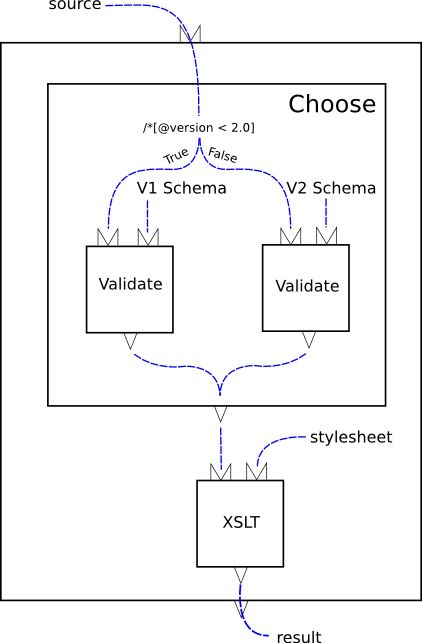
Here is how it's expressed: <p:pipeline name="fig2"
xmlns:p="http://example.org/PipelineNamespace">
<p:input port="doc" sequence="no"/>
<p:output port="out" step="xform" source="result"/>
<p:choose name="vcheck" step="fig2" source="doc">
<p:when test="/*[@version < 2.0]">
<p:output name="valid" step="val1" source="result"/>
<p:step type="p:validate" name="val1">
<p:input port="document" step="fig2" source="doc"/>
<p:input port="schema" href="v1schema.xsd"/>
</p:step>
</p:when>
<p:otherwise>
<p:output name="valid" step="val2" source="result"/>
<p:step type="p:validate" name="val2">
<p:input port="document" step="fig2" source="doc"/>
<p:input port="schema" href="v2schema.xsd"/>
</p:step>
</p:otherwise>
</p:choose>
<p:step type="p:xslt" name="xform">
<p:input port="document" step="vcheck" source="valid"/>
<p:input port="stylesheet" href="stylesheet.xsl"/>
</p:step>
</p:pipeline>
Syntax can spoil everything. We need visual XProc editor!
After all I think it's pretty damn good idea. I need it now. And we've got everything in .NET to implement it - XInclude, XSLT, validation, Canonical XML. So I'm going for this. This will be great addition to the Mvp.Xml project.
Here are some XProc resources to get you started:
- The XProc specification.
- XProc.org, the site tracking the progress of the XML Processing Model Working Group, maintained by Norman Walsh, chair of the WG. Lots of stuff, including XProc Wiki.
- public-xml-processing-model-comments mail list.
- Wikipedia article on the "XML pipeline"
- Norman Walsh's introductory essay on XProc, update.
- "Step By Step: Why XML Pipelines Make Sense" by Kurt Cagle.
- What people say about XProc - http://feeds.technorati.com/search/xproc
Just couple of months after XML Notepad 2006 release Microsoft ships another version, now called XML Notepad 2007. They even went and edited the article "XML Notepad 2006 Design" to be "XML Notepad 2007 Design". Cool. XML Notepad 2006 was released on the 1st September 2006, and 2 months later it had 175,000 downloads! So it looks like this little utility has found a useful place in your toolkit which is exactly what we were hoping. Thanks for all the great feedback and bug reports; many of which have been incorporated and fixed in this new version. While this is mostly a bug fix release (like fixing the install on Vista!) there are also a few new features thrown in just for fun. New in this version: - Added keyboard accelerators for find again (F3) and reverse find (SHIFT+F3).
- Added support for loading IXmlBuilder and IXmlEditor implementations from different assemblies using new vs:assembly attribute.
- Made source code localizable by moving all error messages and dialog strings to .resx files.
- Added a default XSL transform.
- New icons, a play on the Vista "Notepad" icons.
XML Notepad 2006 2007 is a tree view based XML editor, and it's not in my tool list because I can't work with XML editor which won't show me XML source, but then I'm XML geek and I feel more comfortable seeing angle brackets than tree view, while I'm sure lots of people will love it. Give it a try anyway. .gif)
I only wonder why all this stuff isn't in Visual Studio? Why is that Microsoft XML team can afford playing with another XML editor while Visual Studio XML Editor still sucks having no XML diff, no XPath search, no refactoring, no decent XSLT editor nor XML Schema designer?
