February 28, 2007
Visual Studio Code Name "Orcas" March 2007 CTP is here
 Hot, hot, hot! Microsoft Pre-release Software Visual Studio Code Name "Orcas" - March 2007 Community Technology Preview (CTP) is available for download.
Hot, hot, hot! Microsoft Pre-release Software Visual Studio Code Name "Orcas" - March 2007 Community Technology Preview (CTP) is available for download.
This is the first mostly feature complete Visual Studio v.next version (Visual Studio 2007 I bet).
6Gb download, so before click on the link take a look at what's new and decide if you need it. It's Pre-release and Community Technology Preview too. Anyway here are some highlights:
- LINQ
The LINQ Project: this CTP represents a major milestone in the LINQ project. For more information about LINQ click here.- VB 9.0 Language Support: This CTP contains the following language features:
- Query Expressions: Basic querying, filtering, and ordering support
- Object Initializers
- Extension Methods
- Local Variable Type Inference
- Anonymous Types
- XML literals
- XML properties
- New Line and Expression IntelliSense
- C# 3.0 Language Support: This CTP implements all of the C#3.0 language features from the May LINQ CTP including:
- Query Expressions
- Object and Collection Initializers
- Extension Methods
- Local Variable Type Inference and Anonymous Types
- Lambdas bound to Delegates and Expression trees
- Complete design-time support: Intellisense, Formatting, Colorization
- LINQ to ADO.NET
- ADO.NET is fully integrated with LINQ and offers many options for using LINQ in various scenarios: LINQ to SQL provides direct access to database tables from the programming environment, LINQ to Entities enables developers to use LINQ over EDM models, and LINQ to DataSet allows the full expressivity of LINQ to be used over DataSets.
- LINQ to Entities enables developers to program against a relational database using a view of the data that is appropriate for the application they are building, independent of the structure of the underlying database. The use of the Entity Data Model (EDM) enables developers to design models that follow the concepts built into the application, instead of having to map them to constructs available in relational stores. LINQ to Entities is built on the ADO.NET Provider model and will support working against different back end relational stores in addition to Microsoft SQL Server. This CTP includes a LINQ to Entities provider for SQL Server and SQL Server Compact Edition.
- LINQ to SQL (previous name DLinq) has enhanced the functionality from the May 2006 LINQ CTP. You can find it in System.Data.Linq namespace in System.Data.Linq.dll. New in this release is that DataContext provides optimized modes for read-only use and serialization . Also new is that DataShape streamlines eager loading capabilities and adds the ability to set queries on relationships
- LINQ To SQL Designer
- Methods can be created from stored procedures and functions within the designer.
- Better handling of database schemas.
- Improved inheritance support in the designer.
- LINQ over XML (XLinq)
- System.Xml Bridge Classes added – There is a set of extension methods allowing XPath / XSLT to be used over LINQ to XML trees, allow XSLT transformations to produce an LINQ to XML tree, and to validate an XElement tree against an XML Schema.
- Event Model - This allows LINQ to XML trees to be efficiently synchronized with a GUI, e.g. a Windows Presentation Foundation application
- Class hierarchy changes - XObject class added, XStreamingElement class (temporarily) removed
- Various understandability / usability improvements – There have been a number of relatively minor changes done in response to internal reviews, usability studies, and external feedback to make the API more clean and consistent.
- LINQ to Objects API
- The LINQ to Objects API supports queries over any .NET collection, such as arrays and Generic Lists. This API is defined in the System.Linq namespaces inside System.Core.dll.
- VB 9.0 Language Support: This CTP contains the following language features:
- ADO.NET
- Extended, more powerful data APIs with the ADO.NET Entity Framework
- With the ADO.NET Entity Framework developers will be able to model the view of the data that is appropriate for each one of the applications they are building, independently of the structure of the data in the underlying database. The use of the Entity Data Model (EDM) enables developers to design models that follow the concepts built into the application, instead of having to map them to constructs available in relational stores. Once the model is in place, the powerful ADO.NET Entity Framework API is used to access and manipulate the data as .NET classes or as rows and columns, whatever is appropriate for each application.
- Added paging and stored procedures for update (“update customization”) for ADO.NET Entity Framework:
- Paging: the paging support in the ADO.NET Entity Framework allows developers to “page” over data in a database by indicating the start row and number of rows to be included in the result. Paging is available through Entity SQL (using the LIMIT AND SKIP keywords) and through the query-builder methods in the ObjectQuery <T> class (Top and Skip). In a future CTP the feature will also be enabled to be used in LINQ queries by means of the standard Take and Skip LINQ operators.
- Stored-procedures for update customization: the Entity Framework by default automatically generates SQL statements for insert, update and delete operations when processing changes to entities in memory to be sent to the database. With the stored-procedures update customization feature developers have the option to override the automatic SQL generation and instead provide stored-procedures that will perform the insert, update and delete operations, which the system will call during entity change processing. Among other things, this enables scenarios where direct access to tables is restricted in the database and the only way to make changes to the data is through stored-procedures.
