March 12, 2005
MSDN upcoming webcasts RSS feed
VB6 is dead? Amen
March 10, 2005
How to speed up Muenchian grouping in .NET
Muenchian grouping includes a step of selecting unique nodes - first node for each group. Usually this is done using generate-id() or count() functions. There is another way to select nodes with unique value though - EXSLT's set:distinct() function, supported by EXSLT.NET. So I measured performance and scalability of all three methods.
The source XML is XML dump of the Orders database from the Northwind sample database, including 415 orders:
<root> <orders OrderID="10249" CustomerID="TOMSP" EmployeeID="6" OrderDate="1996-07-05T00:00:00" RequiredDate="1996-08-16T00:00:00" ShippedDate="1996-07-10T00:00:00" ShipVia="1" Freight="11.61" ShipName="Toms Spezialitten" ShipAddress="Luisenstr. 48" ShipCity="Munster" ShipPostalCode="44087" ShipCountry="Germany" /> <!-- 414 more orders --> </root>To unveil scalability issues I created bigger documents by multiplying number of orders by 2 (while keeping OrderID uniquness), so I got documents with 415, 830, 1660, 3320, 6640 and 13280 orders (from 135 Kb to 4.5 Mb). The task is to group orders by ShipCountry value. Here is the first stylesheet (classical Muenchian grouping with generate-id()):
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output indent="yes"/>
<xsl:key name="countryKey" match="orders" use="@ShipCountry"/>
<xsl:template match="root">
<table border="1">
<tr>
<th>Order ID</th>
<th>Ship City</th>
</tr>
<xsl:for-each select="
orders[generate-id()=generate-id(key('countryKey', @ShipCountry)[1])]">
<tr>
<th colspan="2">
<xsl:value-of select="@ShipCountry"/>
</th>
</tr>
<xsl:for-each select="key('countryKey',@ShipCountry)">
<tr>
<td>
<xsl:value-of select="@OrderID"/>
</td>
<td>
<xsl:value-of select="@ShipCity"/>
</td>
</tr>
</xsl:for-each>
</xsl:for-each>
</table>
</xsl:template>
</xsl:stylesheet>
Pretty trivial. Second version uses count() function instead of generate-id(), here is the relevant part:
<xsl:for-each select="
orders[count(.| key('countryKey', @ShipCountry)[1]) = 1]">
And third version uses set:distinct() function:
<xsl:for-each select="set:distinct(orders/@ShipCountry)/.." xmlns:set="http://exslt.org/sets">Here are the results I got when running all three stylesheets with above 6 XML documents on my ancient Dell workstation (P3 600MHz) using nxslt.exe:
| Grouping technique | Transformation time (ms) | |||||
|---|---|---|---|---|---|---|
| XML document size (number of orders to group) | ||||||
| 415 | 830 | 1660 | 3320 | 6640 | 13280 | |
| Muenchian Grouping (with generate-id()) | 151.722 | 407.619 | 1318.676 | 5290.962 | 27773.98 | 130860.1 |
| Muenchian Grouping (with count()) | 97.238 | 190.086 | 462.075 | 1401.199 | 4193.143 | 14015.86 |
| Muenchian Grouping (with (set:distinct()) | 94.499 | 155.035 | 276.465 | 687.494 | 1104.554 | 2503.871 |
The graph view works better:
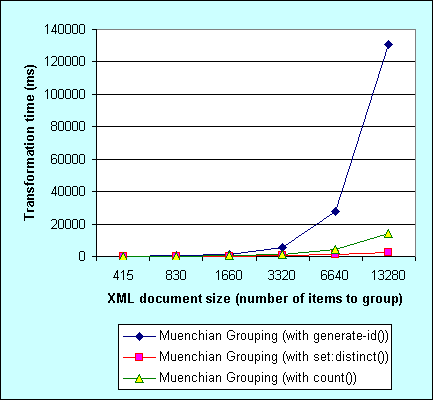
As can be seen, in .NET 1.1, Muenchian grouping using generate-id() is not only the slowest, but shows the worst scalability. Probably the reason is poor generate-id() function implementation. count() function performs much better, but still shows some scalability issues. And finally Muenchian grouping using set:distinct() function is the winner here - both in speed and good scalability. Sublinear running time, amazing. Kudos to Dimitre Novatchev for optimizing set:distinct() function implmentation in EXSLT.NET.
The bottom line - if you are looking for ways to speed up grouping in XSLT under .NET 1.X, use Muenchian grouping with set:distinct() function from EXSLT.NET to get the best perf and scalability. Otherwise use Muenchian grouping with count() function, which sucks less in .NET than generate-id() function does.
I wonder what would be results in .NET 2.0? Stay tuned guys.