Back in 2005 I was writing about speeding up Muenchian grouping in .NET 1.X. I was comparing three variants of the Muenchian grouping (using generate-id(), count() and set:distinct()). The conclusion was that XslTransform class in .NET 1.X really sucks when grouping using generate-id(), performs better with count() and the best with EXSLT set:distinct(). Here is that old graph: 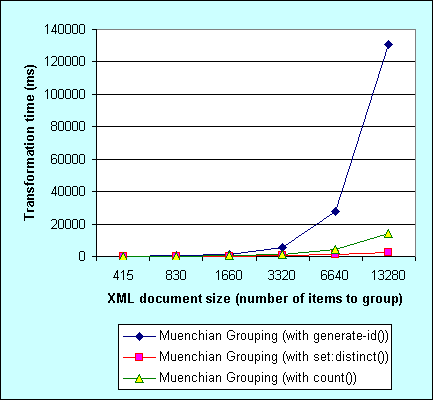
Today a reader reminded me I forgot to post similar results for .NET 2.0 and its new shiny XslCompiledTransform engine. So here it is. I was running simple XSLT stylesheet doing Muenchian grouping. Input documents contain 415, 830, 1660, 3320, 6640, 13280, 26560 and 53120 orders to be grouped. 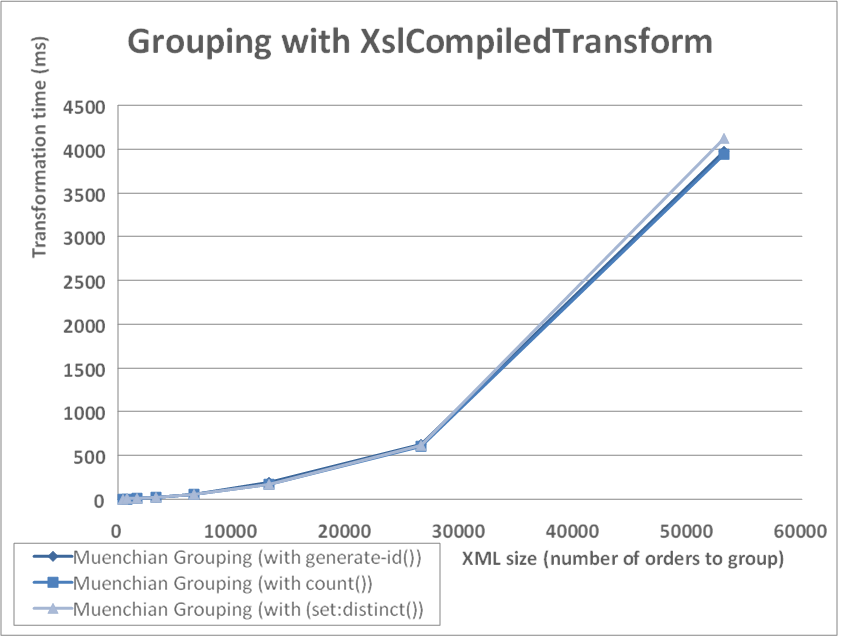
Besides being pretty damn faster that XslTransform, XslCompiledTransform shows expected results - there is no difference in a way you are doing Muenchian grouping in .NET 2.0 - all three variants I was testing are performing excellent with very very close results. Old XslTransform was full of bad surprises. Just switching to count() instead of generate-id() provided 7x performance boost in grouping. That was bad. Anybody digging into XslTransform sources knows how ridiculously badly generate-id() was implemented. Now XslCompiledTransform shows no surprises - works as expected. No tricks needed. That's a sign of a good quality software.
 From TSS.Net I found out that Raymond Chen, the man who can make Win32 programming exciting, published a book "The Old New Thing: Practical Development Throughout the Evolution of Windows". "The Old New Thing" is of course the name of his blog, described as "not actually a .NET blog". The book is to be available December 29. I want this book. From TSS.Net I found out that Raymond Chen, the man who can make Win32 programming exciting, published a book "The Old New Thing: Practical Development Throughout the Evolution of Windows". "The Old New Thing" is of course the name of his blog, described as "not actually a .NET blog". The book is to be available December 29. I want this book.