- Microsoft Synchronization Services for ADO.NET
- Provides an application programming interface (API) to synchronize data between data services and a local store. The Synchronization Services API is modeled after the ADO.NET data access APIs and gives you an intuitive way to synchronize data. It makes building applications for occasionally connected environments a logical extension of building applications where you can depend on a consistent network connection. For details please visit http://go.microsoft.com/fwlink/?LinkId=80742 .
- Extended, more powerful data APIs with the ADO.NET Entity Framework
- Web
- Improvements for web development in this CTP include:
- New ASP.NET WebForms design-surface with advanced XHTML and CSS features
- JScript intellisense for ASP.NET AJAX and browser DOM
- Multi-targetting for .NET Framework 2.0, 3.0, and 3.5 in websites and web applications
- LINQ to SQL designer integration in websites and web applications
- Improvements for web development in this CTP include:
- Client App-Level Services
- Enable client application developers to use the same user profile and login services as your Web applications. This enables customers to utilize on set of backend storage for user personalization and authentication regardless of the applications type.
- C# Workflow Rules
- Workflow Rules allows users to enter rules (and conditions) in a code-like manner
- Support the use of the new C# Extension methods features in their rules
- Enable operator overloading and the new operators in their rules
- Workflow Rules allows users to enter rules (and conditions) in a code-like manner
- XML
- XML Tools: XSLT Debugger
- Enables Input Data Breakpoints allowing the user to break the execution of the style-sheet whenever a certain node in input document is hit.
- XML Editor Performance Improvements
- Performance in the Xml Editor for Intellisense, schema validation etc is improved by implementing incremental parsing of the XML Document.
- Seamless transition between XML Editor and XSD Designer
- Improves the experience a user has when working with an XML Schema in textual and graphical mode at the same time.
- XML Tools: XSLT Debugger
- MSBuild
- Parallel/Multi-Processor Builds
- Building multiple projects in parallel, as much as possible based on the use of dependency information in projects to parallelize
- Allowing the developer/builder to control the parallelism by providing them the ability to specify the number of processors to use for build.
- Parallel/Multi-Processor Builds
- UAC Manifests in the Managed Build Process
- Support for manifests that are embedded into the final executable via the Build process.
- IDE
- Windows Presentation Foundation (WPF) Designer (“Cider”) & Application Tools to deliver the ability to:
- Create, edit, build, run and debug WPF projects
- Use the WPF Designer to:
- Preview any XAML in the designer including user defined controls and types
- Design Windows, Pages and UserControls
- Do basic layout tasks in a Grid
- Do basic property editing using the new property browser
- Easily understand and navigate “document structure” using the Document Outli
- See changes in the designer immediately in the XAML
- Use the XAML Editor to:
- Edit XAML with intellisense
- See changes in the XAML immediately in the designer
- Build design time for WPF controls
- UAC manifests in the IDE for Windows Vista applications
- Enable developers on Windows Vista to easily include the UAC manifest as an embedded resource.
- Windows Presentation Foundation (WPF) Designer (“Cider”) & Application Tools to deliver the ability to:
- CLR
- Add IRI support (RFC 3987) to URI related classes
- This allows resource identifiers to be specified using a character set that supports all languages.
- New Async model on Socket class
- A new Async model is reduces the per I/O overhead compared to the current I/O model
- Peer Networking Classes
- Delivers a set of peer-to-peer network APIs that allow a developer to easily extend an application with compelling collaboration functionality.
- WMI.NET Provider Extension 2.0
- WMI.NET Provider Extension 2.0 simplifies and enhances the development of WMI providers in the .Net framework to enable the management of the .NET applications while minimizing the impact on the development time.
- Delivers equivalent access to WMI features and functions available to native code providers.
- Exposes property updates and methods to managed code.
- Improved scalability for large collections of WMI entities.
- WMI.NET Provider Extension 2.0 simplifies and enhances the development of WMI providers in the .Net framework to enable the management of the .NET applications while minimizing the impact on the development time.
- Add IRI support (RFC 3987) to URI related classes
- Office
- Enable ClickOnce deployment for Microsoft Office applications
- Developers now have an easy to use and version resilient security model for their applications that will exist for future versions of Visual Studio and Office. With full support for ClickOnce deployment of all Office 2007 customizations and applications, developers and administrators now have the right tools and framework for easy deployment and maintenance of their Office solutions.
- Team Architect
- Top-down service design
- Top-down system design allows an application architect/lead developer to perform the design of a business solution without having to be confronted with technology decisions. It enables the user to progressively refine a high-level system design, designing new sub-systems and applications in the context of the system in which they are to be used.
- Architectural Roles on System, Applications and Endpoints
- Enables an architect, while working on the high-level design of a system’s architecture using the System Designer, to introduce elements into the design that play a specific pre-defined architectural role(s) within architectural patterns.
- Top-down service design
- Team Developer
- Profiler Support for WCF Applications
- Enable profiling of WCF based applications to improve application performance
- Customize and extend code correctness policies
- Code Analysis Check-in Policy improvements to communicate to a developer why the check-in policy failed and to provide guidance on how to pass the policy requirements.
- Customize and extend code correctness policies
- Code Analysis Check-in Policy improvements to communicate to a developer why the check-in policy failed and to provide guidance on how to pass the policy requirements.
- Performance tune an enterprise application
- Enables developers to run profiling during load and test procedures for a system, to see how it behaves, and use integrated tools to profile, debug and tune. This also enables performance base-lining, so that users can save a baseline profile and then, if the performance degrades, compare up-to-date traces to identify the source of the regression
- Profiler Support for WCF Applications
- Team Test
- Unit Test Generation Improvements
- Improvements to unit test generation provide an easy way for the user to specify what methods to test, and generate test methods and helper code to do unit testing, as well as providing unit test support for generics.
- Web Test Validation Rule Improvements
- Web Test rules improvements enable testers to create more comprehensive validation rules for the application being tested. These improvements include the following functions:
- Stop test on error
- Search request and response
- Add validation rule for title
- Redirect validation
- Provide test level validation rules
- Expected HTTP code
- Warning level for errors on dependents
- Web Test rules improvements enable testers to create more comprehensive validation rules for the application being tested. These improvements include the following functions:
- Better Web Test Data Binding
- This feature allows users to data bind .CSV and XML files, as well as databases to a web test, using a simple databinding wizard.
- Improved Load Test Results Management
- With this feature user can open or remove an existing load test result from the load test repository. User can also import and export load test results files.
- Unit Test Generation Improvements
- Team Foundation Server
- Team Build
- Support multi-threaded builds with the new MSBuild.
- Continuous Integration – There are many components to this, including build queuing and queue management, drop management (so that users can set policies for when builds should be automatically deleted), and build triggers that allows configuration of exactly how when CI builds should be triggered, for example – every checkin, rolling build (completion of one build starts the next), etc.
- Improved ability to specify what source, versions of source, etc to include in a build.
- Improved ability to manage multiple build machines.
- Simplified ability to specify what tests get run as part of a build
- Version Control support
- Destroy- The version control destroy operation provides administrators with the ability to remove files and folders from the version control system. The destroyed files and folders cannot be recovered once they are destroyed. Destroy allows administrators to achieve SQL server disk space usage goals without constantly needing to add more disks to the data tier machine. Destroy also facilitates removing versioned file contents that must be permanently removed from the system for any other reason.
- Annotate - Annotate is a feature that allows developers to inspect a source code file and see at line-by-line level of detail who last changed each section of code. It brings together changeset data with difference technology to enable developers to quickly learn change history inside a source file.
- Folder Diff - Team Foundation Server now supports compare operations on folders, whereby the contents of the folder are recursively compared to identify files that differ. Folder diff can compare local folders to local folders, local folders to server folders, and server folders to server folders. It’s a great way of identifying differences between branches, files that you’ve changed locally, and files that have changed between two points in time.
- Get Latest on Checkout - As an optional setting on a team project or on an individual basis, you can have Team Foundation Server always download the latest version of a file when you check it out. This helps ensure that you don’t have to merge your changes with somebody else’s when you check the file back in.
- Performance and Scale
- This release includes numerous improvements in performance and scalability of Team Foundation Server.
- Team Build
- Visual C++
- Easily add the Windows Vista “Look and Feel” to native C++ applications
- Developers can use Visual Studio to build ISV applications that exhibit the Windows Vista “look & feel”. A number of the Windows Vista “look & feel” features are available simply by recompiling an MFC application. Deeper integration that requires more coding or design work on the part of the developer is also simplified with Visual Studio’s integrated support for the Windows Vista native APIs.
- Easily add the Windows Vista “Look and Feel” to native C++ applications
February 22, 2007
Google Launches Apps Premier Edition
 Google launches Premier Edition of the google.com/a - Google Apps. It's:
Google launches Premier Edition of the google.com/a - Google Apps. It's:
- Gmail (10Gb mailbox), Google Talk, Google Calendar, Docs & Spreadsheets, Page Creator and Start Page
- 99.9% uptime guarantee for email (only for email?)
- opt-out for ads in email - doh!
- Shared calendar
- Single sign-on
- User provisioning and management
- Support for email gateway
- Email migration tools (Limited Release)
- 24/7 assistance, including phone support
- 3rd party applications and services
for mere $50/year per user. Sounds tempting for microISVs and small businesses.
They say it's cheap alternative to Microsoft Office. I'm not convinced. $50 x 4-5 years = Microsoft Office price, but I'm not sure one can compare Google Apps and Microsoft Office featurewise (yet).