Why does Windows work the way it does? Why is Shut Down on the Start menu? And why is there a Start menu? Many of Windows' quirks have logical causes rooted in history. In The Old New Thing: Practical Development Throughout the Evolution of Windows, Raymond Chen, of Microsoft's Windows development team, reveals the "hidden Windows" developers and users need to understand. Chen helps readers understand Windows with behind-the-scenes explanations, technical information, and anecdotes. Topics include window and dialog management, performance optimization and why it can be so counterintuitive, an under-the-hood look at COM and the Visual C++ compiler, backwards compatibility, and little-known Windows program security holes. TSS.Net also publishes two chapters: Chapter One of The Old New Thing, titled "Initial Forays into User Interface Design," describes why Windows is the way it is. Chen answers some of the most frequently asked questions about the user interface, and tells the story and reasoning behind each tough decision and rule that the Windows team had to implement.
Download Chapter One: Initial Forays into User Interface Design Chapter Three of Chen's book, titled "The Secret Life of GetWindowText," addresses the complexity of GetWindowText, giving the full story behind the documentation. Chen also explains the compromises made around GetWindowText, and ways to escape its rules. Download Chapter Three: The Secret Life of GetWindowText Chapter one is particularly cool: - Why do you have to click the Start button to shut down?
- Why doesn’t Windows have an “expert mode”?
- The default answer to every dialog box is Cancel
- In order to demonstrate our superior intellect, we will now ask you a question you cannot answer
- Why doesn’t Setup ask you if you want to keep newer versions of operating system files?
- User interface design for vending machines
- User interface design for interior door locks
- The evolution of mascara in Windows UI
Reporting errors in XSLT stylesheets is a task that almost nobody gets done right. Including me - error reporting in nxslt sucks in a big way. Probably that's because I'm just lazy bastard. But also lets face it - XslCompiledTransform API doesn't help here. Whenever there are XSLT loading (compilation) errors XslCompiledTransform.Load() method throws an XsltException containing description of the first error encountered by the compiler. But as a matter of fact internally XslCompiledTransform holds list of all errors and warnings (internal Errors property). It's just kept internal who knows why. Even Microsoft own products such as Visual Studio don't use this important information when reporting XSLT errors - Visual Studio's XML editor also displays only first error. That sucks. Anyway here is a piece of code written by Anton Lapounov, one of the guys behind XslCompiledTransform. It shows how to use internal Errors list via reflection (just remember you would need FullTrust for that) to report all XSLT compilation errors and warnings. The code is in the public domain - feel free to use it. I'm going to incorporate it into the next nxslt release. I'd modify it a little bit though - when for some reason (e.g. insufficient permissions) errors info isn't available you still have XsltException with at least first error info. private void Run(string[] args) {
XslCompiledTransform xslt = new XslCompiledTransform();
try {
xslt.Load(args[0]);
}
catch (XsltException) {
string errors = GetCompileErrors(xslt);
if (errors == null) {
// Failed to obtain list of compile errors
throw;
}
Console.Write(errors);
}
}
// True to output full file names, false to output user-friendly file names
private bool fullPaths = false;
// Cached value of Environment.CurrentDirectory
private string currentDir = null;
///
/// Returns user-friendly file name. First, it tries to obtain a file name
/// from the given uriString.
/// Then, if fullPaths == false, and the file name starts with the current
/// directory path, it removes that path from the file name.