What's more interesting is /. gang very cold reaction. Are sysadmins afraid Google is taking their job off?
65 free online math books
Here is a list of 65 Math books available online for free, compiled by George Cain of Georgia Institute of Technology. Including really interesting ones such as:
- Algorithms and Complexity by Professor Wilf
- A = B, by Marko Petkovsek, Herbert Wilf, and Doron Zeilberger
- A Course In Algebraic Number Theory by Professor Ash
- Calculus Without Limits, by John C. Sparks
- Handbook of Applied Cryptography, by Alfred J. Menezes , Paul C. van Oorschot, and Scott A. Vanstone
- Graph Theory, by Reinhard Diestel
- Basic Concepts of Mathematics, by Elias Zakon
- An Introduction to the Theory of Numbers by Leo Moser
- Graph Theory with Applications, by J. A. Bondy and U. S. R. Murty
- Information Theory, Inference, and Learning Algorithms, by David J. C. MacKay
- Voting, Arbitration, and Fair Division: The Mathematics of Social Choice by Professor Pivato
- Numerical Methods and Analysis for Engineers, by Douglas Wilhelm Harder
[Via reddit.com: programming]
February 21, 2007
R.I.P. GotDotNet
![]() Microsoft decided to shut down GotDotNet site by July 2007. The official announcement goes like this:
Microsoft decided to shut down GotDotNet site by July 2007. The official announcement goes like this:
Microsoft will be phasing out the GotDotNet site by July 2007.
Microsoft will phase out all GotDotNet functionality by July 2007. We will phase out features according to the schedule below. During the phase-out we will ensure that requests for features or pages that are no longer available will render enough information for you to understand what has changed. If you have any questions please don’t hesitate to contact the GotDotNet Support team.
We are phasing out GotDotNet for the following reasons:Microsoft wants to eliminate redundant functionality between GotDotNet and other community resources provided by Microsoft Traffic and usage of GotDotNet features has significantly decreased over the last six months Microsoft wants to reinvest the resources currently used for GotDotNet in new and better community features for our customers
If you still hosting anything at the GotDotNet - here is your moving deadlines:
Phase Out Schedule
The GotDotNet phase out will be carried out in phases according the following timetable:Target Date
Areas to be ClosedFebruary 20
Partners, Resource Center, Microsoft ToolsMarch 20
Private workspaces, Team pages, Message BoardsApril 24
GDN CodeGallery (projected date)May 22
GDN User Samples (projected date)June 19
GDN Workspaces (projected date)
Well, obviously that was inevitable. GotDotNet sucked big despite any efforts made. Looks like Microsoft was learning how to do open source project hosting on the web and GotDotNet was first that first pancake that is always spoiled. CodePlex definitely tastes better.
There are couple of projects still hosted at the GotDotNet that I care about:
- Chris Lovett's SgmlReader. Awesome tool for reading HTML via XmlReader. I suggested Chris to contribute SgmlReader to the Mvp.Xml project, let's see if he likes the idea.
- XPathReader. Cool pull-based streaming XML parser supporting XPath queries. I'm admin there actually, so I think we are going to move XPathReader under the Mvp.Xml project umbrella real soon.
Well, the GotDotNet is dead. Long live CodePlex!
February 17, 2007
Weekend photos
We spent half of today in the "Leumi" park of Ramat-Gan. The weather was just wonderful lovely. Here are some photos to let you feel Israel winter:






Google Reader reports subscriber counts
According to the Official Google Reader Blog Google feed crawler, Feedfetcher, started to report subscriber counts. "The count includes subscribers from Google Reader and the Google Personalized Homepage, and in the future may include other Google products that support feeds."
What I found it interesting is that they do it via User Agent string. That's a very simple and nice solution and it's apparently not something new as I just looked at my blog log file and found subscribers info from a variety of feed crawlers:
GET /blog/index.xml - x.x.x.x HTTP/1.1 Bloglines/3.1+(http://www.bloglines.com;+154+subscribers) GET /blog/index.xml - x.x.x.x HTTP/1.1 NewsGatorOnline/2.0+(http://www.newsgator.com;+99+subscribers) GET /blog/index.xml - x.x.x.x HTTP/1.1 Feedfetcher-Google;+(+http://www.google.com/feedfetcher.html; +167+subscribers;+feed-id=xxxxxxx) GET /blog/index.xml - x.x.x.x HTTP/1.1 Newshutch/1.0+(http://newshutch.com;+12+subscribers)
And even such funny user agent as
GET /blog/index.xml - x.x.x.x HTTP/1.1 Mozilla/5.0+(X11;+U;+Linux+i686;+en-US;+rv:1.2.1; +Rojo+1.0;+http://www.rojo.com/corporate/help/agg/; +Aggregating+on+behalf+of+15+subscriber(s)+online+at+http://www.rojo.com/?feed-id=xxx)+Gecko/20021130
One might claim that's user agent header abuse, but I don't think so. Here is what RFC 2616 (HTTP) has to say:
14.43 User-Agent
The User-Agent request-header field contains information about the user agent originating the request. This is for statistical purposes, the tracing of protocol violations, and automated recognition of user agents for the sake of tailoring responses to avoid particular user agent limitations. User agents SHOULD include this field with requests. The field can contain multiple product tokens (section 3.8) and comments identifying the agent and any subproducts which form a significant part of the user agent. By convention, the product tokens are listed in order of their significance for identifying the application.
Statistical purposes that's it.
Oh, and while at it I should admit I hooked up to the Google Reader completely and haven't run RSS Bandit for months now. RSS Bandit has tons of cool features, but I always knew I need lightweight Web based feed reader. I tried Bloglines repeatedly, but only with Google Reader I found myself really comfortable from the first minute. That's great application.
February 15, 2007
Ruby On Rails Hosting You Cannot Resist
I was looking for Ruby on Rails hosting and found this amazing offer from DreamHost. This is just unbelievable. Consider this:
- Disk Storage at signup - 178.5 GB, automatically increases weekly by 1 GB
- Monthly Bandwidth at signup - 1.785 TB, automatically increases weekly by 16 GB
- MySQL Databases: unlimited
- E-Mail Accounts (POP/IMAP) - 3,000
- 1 free domain name
- Domains Hosted - unlimited
- Full Unix Shell
- Ruby On Rails
- CVS Repository
- Subversion Repository (SVN)
- SSH access
- WebDAV, Frontpage, Streaming
- 97-day money-back guarantee
- Host reliably with 18th-ranked web host in the world (442,285 domains hosted).
- More and more and more...
These guys are like gmail in web hosting - they talk hundreds gigabytes of space and terabytes of bandwidth.
And for this "oh my freaking God" hosting plan they want $9.95/mo only (or even $7.95 if you subscribe for 2 years). But wait, google for "Dreamhost" and you can find promo codes like "mddr" or "FLY", which give you $97 discount for the first year.
Bottom line - you have to pay only $22.40 for the whole first year.
Cool. I want this. Fuck Windows hosting, go Linux and Ruby :)
Where is the catch, anybody?
Update. Ok, here comes the tricky part. "DreamHost Web Hosting does not accept payments from Israel". Really weird. What's wrong with payments from Israel? Oh well, happily I have US card too.
February 14, 2007
XML Inclusions reversal or transclusions strike back
Kzu, being also one of the Mvp.Xml project users has this wild feature request. He wants to reverse XInclude resolving back. The scenario is simple: you load XML document A.xml containing XML Inclusions for B.xml and C.xml, XInclude processor resolves XML Inclusions, you get a combined document, edit it and then you save it back to A.xml, B.xml and C.xml. So if you have modified an element coming from B.xml then B.xml gets updated on save.
Well, that sounds like a reasonable feature, but how it can be done? To be able to reverse XML Inclusions one has to know exactly where each node came from, i.e. to preserve original context in a post-XInclude document.
Inclusion preserving context information is also known as a transclusion. Visual transclusion is traditionally associated with XLink instead and technically speaking XInclude has nothing to do with it. From XInclude 1.0 spec:
1.1 Relationship to XLink
XInclude differs from the linking features described in the [XML Linking Language], specifically links with the attribute value
show="embed". Such links provide a media-type independent syntax for indicating that a resource is to be embedded graphically within the display of the document. XLink does not specify a specific processing model, but simply facilitates the detection of links and recognition of associated metadata by a higher level application.XInclude, on the other hand, specifies a media-type specific (XML into XML) transformation. It defines a specific processing model for merging information sets. XInclude processing occurs at a low level, often by a generic XInclude processor which makes the resulting information set available to higher level applications.
Simple information item inclusion as described in this specification differs from transclusion, which preserves contextual information such as style.
So in an ideal world I'd just suggest Kzu to use XLink instead of XInclude for transclusions. The problem though is that XLink is basically dead for years now and unfortunately there is none XLink implementations for .NET. That's why XInclude.
As I read XInclude spec more I realized above citation about XInclude != transclusion isn't 100% true and XInlcude does preserve some pieces of context:
The inclusion history of each top-level included item is recorded in the extension property include history. The include history property is a list of element information items, representing the
xi:includeelements for recursive levels of inclusion. If an include history property already appears on a top-level included item, thexi:includeelement information item is prepended to the list. If no include history property exists, then this property is added with the single value of thexi:includeelement information item.
So basically for each node in a post-XInclude document it's possible to figure out it's original context:
- If a node has no ancestors having "include history" property, it belongs to the including XML document.
- If there is such ancestor node then "include history" can be used to find out where this node came from.