///
private string GetFriendlyFileName(string uriString) {
Uri uri;
if (uriString == null ||
uriString.Length == 0 ||
!Uri.TryCreate(uriString, UriKind.Absolute, out uri) ||
!uri.IsFile
) {
return uriString;
}
string fileName = uri.LocalPath;
if (!fullPaths) {
if (currentDir == null) {
currentDir = Environment.CurrentDirectory;
if (currentDir[currentDir.Length - 1] != Path.DirectorySeparatorChar) {
currentDir += Path.DirectorySeparatorChar;
}
}
if (fileName.StartsWith(currentDir, StringComparison.OrdinalIgnoreCase)) {
fileName = fileName.Substring(currentDir.Length);
}
}
return fileName;
}
private string GetCompileErrors(XslCompiledTransform xslt) {
try {
MethodInfo methErrors = typeof(XslCompiledTransform).GetMethod(
"get_Errors", BindingFlags.NonPublic | BindingFlags.Instance);
if (methErrors == null) {
return null;
}
CompilerErrorCollection errorColl =
(CompilerErrorCollection) methErrors.Invoke(xslt, null);
StringBuilder sb = new StringBuilder();
foreach (CompilerError error in errorColl) {
sb.AppendFormat("{0}({1},{2}) : {3} {4}: {5}",
GetFriendlyFileName(error.FileName),
error.Line,
error.Column,
error.IsWarning ? "warning" : "error",
error.ErrorNumber,
error.ErrorText
);
sb.AppendLine();
}
return sb.ToString();
}
catch {
// MethodAccessException or SecurityException may happen
//if we do not have enough permissions
return null;
}
}
Feel the difference - here is nxslt2 output: An error occurred while compiling stylesheet 'file:///D:/projects2005/Test22/Test22/test.xsl':
System.Xml.Xsl.XslLoadException: Name cannot begin with the '1' character, hexadecimal value 0x31.
And here is Anton's code output: test.xsl(11,5) : error : Name cannot begin with the '1' character, hexadecimal value 0x31.
test.xsl(12,5) : error : Name cannot begin with the '0' character, hexadecimal value 0x30.
test.xsl(13,5) : error : The empty string '' is not a valid name.
test.xsl(14,5) : error : The ':' character, hexadecimal value 0x3A, cannot be included in a name.
test.xsl(15,5) : error : Name cannot begin with the '-' character, hexadecimal value 0x2D.
It's surprisingly easy in .NET 2.0. Obviously it can't be done with pure XSLT, but an extension function returning line number for a node takes literally two lines. The trick is to use XPathDocument, not XmlDocument to store source XML to be transformed. The key is IXmlLineInfo interface. Every XPathNavigator over XPathDocument implements this interface and provides line number and line position for every node in a document. Here is a small sample: using System;
using System.Xml;
using System.Xml.XPath;
using System.Xml.Xsl;
public class Test
{
static void Main()
{
XPathDocument xdoc = new XPathDocument("books.xml");
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load("foo.xslt", XsltSettings.TrustedXslt,
new XmlUrlResolver());
xslt.Transform(xdoc, null, Console.Out);
}
}<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:ext="http://example.com/ext"
extension-element-prefixes="ext">
<ms:script implements-prefix="ext"
xmlns:ms="urn:schemas-microsoft-com:xslt" language="C#">
public int line(XPathNavigator node)
{
IXmlLineInfo lineInfo = node as IXmlLineInfo;
return lineInfo != null ? lineInfo.LineNumber : 0;
}
</ms:script>
<xsl:template match="/">
<foo>
<xsl:value-of select="ext:line(//book)">
</foo>
</xsl:template>
</xsl:stylesheet>
Ability to report line info is another reason to choose XPathDocument as a store for your XML (in read-only scenarios such as query or transformation) - in addition to better performance and smaller memory footprint.
If you really need the same, but with XmlDocument, you have to extend DOM.
I'm finally decided to switch web hosting. I'm currently on webhost4life, but I'm really not up to that "4life" part. It's getting slower and slower while people seem to be runnig away from them. So I'm looking for ASP.NET hosting recommendations. I need to host at least 3 domains with DotnetNuke, CommunityServer, MS SQL, MySQL, nothing special. I've heard both good and bad words about ASPNix, but what about HostingFest? Where do you host your Windows stuff? Update: problem totally solved, got hosting I couldn't even dream about. All like me mentally retarded Microsoft MVPs - subscribe to the private "3rd offers" newsgroup now, I mean NOW!
If you are up to Microsoft certification you might be interested in this new offer from Microsoft called Exam Insurance: Get two chances to pass your Microsoft Certification exam With Microsoft Exam Insurance, you can retake a Microsoft Certification exam if you need to. You'll have two chances to pass and validate your knowledge of critical IT job functions. Or, pass on your first try and save 25 percent on your next exam You'll receive a 25 percent discount on any future Microsoft Certification exam. With each additional Microsoft Certification that you earn, you'll be further along the path to getting the recognition you deserve. Really sounds like a win-win situation. The offer expires May 2007 and is available exclusively through Microsoft Certified Partners for Learning Solutions.