Of course that only sounds simple. For starters Mvp.Xml XInclude implementation doesn't support "include history". XIncludingReader keeps internal stack of xi:include elements though and can expose it in some way. Then "include history" should be preserved in XML Infoset implementation, e.g. XML DOM - XmlDocument. That means XIncludeXmlDocument class extending XmlDocument. And then "include history" should be used when saving XmlDocument. Still sounds feasible.
Problems. What about partial inclusions with XPointer? if a node was included from inside a document its full XPath must be preserved in "include history" so it can be saved back at exactly the same location. Still feasible.
Editing combined document opens Pandora's box. New nodes - where they should be saved. Deleting nodes - how to detect? Moving nodes around. Multiple inclusions of the same node - how to resolve conflicts?
Well, still it sounds mostly feasible to implement transclusion on top of XInclude.
Any comments? Does anybody think it might be useful?
February 13, 2007
XForms.org launched
Kurt Cagle launched XForms.org - The XForms Community Forum as well as XForms.org News Portal and XForms_Dev mailing list.
Welcome to the new XForms.org Community Web Portal, a central clearinghouse for articles and resources on XForms based technologies. This site is intended as one gateway into the XForms community (the other primary one being http://www.xforms.org itself), and provides the static side of the XForms.org community.
February 12, 2007
Ruby One-Click Installer - Ruby starter kit
![]() If you were thinking about learning Ruby - this is what you need to get started smoothly. Just released One-Click Ruby Installer 1.8.5-22 Final for Windows is "A self-contained installer that includes the Ruby language, dozens of popular extensions, a syntax-highlighting editor and the book "Programming Ruby: The Pragmatic Programmer's Guide".
If you were thinking about learning Ruby - this is what you need to get started smoothly. Just released One-Click Ruby Installer 1.8.5-22 Final for Windows is "A self-contained installer that includes the Ruby language, dozens of popular extensions, a syntax-highlighting editor and the book "Programming Ruby: The Pragmatic Programmer's Guide".
You would also need FreeRIDE - free full-blown Ruby IDE, written of course in Ruby.
So you get full Ruby runtime, decent IDE and a book - what else do you need? Go for it.
February 11, 2007
OpenXmlWriter - open source OpenXml text editor
openxml.biz announced the availability of the OpenXML Writer - open source text editor for creating OpenXML WordprocessingML files (.docx). Supported features include "text formatting options like bold, italic, underline, font color, font name , font size, paragraph justification and text indentation. Basic editing functions like cutting, copying, pasting and spell check are also provided".
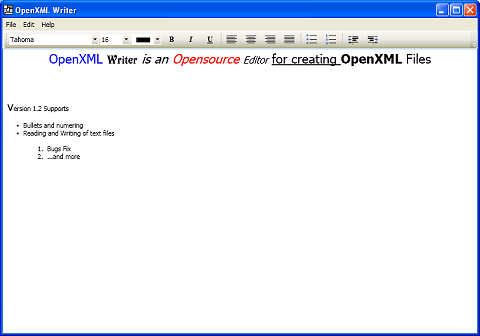 OpenXMLWriter is .NET 3.0 application, so you might need to install "Microsoft(TM) .NET Framework 3.0 Redistributable Package (For Win XP/2K users)" in order to run it.
OpenXMLWriter is .NET 3.0 application, so you might need to install "Microsoft(TM) .NET Framework 3.0 Redistributable Package (For Win XP/2K users)" in order to run it.
It's not immediatelyt clear for me if this application is just a sample from some microsoftie or free component from one of C# hackers. The site is basically empty and I have no idea who is behind this.
Anyway the idea sounds interesting:
OpenXML Writer is a .Net 3 project that shows how you can create .docx (OpenXML WordProcessingML) documents with the RichTextBox. The RichTextBox exposes a wide range of features that are easily tapped to create a fairly powerful editor. For example, you can turn on the spell check feature in the RichTextBox by simply setting a property.
OpenXML Writer works by transversing the contents of the RichTextBox and converting each of the elements into OpenXML format. It also package the relevant resources into a .docx file based on the OpenPackaging Convention.
OpenXML Writer has the potential to turn into a full fledge editor in the near future by taking advantage of the many features that the RichTextBox itself supports. Already, many features are being planned, such as the support for lists, images and tables in OpenXML Writer.
The source code for OpenXML Writer is available for download. It illustrates the techniques of
- Using the RichTextBox as the editor to format text data
- Traversing the contents of the RichTextBox and converting them into OpenXML format
- Packaging the contents using the OpenPackaging Convention into a .docx file
Web-based OpenXML editor would be even cooler.
February 8, 2007
Microsoft-free Daily Grind
If you like the "Daily Grind" by Mike Gunderloy you might like its Microsoft-free version "Quick Links" at the "A fresh Cup" site ("Notes from a recovering Microsoft addict") too. Worth subscribing anyway.
AdSense Watch Toolbar v1.0
If you were using my little AdSense Watch Toolbar 1.0b version and it expired, I'm sorry about that, go and download new version 1.0, which has no time limitation.

After 6 months in beta I can say AdSense Watch proved to be pretty stable, which is kinda unusual for screenscraping applications. Google used to change AdSense site once in a months or two, breaking various AdSense tools, but this toolbar kept working just fine. I never had to fix it because of Google site changes. That's because AdSense Watch is only using screenscraping technique for logging in, the AdSense data itself is fetched as CSV in English, which happens to be stable enough.
So if you are AdSense addict, that's for you. And it's free. Feature requests are welcome.
February 6, 2007
Generating XML entity references (&foo;) with XSLT: XSLT 2.0 to the rescue
Here is a problem: XSLT 1.0 sucks on generating XML character or entity references. I mean getting &foo; out of XSLT 1.0 is hard. The only ugly solution is disable-output-escaping hack, but it's a) optional, b)doesn't work in all scenarios (only when XSLT engine controls output serialization into bytes and c) works only on text nodes. Latter is real showstopper - you can't generate character or entity reference in attribute using XSLT 1.0. But now that we have XSLT 2.0, which is oh so better. What's XSLT 2.0 solution for the problem?
In XSLT 2.0 disable-output-escaping is deprecated. New facility for the problem is called Character Maps. Character maps are simpler, better and don't mess with data model. Formal definition:
A character map allows a specific character appearing in a text or attribute node in the final result tree to be substituted by a specified string of characters during serialization. The effect of character maps is defined in [XSLT and XQuery Serialization].
This is basically declarative replace for XSLT output.
Let's say you want to generate this XUL fragment (real world question):
<menuitem label="&context.add.building;"/>
XSLT 2.0 solution would be to define a character map, which maps ampersand character to ugh... ampersand character :) For this to make sense you should realize that mapping a character effectively disables its XML or HTML escaping. It's like you say "I want this character to be outputted as this string and don't mess with it you, the engine". That's powerful enough even to disable escaping of reserved characters such as & and <.
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0">
<xsl:output use-character-maps="xul" />
<xsl:character-map name="xul">
<xsl:output-character character="&" string='&'/>
</xsl:character-map>
<xsl:template match="contextMenu">
<menuitem label="&context.add.{name()}"/>
</xsl:template>
</xsl:stylesheet>
Awesome. I can't wait, I want this in XSLT 1.0 too. I think I'm going to implement character maps for nxslt.exe tool. The only problem is how to provide mapping info. I'll post about it next time.
[Tested with Saxon 8.8B for .NET].
Googlomania
Google somehow seems to be inaccessible (down?) from my place for at least 15 minutes now and I already feel uncomfortable if not desperate. I want my mail, news and search back! Seriously, WTF? How come can I be so dependent on google? Ok, great, who else does search on the Web?
Why XML
Everybody who speaks English can communicate with anybody else who also happens to speak English. You can talk, you can mail, you can read books written in English by others.
Sure you can invent your own language, no big deal. You can even make somebody learn it and then talk to her.
But most prefer easy way and speak XML, I mean English.
[Well, technically speaking majority on this planet prefer Chinese anyway].
February 5, 2007
Expandable archive list for MovableType
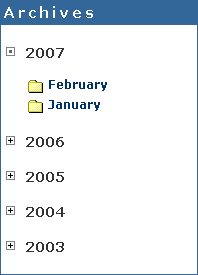 I'm blogging since March 2003 and as time goes I noticed my blog archive list became way too long and ugly. Finally I figured out how to generate it in a nice expandable list form you can see on the right. Here is a my small how to for MovableType powered blog. It's a little bit hacky, but works fine.
I'm blogging since March 2003 and as time goes I noticed my blog archive list became way too long and ugly. Finally I figured out how to generate it in a nice expandable list form you can see on the right. Here is a my small how to for MovableType powered blog. It's a little bit hacky, but works fine.
1. Install Archive Date Header Plugin from Adam Kalsey. This allows to generate year headers.
2. Insert this piece of Javascript somewhere - if you have common js file that would be the best, but at worse just paste it before </head> in your template. It's a function to handle expand/collapse year clicks.
<script type="text/javascript">
function ec(e) {
var targ;
if (e.target) targ = e.target;
else if (e.srcElement) targ = e.srcElement;
if (targ) {
rows = targ.parentNode.getElementsByTagName("DIV");
collapsed= targ.className == "year-hdr collapsed";
targ.className = collapsed? "year-hdr expanded" : "year-hdr collapsed";
for(i=0; i < rows.length; i++)
rows[i].style.display = collapsed? "block" : "none";
}
}
</script>
3. Use the following snippet in your template to generate expandable archive list. It generates nested list of archives with year headers.