 W3C presented Planet Mobile Web site aggregating multiple blogs that discuss Mobile Web. It's hosted by the W3C Mobile Web Initiative. Really interesting reading. W3C presented Planet Mobile Web site aggregating multiple blogs that discuss Mobile Web. It's hosted by the W3C Mobile Web Initiative. Really interesting reading.  Subscribed. Subscribed.
I skimmed some posts and it looks like the million dollar question every mobile blogger now think about is "how the hell we can get AJAX work on the mobile???". Mobile Web 2.0 is another revolution still waiting to happen.
 Man is driven to create; I know I really love to create things. And while I’m not good at painting, drawing, or music, I can write software. I believe that the purpose of life is, at least in part, to be happy. Based on this belief, Ruby is designed to make programming not only easy, but also fun. It allows you to concentrate on the creative side of programming, with less stress. Yukihiro Matsumoto, inventor of Ruby I just started learning Ruby and I already feel it might be the language I love (well, after XSLT of course).
 W3C announced the Mobile Web Best Practices 1.0 as Proposed Recommendation: W3C announced the Mobile Web Best Practices 1.0 as Proposed Recommendation:
Written for designers of Web sites and content management systems, these guidelines describe how to author Web content that works well on mobile devices. Thirty organizations participating in the Mobile Web Initiative achieved consensus and encourage adoption and implementation of these guidelines to improve user experience and to achieve the goal of "one Web." Read about the Mobile Web Initiative. That's actually a very interesting document. It's definitely a must for anybody targeting Mobile Web, which is a very different from the Web we know and it's not only because of limitations: Mobile users typically have different interests to users of fixed or desktop devices. They are likely to have more immediate and goal-directed intentions than desktop Web users. Their intentions are often to find out specific pieces of information that are relevant to their context. An example of such a goal-directed application might be the user requiring specific information about schedules for a journey they are currently undertaking. Equally, mobile users are typically less interested in lengthy documents or in browsing. The ergonomics of the device are frequently unsuitable for reading lengthy documents, and users will often only access such information from mobile devices as a last resort, because more convenient access is not available. Still there is dream about "One Web": The recommendations in this document are intended to improve the experience of the Web on mobile devices. While the recommendations are not specifically addressed at the desktop browsing experience, it must be understood that they are made in the context of wishing to work towards "One Web". As discussed in the Scope document [Scope], One Web means making, as far as is reasonable, the same information and services available to users irrespective of the device they are using. However, it does not mean that exactly the same information is available in exactly the same representation across all devices. The context of mobile use, device capability variations, bandwidth issues and mobile network capabilities all affect the representation. Furthermore, some services and information are more suitable for and targeted at particular user contexts (see 5.1.1 Thematic Consistency of Resource Identified by a URI). Some services have a primarily mobile appeal (location based services, for example). Some have a primarily mobile appeal but have a complementary desktop aspect (for instance for complex configuration tasks). Still others have a primarily desktop appeal but a complementary mobile aspect (possibly for alerting). Finally there will remain some Web applications that have a primarily desktop appeal (lengthy reference material, rich images, for example). It is likely that application designers and service providers will wish to provide the best possible experience in the context in which their service has the most appeal. However, while services may be most appropriately experienced in one context or another, it is considered best practice to provide as reasonable experience as is possible given device limitations and not to exclude access from any particular class of device, except where this is necessary because of device limitations. From the perspective of this document this means that services should be available as some variant of HTML over HTTP. What about "Web 2.0"? Well, No support for client side scripting. I recently got Motorola RAZR V3X - cool 3G phone (btw 3G really rocks) and all of a sudden I'm all about Mobile Web. This is fascinating technology with huge future. I've got lots of plans that gonna make me millions... if I only had some more spare time :(
Remember that catchy RubyCLR motto? 
Now C# (Anders Hejlsberg) is playing catch up talking about automatic properties: public string Bar { get; set; }Above is meant to be translated by a compiler into private string foo;
public string Bar
{
get { return foo; }
set { foo = value; }
}
Now I'm not sure I like reusage of the abstract property notation, but still way to go guys.