<div class="side">
<div>
<MTArchiveList archive_type="Monthly">
<MTArchiveDateHeader>
</div><div>
<p class="year-hdr collapsed"
onclick="ec(event)"
id="archive<MTArchiveDate format="%Y">">
<MTArchiveDate format="%Y">
<p>
</MTArchiveDateHeader>
<div class="month-row">
<img src="images/folder.gif" align="middle"/> <a
href="<$MTArchiveLink$>"><MTArchiveDate format="%B"></a>
</div>
</MTArchiveList>
</div>
</div>
4. If you prefer the current year to be expanded by default, insert this piece of javascript after above template:
<script type="text/javascript">
year = document.getElementById("archive" + (new Date()).getFullYear());
if (year) {
year.className = "year-hdr expanded";
rows = year.parentNode.getElementsByTagName("DIV");
for(i=0; i < rows.length; i++)
rows[i].style.display = "block";
}
</script>
5. Define CSS styles. Here are my definitions:
.year-hdr {
cursor: pointer;
cursor:hand;
font-size: 120%;
font-weight: bold;
background-repeat: no-repeat;
background-position: top left;
padding:2px;
}
.collapsed {
background-image: url(images/plus.gif);
}
.expanded {
background-image: url(images/solid.gif);
}
.month-row {
display: none;
padding-left: 2em;
}
Done.
February 4, 2007
On embedding XSLT stylesheets into assemblies
 I was writing about loading XSLT stylesheets embedded into assemblies (dll or exe) recently and Richard Quinn asked this very legitimate question:
I was writing about loading XSLT stylesheets embedded into assemblies (dll or exe) recently and Richard Quinn asked this very legitimate question:
But why oh why would anyone embed their XSLT in the assembly? The point is to separate design from logic. Even if the xslt does a non-presentational transform it _will_ be a pain to have to redeploy the assembly instead of just the stylesheet. Or not?
Well, having XSLT stylesheets externally no doubt has many benefits. But embedding XSLT stylesheets into deploy units (be it dll, exe or jar) is also done not without a reason. After all two the most often used in the wild XSLT stylesheets are embedded. I'm talking about res://msxml.dll/defaultss.xsl (technically not XSLT stylesheet) and chrome://global/content/xml/XMLPrettyPrint.xsl - respectively Internet Explorer and Firefox XML pretty printers.
Embedding stylesheet doesn't necessarily mean coupling presentation and logic layers, in fact it has nothing to do with any application design issues. It's just deployment strategy and in that sense XSLT stylesheets aren't different from images or scripts.
Sure, when your XSLT file is just laying around you can tweak it without reinstalling application (sometimes even without restarting it). Sometimes that's useful and sometimes you don't want users to play with your stylesheet, because allowing that means:
- more code to write - you have to anticipate possible stylesheet changes, corruption or removal
- more testing
- potential security hole, because don't forget XSLT is a programming language and if that's not enough it can include extensions so that enables lots of interesting code injection scenarios for black hats. Sure with .NET 2.0 XSLT security options you can limit what XSLT stylesheet can perform, but then - it's your stylesheet and you are limiting yourself in the first place.
Again, sometimes deployment is easier if you don't have to bother about all that little files to be placed into the right place.
Some people embed, obfuscate and encrypt XSLT stylesheets trying to prevent reverse engineering. Well, apparently they do it for a reason too.
Performance is another interesting point. I think loading string resources should be a little bit faster than loading from the disk. Didn't test it though.
But the whole new era of XSLT embedding is going to start when XSLT finally becomes widely compilable into executable code. Next Visual Studio (codename Orcas, expected later this year) will include XSLTC.EXE - XSLT to MSIL compiler. That would add another benefit - save on XSLT compilation, which is time and resource hog.
If you do embed your XSLT stylesheets, I wonder what are your reasons?
February 3, 2007
Building Category Cloud for MovableType
Here is a nice trick how to build category cloud for your MovableType blog. No plugins required, just past this snippet into your template.
<div class="side" id="CategoryCloud" style="line-height:1.6em;">
<MTCategories show_empty="0">
<a href="<$MTCategoryArchiveLink$>"
class="<$MTCategoryCount$>"><$MTCategoryLabel$></a>
</MTCategories>
<script type="text/javascript">
e = document.getElementById("CategoryCloud").getElementsByTagName("A");
for(i=0; i < e.length; i++)
{
if(e[i].className != "")
{
t = e[i].className;
if(t > 256) e[i].style.fontSize = "230%";
else if(t > 126) e[i].style.fontSize = "200%";
else if(t > 68) e[i].style.fontSize = "180%";
else if(t > 16) e[i].style.fontSize = "160%";
else if(t > 8) e[i].style.fontSize = "130%";
else if(t >= 2) e[i].style.fontSize = "110%";
else if(t = 1) { e[i].style.fontSize = "100%"; }
}
}
</div>
[Found here]
The idea is simple - generate list of categories with count of posts embedded into class attribute and then in browser scan categories and set font size according to any kind of cloud algorithm.