Just one morning topics: Wikipedia Used To Spread Virus "The German Wikipedia has recently been used to launch a virus attack. Hackers posted a link to an all alleged fix for a new version of the blaster worm. Instead, it was a link to download malicious software. They then sent e-mails advising people to update their computers and directed them to the Wikipedia article. Since Wikipedia has been gaining more trust & credibility, I can see how this would work in some cases. The page has, of course, been fixed but this is nevertheless a valuable lesson for Wikipedia users." Wikipedia and Plagiarism Daniel Brandt found the examples of suspected plagiarism at Wikipedia using a program he created to run a few sentences from about 12,000 articles against Google Inc.'s search engine. He removed matches in which another site appeared to be copying from Wikipedia, rather than the other way around, and examples in which material is in the public domain and was properly attributed. Brandt ended with a list of 142 articles, which he brought to Wikipedia's attention.... 'They present it as an encyclopedia," Brandt said Friday. "They go around claiming it's almost as good as Britannica. They are trying to be mainstream respectable.'" Long-Term Wikipedia Vandalism Exposed "The accuracy of Wikipedia, the free online encyclopedia, came into question again when a long-standing article on 'NPA personality theory' was confirmed to be a hoax. Not only had the article survived at Wikipedia for the better part of a year, but it had even been listed as a 'Good Article,' supposedly placing it in the top 0.2-0.3% of all Wikipedia articles — despite being almost entirely written by the creator of the theory himself." Good thing is that once discoveded all problems were immediately cleared and offenders banned. Wikipedia is really fast on fixing problems. The concusion is of course - Wikipedia is a great free resource, but don't believe everything you read there.
When working with XPath be it in XSLT or C# or Javascript, apostrophes and quotes in string literals is the most annoying thing that drives people crazy. Classical example is selections like "foo[bar="Tom's BBQ"]. This one actually can be written correctly as source.selectNodes("foo[bar=\"Tom's BBQ\"]"), but what if your string is something crazy as A'B'C"D" ? XPath syntax doesn't allow such value to be used as a string literal altogether- it just can't be surrounded with neither apostrophes nor quotes. How do you eliminate such annoyances? The solution is simple: don't build XPath expressions concatenating strings. Use variables as you would do in any other language. Say no to selectNodes("foo[bar=\"Tom's BBQ\"]")
and say yes to selectNodes("foo[bar=$var]")
How do you implement this in .NET? System.Xml.XPath namespace provides all functionality you need in XPathExpression/IXsltContextVariable classes, but using them directly is pretty much cumbersome and too geeky for the majority of developers who just love SelectNodes() method for its simplicity.
The Mvp.Xml project comes to rescue providing XPathCache class: XPathCache.SelectSingleNode("//foo[bar=$var]",
doc, new XPathVariable("var", "A'B'C\"D\""))
And this is not only stunningly simple, but safe - remember XPath injection attacks?
You can download latest Mvp.Xml v2.0 drop at our new project homepage at the Codeplex.
 This is a great picture my wife took. It's Tel-Aviv beach view from a landing plane. Speaking of Tel-Aviv, we've got something unusual happenning here. There was a tornado near the beach and UFO over the city. Btw, I believe I've seen that tornado while driving to work via Tel-Aviv. This is a great picture my wife took. It's Tel-Aviv beach view from a landing plane. Speaking of Tel-Aviv, we've got something unusual happenning here. There was a tornado near the beach and UFO over the city. Btw, I believe I've seen that tornado while driving to work via Tel-Aviv.
  Remember this famous Mars face? So recently NASA found another one, here in the Earth, in Australia actually. They call it "Ghostly Face In South Australian Desert". I first though it's about upside-down face that reminds Dali paintings, but no. Can you see a ghost face here? That's really stupid, but still cool picture. Btw, if you are not yet subscribed to the NASA Earth Observatory you might want. They publish some really cool pictures every week. Remember this famous Mars face? So recently NASA found another one, here in the Earth, in Australia actually. They call it "Ghostly Face In South Australian Desert". I first though it's about upside-down face that reminds Dali paintings, but no. Can you see a ghost face here? That's really stupid, but still cool picture. Btw, if you are not yet subscribed to the NASA Earth Observatory you might want. They publish some really cool pictures every week.
|
|

{kind=link}
Recent Comments